使用 MinDiff 提升模型公平性
文 / Summer Misherghi 和 Thomas Greenspan
Google Research 软件工程师
去年 12 月,我们开源了 Fairness Indicators,这是一个能对机器学习模型性能进行切片评估的平台。这种负责任的评估是避免偏差至关重要的第一步,因为它能让我们确定模型如何助力各类用户。在确定我们的模型在某些数据切片上表现不佳后,根据 Google 的 AI 原则,我们需要一种策略来缓解这种情况带来的影响,以避免造成或强化不公平的偏差。
Google 的 AI 原则
https://ai.google/principles/
近日,我们推出了 MinDiff,这是一种解决机器学习模型中不公平的偏差的技术。给定两个数据切片,MinDiff 会根据两组数据之间得分分布的差异作为罚值来调教模型。模型在训练时则会尽可能使分布接近以最小化罚值。我们的模型修复技术库会不断发展壮大,而 MinDiff 是其中的首项技术,此库中的每项技术都适用于不同的用例。如需了解 MinDiff 背后的研究和理论,请参阅此文。
MinDiff
https://tensorflow.google.cn/responsible_ai/model_remediation/此文
https://ai.googleblog.com/2020/11/mitigating-unfair-bias-in-ml-models.html
MinDiff 演示
您可以在此 MinDiff Notebook 上操作并运行代码。在本演示中,我们会重点强调 Notebook 中的相关特性,同时提供关于公平性评估和修复的相关信息。
MinDiff Notebook
https://tensorflow.google.cn/responsible_ai/model_remediation/min_diff/tutorials/min_diff_keras
在本例中,我们将训练文本分类器来识别可能会被视为“恶意”的书面内容。对于此任务,我们会将 Civil Comments 数据集中预训练的简单 Keras 序列模型作为基线模型。由于此文本分类器可用来自动审核互联网论坛上的内容(例如,标记潜在的恶意评论),我们希望确保它对每个人都有效。您可以在这篇文章中了解在自动内容审核中公平性问题的相关内容。
Civil Comments
https://tensorflow.google.cn/datasets/catalog/civil_comments这篇文章
https://medium.com/the-false-positive/unintended-bias-and-names-of-frequently-targeted-groups-8e0b81f80a23
-
针对包含引用了敏感类别组的文本,评估我们的基线模型性能。 -
通过使用 MinDiff 训练模型,在任何表现不佳的组上提升性能。 -
根据我们所选的指标评估新模型的性能。
本演示的目的是尽可能用最简单的工作流演示 MinDiff 技术的使用情况,而不是为机器学习提供全面详尽的方法以解决公平性问题。我们的评估将只关注一个敏感类别和单个指标。我们不会解决数据集中的潜在缺陷,也不会调整我们的配置。
-
考虑模型的应用空间和潜在社会影响;不同类型的模型错误有什么影响? -
考虑表现不佳可能会影响公平性的其他类别。对于每个类别的组,您是否有足够的样本? -
考虑存储敏感类别对隐私权产生的任何影响。 -
考虑表现不佳可能转化为有害结果的任何指标。 -
对多个敏感类别的所有相关指标进行全面评估。 通过调整超参数对 MinDiff 的配置进行实验,以获得最佳性能。
为达到演示目的,我们将跳过构建和训练基线模型,而直接评估其性能。我们使用了一些实用函数来帮助我们计算指标,并已准备好将评估结果可视化(请参阅 Notebook 中的“渲染评估结果”部分):
widget_view.render_fairness_indicator(eval_result)
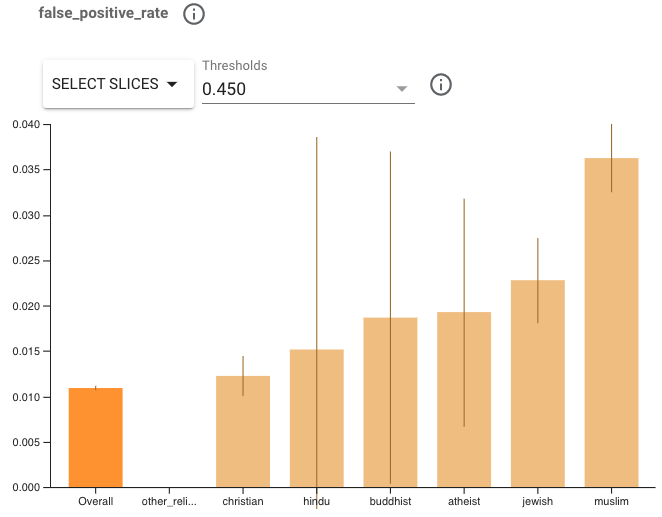
我们来看看评估结果。尝试选择假阳率 (FPR) 指标,并设置阈值为 0.450。我们可以看到,该模型对于某些宗教类别组的性能表现不如其他类别组,其显示的 FPR 更高。请注意,有些组的置信区间很宽,因为它们的样本太少。这样就很难肯定地说,模型在这些切片上的表现存在显著差异。我们可能需要收集更多的样本来解决这个问题。但是,我们可以尝试将 MinDiff 应用于性能表现确实不佳的两个组。
我们选择关注 FPR,因为较高的 FPR 意味着引用这些标识组的评论更有可能被错误地标记为恶意评论。对于参与宗教相关对话的用户而言,这可能会导致不公平的结果。但是请注意,其他指标的差异可能会导致其他类型的损害。
