模块化深度学习的递归原型
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:Badih Ghazi 和 Joshua R. Wang,Google Research 研究员
来源
经典机器学习 (ML) 大多专注于利用尽可能多的数据进行更准确的预测。近来,研究人员也在思考其他的重要目标,例如如何设计小型、高效且稳定的算法。围绕这些目标,如何在神经网络上设计一个能高效存储已编码信息的系统自然而然成为了研究目标。换言之,我们想设计出一套可展示深度网络如何处理与计算输入的信息的概述(“原型, sketch”)机制。原型构造 (Sketching) 研究领域的广泛可追溯到 Alon、Matias 和 Szegedy 的基础性工作,这种方法可以让神经网络更高效地汇总输入数据的相关信息。
注:Alon、Matias 和 Szegedy 的基础性工作
http://www.math.tau.ac.il/~nogaa/PDFS/amsz4.pdf
例如:想象一下你走进了一个房间,大概扫一眼屋里有哪些物体。现代机器学习非常善于回答即时提问 (immediate questions),即在训练阶段已知的场景问题,如:“屋子里有猫吗?这只猫有多大?”
现在,假设我们在过去一年中每一天都会检查这个房间。人们可以回忆起他们检查房间时的情形,并回答:“我们一般多久能看到一次猫?我们通常是在上午还是晚上看到它?(未被预先设定的问题,基于记忆内容的提问)”。所以,是否能设计一个能高效回答此类 基于记忆提问 的系统呢?
在近期于 ICML 2019 上推出的“模块化深度学习的递归原型 “Recursive Sketches for Modular Deep Learning”中,我们探讨了如何概述” 机器学习模型是如何理解输入的数据”。我们实现这一目的的方法是:使用现有已训练的机器学习模型通过计算“原型”来增强该模型,并应用于有效地回答基于记忆的提问(例如图片之间的相似性以及汇总一些特征),相较于存储整个原始计算过程,存储原型仅需占用较少的内存。
注:ICML 2019
https://icml.cc/Conferences/2019
模块化深度学习的递归原型
https://arxiv.org/abs/1905.12730
基础原型构造算法
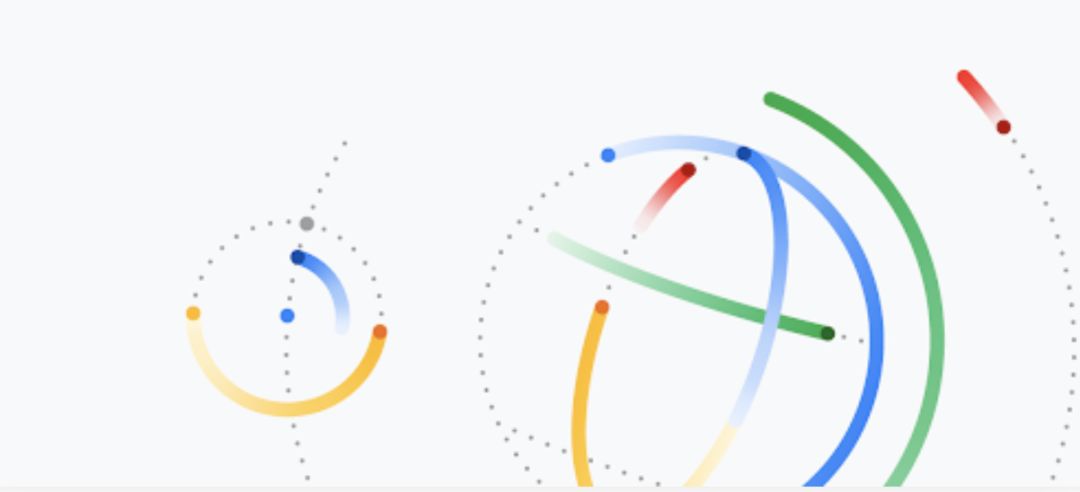
一般而言,原型构造算法是使用一个矢量 x, 并生成一个行为类似 x 的输出原型矢量,但后者的存储成本更低。更低的存储成本使得用户能够简洁地存储网络的信息,这对于高效回答基于记忆的提问来说至关重要。在最简单的情况下,通过矩阵矢量乘积 Ax 得到 线性 原型 x,其中 A 是 一个 泛矩阵(wide matrix),即列数与 x 的原始维度相同,而行数等于降低后的新维度。通过此类方法产生各类高效算法,适用于包含海量数据集的基础任务,如评估基础统计数据(例如直方图、分位数和四分位范围)、寻找高频项目(也称为“高频元素”)、评估不同元素(也称为 “支持大小 (support size)”)的数量以及范数和熵估计值计算的相关任务。
注:高效算法
http://db.cs.berkeley.edu/cs286/papers/synopses-fntdb2012.pdf
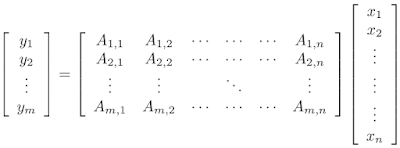
为矢量 x 构造原型的一个简单方法是将其乘以一个泛矩阵 A 来产生较低维度的矢量 y
在相对简单的线性回归案例中,这种基础方法表现良好,可以直接通过权重的量级识别重要数据维度(在具有一致方差的常见假设情况下)。然而,实际上现代机器学习模型大多是深度神经网络,并且基于高维度嵌入(例如 Word2Vec、Image Embeddings、Glove、DeepWalk 和 BERT),这使得在输入数据的基础上总结模型操作变得更加困难。然而,虽然这些子集本身很复杂,但这些更复杂的网络是由模块化构成的,因此,我们可以为其行为生成准确原型。
注:Image Embeddings
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41473.pdf
Glove
https://nlp.stanford.edu/pubs/glove.pdf
DeepWalk
https://arxiv.org/abs/1403.6652
BERT
https://arxiv.org/abs/1810.04805
神经网络模块化
