高效 PyTorch:6个Tips,为训练管道加涡轮增压

极市导读
本文为pytorch使用者给出了六条建议,让训练更快、更稳、更强。>>>极市CV侠侣正式出道!请大家前往文末为他们投票打call~
Efficient PyTorch — Supercharging Training Pipeline
作者:Eugene Khvedchenya
https://medium.com/@eugenekhvedchenya/efficient-pytorch-supercharging-training-pipeline-19a26265adae
每个深度学习项目的最终目标都是为产品带来价值。当然,我们希望有最好的模型。什么是“最好的”取决于具体的业务场景,不在本文讨论范围内。我想谈谈如何从 train.py 脚本中获得最大价值。
大纲
高级框架代替了自制的训练循环
使用额外的度量(metrics)监控训练的进度
使用 TensorBoard
可视化模型的预测
使用 Dict 作为数据集和模型的返回值
检测异常并解决数值不稳定问题
免责声明: 在下一节中,我将包括一些源代码清单。其中大多数都是为 Catalyst 框架(版本20.08)定制的,并且可以在 pytorch-toolbelt 中使用。
不要重新发明轮子

建议1 — 利用 PyTorch 生态中的高级训练框架
从头开始写训练循环的话, PyTorch 提供了极好的灵活性和自由度。理论上,这为编写任何训练逻辑提供了无限的可能性。实际上,你很少会为训练 CycleGAN、蒸馏 BERT 或者实现3D 目标检测从头开始编写新奇的训练循环。
从头开始编写一个完整的训练循环是学习 PyTorch 基础知识的一种极好的方法。然而,我强烈建议一旦掌握了一些知识,就切换到高级框架。有很多选择: Catalyst,PyTorch-Lightning,Fast.AI,Ignite 等等。高级库通过以下方式节省你的时间:
-
提供经过良好测试的训练循环 -
支持配置文件 -
支持多 GPU 和分布式训练 -
检查点/实验的管理 -
自动记录训练进度
从这些高级库中获得最大价值需要一些时间。然而,从长远来看,这种一次性投资是值得的。
优点
-
训练管道更小——代码更少——出现错误的可能性更小 -
实验管理更容易 -
简化分布式及混合精度训练
缺点
-
多一个抽象层——像往常一样,当使用高级框架时,我们必须在特定框架的设计原则和范式中编写代码 -
时间投资——学习额外的框架需要时间
给我展示度量