现在,我们将努力改善模型表现不佳的宗教组的 FPR。我们会尝试使用 MinDiff 来实现这一目标。MinDiff 是一种修复技术,通过惩罚训练过程中的性能差异来平衡数据切片之间的错误率。应用 MinDiff 时,其他切片的模型性能可能会略有下降。因此,我们使用 MinDiff 的目标是改善表现不佳的组的模型性能,同时保持其他组和整体的强大性能。
MinDiff
https://arxiv.org/abs/1910.11779
-
一个分块包含引用少数组的非恶意样本:在我们的例子中,这将包括引用表现不佳的识别术语的评论。由于样本太少,我们没有包含某些组,这导致了不确定性更高,置信区间范围较宽。 一个分块包含引用多数组的非恶意样本。
对于表现不佳类别,拥有足够数量的样本非常重要。根据模型架构、数据分布和 MinDiff 配置,所需的数据量可能大不相同。在以往的应用中,我们看到 MinDiff 在包含 5,000 个以上样本的数据分块中就可以很好地工作。
在我们的例子中,少数组分块的样本数量为 9,688 和 3,906。请注意数据集中的类别不平衡性;在实际应用中,这可能会引起问题,但我们不会试图在此 Notebook 中解决它们,因为我们的目的只是演示 MinDiff。
我们只会为这些组选择负样本,以便 MinDiff 可以优化这些样本,然后将其变为合适的样本。如果我们主要关注假阳率的差异, 那么划出真实的负样本集就可能不合常理, 但切记,假阳性预测是真实的负样本,却被错误地归类为正样本,这正是我们要努力解决的问题。
为了准备数据分块,我们为敏感组和非敏感组创建了掩码:
minority_mask = data_train.religion.apply(
lambda x: any(religion in x for religion in ('jewish', 'muslim')))
majority_mask = data_train.religion.apply(
lambda x: x == "['christian']")
接下来,我们要选择负样本,这样 MinDiff 便能够降低敏感组的 FPR:
true_negative_mask = data_train['toxicity'] == 0
data_train_main = copy.copy(data_train)
data_train_sensitive = (
data_train[minority_mask & true_negative_mask])
data_train_nonsensitive = (
data_train[majority_mask & true_negative_mask])
要开始使用 MinDiff 进行训练,我们需要将数据转换为 TensorFlow 数据集(此处未显示 -- 有关详细信息,请参阅 Notebook 中的“创建 MinDiff 数据集”部分)。请勿忘记对数据进行批处理,以进行训练。在我们的例子中,我们将批次大小设置为与原始数据集相同的值,这并不是必需操作,但在实际操作中应进行调整。
dataset_train_sensitive = dataset_train_sensitive.batch(BATCH_SIZE)
dataset_train_nonsensitive = (
dataset_train_nonsensitive.batch(BATCH_SIZE))
准备好三个数据集后,我们使用库中提供的 util 函数将它们合并为一个 MinDiff 数据集。
min_diff_dataset = md.keras.utils.pack_min_diff_data(
dataset_train_main,
dataset_train_sensitive,
dataset_train_nonsensitive)
util 函数
https://tensorflow.google.cn/responsible_ai/model_remediation/api_docs/python/model_remediation/min_diff/keras/utils/pack_min_diff_data
要使用 MinDiff 进行训练,只需使用相应的“loss”和“loss_weight”将原始模型封装在 MinDiffModel 中。我们使用 1.5 作为“loss_weight”的默认值,但这是一个需要针对您的用例进行调整的参数,因为它取决于您的模型和产品要求。您应该尝试更改此值,看看它会如何影响模型。增加该值会缩小少数组和多数组之间的表现差异,但可能会带来更明显的权衡。
如上所述,我们创建了一个原始模型,并将其封装在 MinDiffModel 中。我们传入一个 MinDiff 损失,并使用中等高的权重 1.5。
original_model = ... # Same structure as used for baseline model.