模块化深度网络由若干独立神经网络(模块)组成,这些网络只通过上游网络输出作为下游网络输入的方式进行通信。受这一概念的启发设计出一些实际的架构,包括神经模块化网络(Neural Modular Networks)、胶囊神经网络(Capsule Neural Networks)和 PathNet。此外,用户还可以拆分其他经典架构并视为模块化网络,以应用我们的方法。例如,卷积神经网络 (CNN) 传统上被理解为是模块化的,这些网络会检测其底层中的基础概念并进行归类,并逐步检测其高层中更复杂的对象。从这个角度来看,卷积内核与模块相对应。下图为模块化网络的动画演示。
注:神经模块化网络
https://arxiv.org/abs/1511.02799
胶囊神经网络
http://papers.nips.cc/paper/1710-learning-to-parse-images.pdf
PathNet
https://arxiv.org/abs/1701.08734
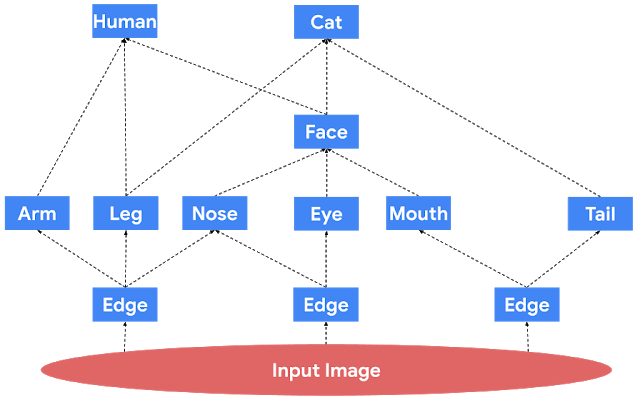
上图展示了图像处理的模块化网络。数据通过蓝色方框所表示的模块从底部传输到顶部。请注意,底层的模块对应于基础对象,如图像中的边缘,而上层的模块对应于较复杂的对象,如人类或猫。另外,在这个假设的模块化网络中,面部模块的输出是通用的,可用于人类和猫模块
原型构造要求
为了优化我们针对这些模块化网络的方法,我们的网络原型应当满足以下的若干特征:
原型之间的相关性:两个不相关网络操作(无论是针对当前模块还是针对属性矢量)的原型应当差异较大;相反,两个相关网络操作的原型应当非常接近。
属性恢复:属性矢量(例如图表的任意节点的激活)大致可以从顶级原型恢复。
特征统计:如果存在多个相似对象,我们可以恢复关于这些对象的特征统计。例如,一张图像中存在多只猫,我们可以计算猫的数量。请注意,我们希望在预先不知道问题的 前提下 执行这一操作。
正常移除:移除顶级原型的后缀可保留上述属性(但无疑会增加错误)。
网络恢复:若提供足够多的数据对(输入、原型),网络边缘的布线 (wiring) 以及原型功能大致可以恢复。
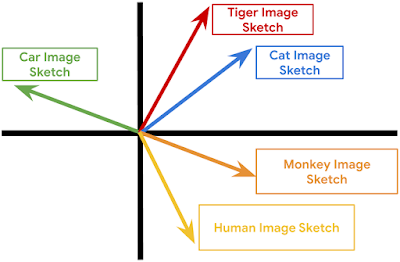
这是原型之间的相似性属性的 2D 动画演示。每个矢量代表一个原型,相关原型更可能归类在一起
原型构造机制
我们提出的原型构造机制可以应用于预训练的模块化网络。此机制可以构造 总结网络操作的 顶级单原型,并同时满足上述所有所需属性。如要了解该机制如何实现这一目的,最好先思考一个单层网络。对于单层网络,我们确保与特定节点相关的所有相关信息均“封装”在两个单独的子空间,一个子空间对应节点本身,另一个子空间对应其相关模块。借助适当的投影,第一个子空间允许我们 恢复节点的属性,而第二个子空间有利于 快速预测特征统计。两个子空间都有助于实施前文提到的 原型间的相似性 属性。我们证明:如果独立地随机选择所有相关子空间,则这些属性成立。
当然,将这一想法延伸至多层网络时需要格外注意,这也正是促使我们构思 递归原型构造 机制的原因。鉴于其递归性质,这些原型可以被“展开”,以便识别子成分,应用于更加复杂的网络结构。最后,我们为这一特定情景定制的字典学习算法,证明构成基于随机子空间的原型构造机制以及网络架构可以通过足够大量的数据(输入、原型)对予以恢复。
未来方向
概述网络的运作问题似乎与 模型的可解释性 密切相关。那么,继续探索原型构造的想法是否可应用于这一领域将是一件很有意思的事情。我们还可以在代码库中管理原型,以便形成一个所谓的“知识图谱”用于快速识别和检索。此外,我们的原型构造机制还可实现向原型代码库平滑添加新模块,探索此功能是否适用于 架构搜索 和日益发展的网络拓扑将会变得很有趣。最后,我们的原型可以管理基于记忆的已知问题的数据,例如,具有相同模块或属性的图像将具有相同的原型子成分。从更高的层次来看,此种方式与人类使用先验知识识别物体并将其应用于未知情况相类似。
注:模型的可解释性
https://ai.googleblog.com/2018/03/the-building-blocks-of-interpretability.html
架构搜索
https://ai.googleblog.com/2017/05/using-machine-learning-to-explore.html
致谢
本文为 Badih Ghazi、Rina Panigrahy 和 Joshua R. Wang 共同努力的成果。
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