建议2ー在训练过程中查看额外的度量
几乎每一个快速上手的图像分类示例项目都有一个共同点,那就是它们在训练期间和训练后都报告了一组最小的度量。大多数情况下,它是Top-1和Top-5的准确率,错误率,训练/验证损失,就这么多。虽然这些度量是必不可少的,但只是冰山一角!
现代图像分类模型有数千万个参数。你想仅使用一个标量值来评估吗?
具有最佳 Top-1精度的 CNN 分类模型在泛化方面可能不是最佳分类模型。根据你的领域和需求,你可能希望保存假阳性/假阴性率最低的模型或平均精度最高的模型。
让我给你列举一些想法,在训练期间你可以记录哪些数据:
-
Grad-CAM 热图——查看图像的哪些部分对某一特定类别的贡献最大
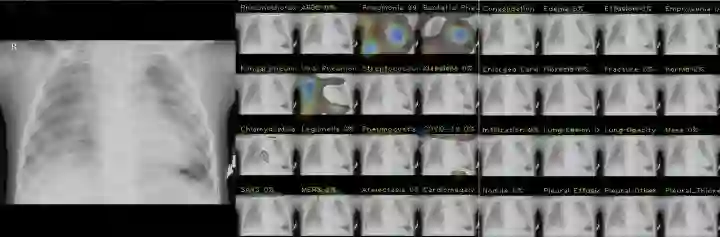
可视化 Grad-CAM 热图有助于确定模型做出预测是基于真实病理学还是基于图像artifacts
-
混淆矩阵——向你展示哪一对类别对你的模型来说最具挑战性
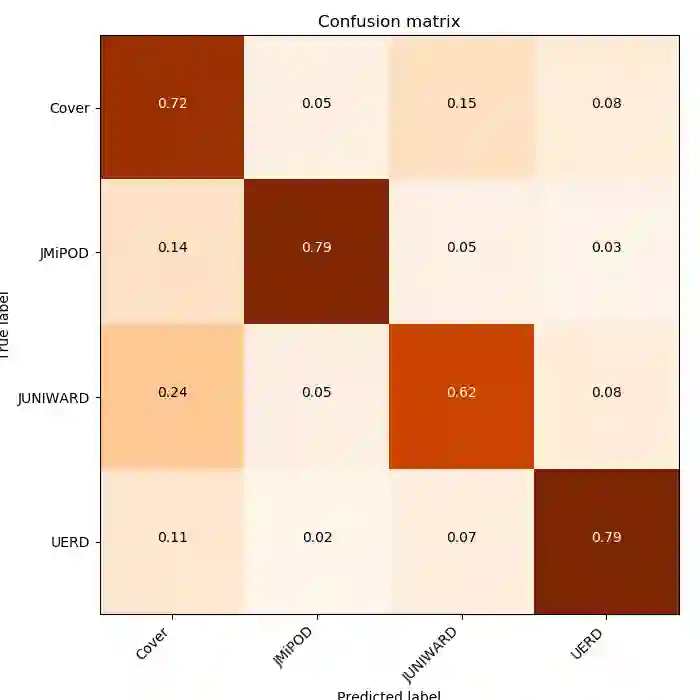
混淆矩阵揭示了模型对特定类型进行错误分类的频率(Eugene Khvedchenya,ALASKA2 Image Steganalysis,Kaggle)
-
预测的分布——给你关于最佳决策边界的洞察
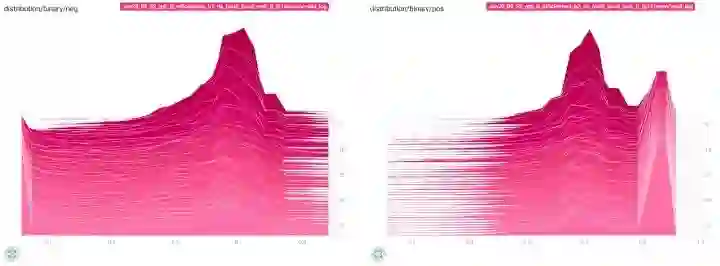
模型的负和正预测的分布情况表明,大部分数据模型不能有把握地进行分类(Eugene Khvedchenya,ALASKA2 Image Steganalysis,Kaggle)
-
所有层的梯度的最小/平均/最大值——可以确定模型中是否存在消失/爆炸梯度或初始化不佳的层
使用dashboard工具监控训练
建议3ー使用TensorBoard或任何其他解决方案来监测训练的进展
在训练模型时,你最不想做的事情可能就是查看控制台输出。一个强大的dashboard,你可以一次看到所有的度量,这是检查训练结果的一种更有效的方式。
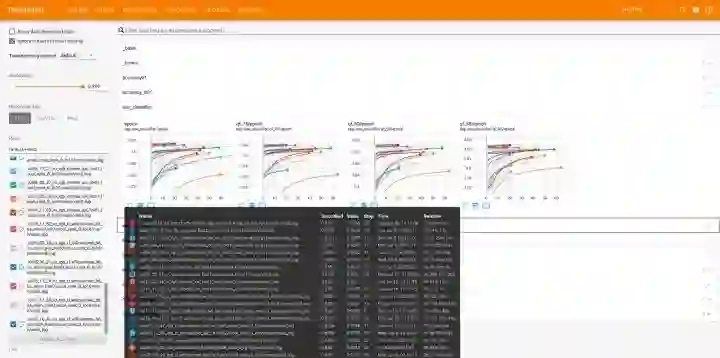
Tensorboard 可以本地快速检查和比较你的运行
对于少数实验和非分布式环境,TensorBoard 是一个黄金标准。从版本1.3开始,PyTorch 就完全支持它,并且提供了一系列丰富的特性来管理实验。还有更先进的基于云计算的解决方案,比如 Weights&Biases, Alchemy, 和 TensorBoard.dev,这使得在多台机器上监视和比较训练会话变得更加容易。
当使用 Tensorboard 时,我通常会记录一组度量:
-
学习率和其他可能会改变的优化器参数(动量,权重衰减等) -
花费在数据预处理和模型内部的时间 -
训练和验证的损失(每个批次和每个epoch平均) -
跨训练和验证的度量标准 -
最终度量值训练会话的超参数 -
混淆矩阵,精度-召回曲线,AUC (如果适用) -
模型预测的可视化(如果适用)
一图胜千言
看到模型的预测是非常重要的。有时候训练数据是有噪声的; 有时候,模型过拟合图像的artifacts。通过可视化最好和最差的批次(基于损失或你感兴趣的度量) ,你可以获得有价值的洞察,了解你的模型在哪些情况下表现得好,哪些情况下表现得差。
建议4ー把每个epoch最好和最差的批次可视化,它可以给你无价的洞察力
给 Catalyst 用户的Tip: 使用可视化回调的例子在这里: https://github.com/bloodaxe/Catalyst-inria-segmentation-Example/blob/master/fit_predict.py#l258
例如,在全球小麦检测挑战中,我们需要检测图像上的小麦穗。通过可视化最佳批次的图片(基于 mAP 度量) ,我们看到该模型在寻找小目标方面近乎完美。