min_diff_loss = md.losses.MMDLoss()
min_diff_weight = 1.5
min_diff_model = md.keras.MinDiffModel(
original_model, min_diff_loss, min_diff_weight)
对原始模型进行封装后,我们照常编译模型。这意味着我们使用了与基线模型相同的损失:
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss = tf.keras.losses.BinaryCrossentropy()
min_diff_model.compile(
optimizer=optimizer, loss=loss, metrics=['accuracy'])
我们在 MinDiff 数据集上进行拟合训练,并保存了原始模型以进行评估(有关为什么不保存 MinDiff 模型的详细信息,请参阅 API 文档)。
min_diff_model.fit(min_diff_dataset, epochs=20)
min_diff_model.save_original_model(
min_diff_model_location, save_format='tf')
API 文档
https://tensorflow.google.cn/responsible_ai/model_remediation/api_docs/python/model_remediation/min_diff/keras/MinDiffModel.md#save_original_model
最后,我们对新的结果进行评估。
min_diff_eval_subdir = 'eval_results_min_diff'
min_diff_eval_result = util.get_eval_results(
min_diff_model_location, base_dir, min_diff_eval_subdir,
validate_tfrecord_file, slice_selection='religion')
为确保能正确地评估新模型,我们需要像选择基线模型一样选择一个阈值。在生产环境中,这意味着确保评估指标满足发布标准。在我们的例子中,我们将选择使总体 FPR 与基线模型 FPR 相似的阈值。此阈值可能与您为基线模型选择的阈值不同。您可以尝试选择阈值为 0.400 的假阳率(请注意,样本数量非常少的子组的置信区间范围很宽,并且没有可预测的结果)。
widget_view.render_fairness_indicator(min_diff_eval_result)