最佳模型预测的可视化显示模型在小目标上表现良好(Eugene Khvedchenya,Global Wheat Detection,Kaggle)
相比之下,当我们看到最糟糕的一批的第一个样本时,我们看到这个模型很难对大型目标做出准确的预测。视觉分析为任何数据科学家提供了无价的洞察力。

可视化最差的模型预测揭示了模型在大目标上表现不佳(Eugene Khvedchenya,Global Wheat Detection,Kaggle)
查看最差的批次也有助于发现数据标签中的错误。通常情况下,有错误标签的样本有较大的损失,因此会出现在最坏的批次。通过在每个epoch对最差的批次进行视觉检查,你可以消除这些错误:

标记错误的例子。绿色像素表示真阳性,红色像素表示假阴性。在这个示例中,地面ground-truth掩码在该位置具有一个建筑足迹,而实际上在该位置没有建筑足迹。(Eugene Khvedchenya,Inria 航空图像标记数据集)
使用 Dict 作为数据集和模型的返回值
建议5ー如果你的模型返回一个以上的值ー使用 Dict 返回结果。不要使用 tuple。
在复杂模型中,返回多个输出并不罕见。例如,目标检测模型通常返回边界框和它们的标签,在图像分割 CNN 中,我们经常返回中间的mask用于深度监督,多任务学习现在也很流行。
在很多开源实现中,我经常看到这样的东西:
# Bad practice, don't return tupleclass RetinaNet(nn.Module):...def forward(self, image):x = self.encoder(image)x = self.decoder(x)bboxes, scores = self.head(x)return bboxes, scores...
出于对作者的尊重,我认为这是一个糟糕的、非常糟糕的从模型返回结果的方法。以下是我推荐的替代方法:
class RetinaNet(nn.Module):RETINA_NET_OUTPUT_BBOXES = "bboxes"RETINA_NET_OUTPUT_SCORES = "scores"...def forward(self, image):x = self.encoder(image)x = self.decoder(x)bboxes, scores = self.head(x)return { RETINA_NET_OUTPUT_BBOXES: bboxes,RETINA_NET_OUTPUT_SCORES: scores }...
这个建议在某种程度上与《 Python 之禅》(The Zen of Python)中的假设产生了共鸣——“明确的比隐含的好”。遵循这一规则将使你的代码更加清晰和易于维护。
那么,为什么我认为第二种选择更好呢? 原因如下:
-
返回值有一个与之关联的显式名称。你不需要记住元组中元素的确切顺序 -
如果需要访问返回字典的特定元素,可以通过它的名称来访问 -
从模型中添加新的输出不会破坏代码
使用 Dict,您甚至可以改变模型的行为,以根据需要返回额外的输出。例如,这里有一个简短的代码片段,演示了如何返回多个“ main”输出和两个用于度量学习的“辅助”输出:
# https://github.com/BloodAxe/Kaggle-2020-Alaska2/blob/master/alaska2/models/timm.py#L104def forward(self, **kwargs):x = kwargs[self.input_key]x = self.rgb_bn(x)x = self.encoder.forward_features(x)embedding = self.pool(x)result = {OUTPUT_PRED_MODIFICATION_FLAG: self.flag_classifier(self.drop(embedding)),OUTPUT_PRED_MODIFICATION_TYPE: self.type_classifier(self.drop(embedding)),}if self.need_embedding:result[OUTPUT_PRED_EMBEDDING] = embeddingif self.arc_margin is not None:result[OUTPUT_PRED_EMBEDDING_ARC_MARGIN] = self.arc_margin(embedding)return result
同样的建议也适用于 Dataset 类。对于 Cifar-10玩具示例,可以将图像及其对应的标签返回为 tuple。但是在处理多任务或多输入模型时,你希望以 Dict 类型返回数据集中的样本:
# https://github.com/BloodAxe/Kaggle-2020-Alaska2/blob/master/alaska2/dataset.py#L373class TrainingValidationDataset(Dataset):def __init__(self,images: Union[List, np.ndarray],targets: Optional[Union[List, np.ndarray]],quality: Union[List, np.ndarray],bits: Optional[Union[List, np.ndarray]],transform: Union[A.Compose, A.BasicTransform],features: List[str],):""":param obliterate - Augmentation that destroys embedding."""if targets is not None:if len(images) != len(targets):raise ValueError(f"Size of images and targets does not match: {len(images)} {len(targets)}")self.images = imagesself.targets = targetsself.transform = transformself.features = featuresself.quality = qualityself.bits = bitsdef __len__(self):return len(self.images)def __repr__(self):return f"TrainingValidationDataset(len={len(self)}, targets_hist={np.bincount(self.targets)}, qf={np.bincount(self.quality)}, features={self.features})"def __getitem__(self, index):image_fname = self.images[index]try:image = cv2.imread(image_fname)if image is None:raise FileNotFoundError(image_fname)except Exception as e:print("Cannot read image ", image_fname, "at index", index)print(e)qf = self.quality[index]data = {}data["image"] = imagedata.update(compute_features(image, image_fname, self.features))data = self.transform(**data)sample = {INPUT_IMAGE_ID_KEY: os.path.basename(self.images[index]), INPUT_IMAGE_QF_KEY: int(qf)}if self.bits is not None:# OKsample[INPUT_TRUE_PAYLOAD_BITS] = torch.tensor(self.bits[index], dtype=torch.float32)if self.targets is not None:target = int(self.targets[index])sample[INPUT_TRUE_MODIFICATION_TYPE] = targetsample[INPUT_TRUE_MODIFICATION_FLAG] = torch.tensor([target > 0]).float()for key, value in data.items():if key in self.features:sample[key] = tensor_from_rgb_image(value)return sample
当你的代码中有字典时,你可以到处使用名字常量引用输入/输出。遵循这条规则将使你的训练流程非常清晰和易读:
# https://github.com/BloodAxe/Kaggle-2020-Alaska2callbacks += [CriterionCallback(input_key=INPUT_TRUE_MODIFICATION_FLAG,output_key=OUTPUT_PRED_MODIFICATION_FLAG,criterion_key="bce"),CriterionCallback(input_key=INPUT_TRUE_MODIFICATION_TYPE,output_key=OUTPUT_PRED_MODIFICATION_TYPE,criterion_key="ce"),CompetitionMetricCallback(input_key=INPUT_TRUE_MODIFICATION_FLAG,output_key=OUTPUT_PRED_MODIFICATION_FLAG,prefix="auc",output_activation=binary_logits_to_probas,class_names=class_names,),OutputDistributionCallback(input_key=INPUT_TRUE_MODIFICATION_FLAG,output_key=OUTPUT_PRED_MODIFICATION_FLAG,output_activation=binary_logits_to_probas,prefix="distribution/binary",),BestMetricCheckpointCallback(target_metric="auc",target_metric_minimize=False,save_n_best=3),]
检测训练中的异常