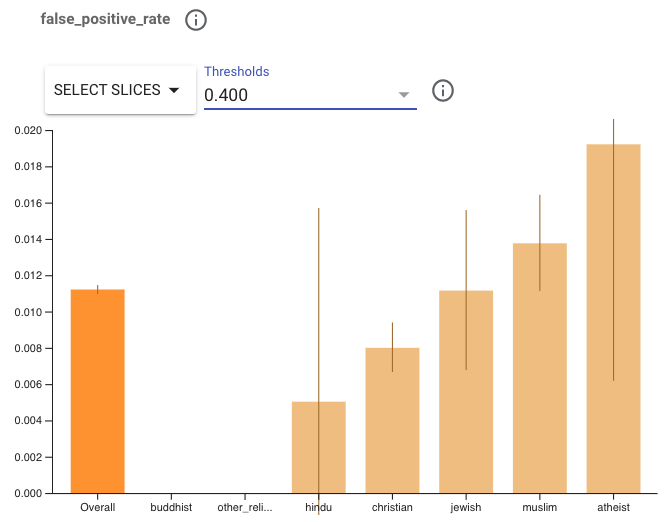
注意:Y 轴的比例已从基线模型图中的 .04 更改为 MinDiff 模型中的 .02
查看这些结果时,您可能会注意到目标组的 FPR 已有所改善。表现最差的组与大多数组之间的差距已从 .024 改善到 .006。鉴于我们观察到的改进和大多数组持续的强劲表现,我们已达到两个目标。根据产品的不同,我们可能需要进一步的改进。但这种方法可使我们的模型进一步提升,从而为所有用户提供公平体验。
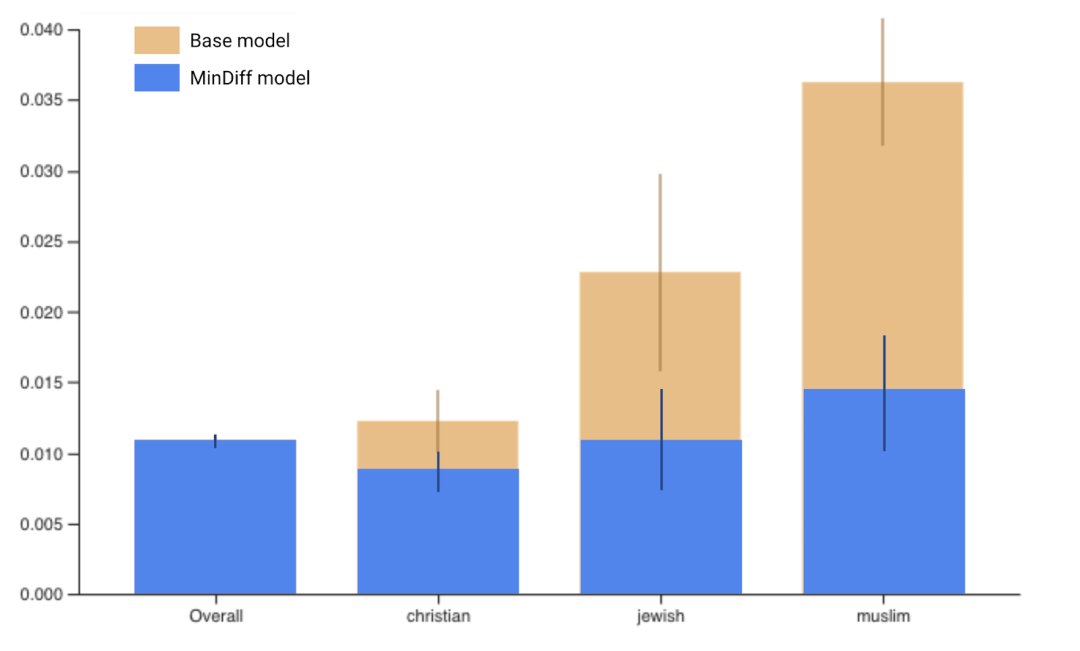
为了使比例的观感更好,我们将 MinDiff 模型叠加在基础模型之上
您可以通过访问 tensorflow.google.cn 上的 MinDiff 页面开始了解 MinDiff。有关 MinDiff 背后研究的更多信息,您可以参阅 Google AI 上的博文或在此指南中详细了解有关公平性评估的信息。
MinDiff 页面
https://tensorflow.google.cn/responsible_ai/model_remediation/Google AI 上的博文
https://ai.googleblog.com/2020/11/mitigating-unfair-bias-in-ml-models.html此指南
https://tensorflow.google.cn/responsible_ai/fairness_indicators/guide/guidance
致谢
MinDiff 框架由以下人员合作开发:Thomas Greenspan、Summer Misherghi、Sean O'Keefe、Christina Greer、Catherina Xu、Manasi Joshi、Dan Nanas、Nick Blumm、Jilin Chen、Zhe Zhao、James Chen、Maciej Kula、Lichan Hong、Mahesh Sathiamoorthy。此次关于分类中 ML 公平性的研究由以下人员共同领导(按字母顺序排列):Alex Beutel、Ed H. Chi、Flavien Prost、Hai Qian、Jilin Chen、Shuo Chen 和 Tulsee Doshi。此外,此项工作由以下人员合作开展:Christine Luu、Jonathan Bischof、Pierre Kreitmann 和 Qiuwen Chen。
— 推荐阅读 —



了解更多请点击 “阅读原文” 访问官网。