建议6ー在训练过程中使用torch.autograd.detect_anomaly()来发现算术异常。
如果你在训练期间看到任何的 NaNs 或 Inf 的损失/度量,一个警报应该在你的头脑中响起。这是一个指示器,说明你的管道出了问题。通常,它可能是由以下原因引起的:
torch.sqrt()
应用在负数上,
torch.log()
非正等等)
torch.mean()
和
torch.sum()
reduction 的错误使用(零大小张量上的均值会导致nan,大张量上的和容易导致溢出)
x.sigmoid()
不谨慎 (如果你损失函数需要计算概率,一个更好的方法是
x.sigmoid().clamp(eps,1-eps
或
torch.logsigmoid(x).exp()
,可避免梯度消失)
为了查找代码中 Nan/Inf 第一次出现的确切位置,PyTorch 提供了一个易于使用的方法 torch.autograd.detect _ anomaly () :
仅用于调试目的,平时要禁用它,因为异常检测会带来额外的计算开销,训练循环会变慢10-15% 左右。
结语
谢谢阅读!我希望你喜欢它,并从中发现了一些可以用得上的东西。你想分享什么tips和tricks吗?请在评论中写下你的知识,或者让我知道大家对哪些 PyTorch 相关的话题感兴趣~
推荐阅读
极市征集了大家关于陪伴的故事
投票通道现已开启
快来为你喜爱的TA加油吧!
极市平台公众号回复“七夕”即可获取投票链接
每人每天有3次投票机会哦~

目前,活动还在进行中
大家可添加极小东微信(ID:cvmart3)投稿~

△ 扫码添加极小东微信








