【深度】OpenAI详细解析:攻击者是如何使用「对抗样本」攻击机器学习的

原文来源:OpenAI
作者: Ian Goodfellow、Nicolas Papernot、Sandy Huang、Yan Duan、Pieter Abbeel、Jack Clark.
来源:雷克世界
导语:一般来说,对抗样本(adversarial examples)是机器学习模型的输入,攻击者故意设计它们以引起模型出错;它们就像是机器的视觉错觉。这篇文章中,将展示对抗样本是如何在不同的媒介上发挥作用的,并将讨论为什么保护系统很难对抗它们。
在OpenAI中,我们认为对抗样本是安全工作的一个很好的方面。因为它们代表了人工智能安全中的一个具体问题,而它们可以在短期内得以解决。而且由于修复它们非常困难,需要进行认真的研究工作(尽管我们需要探索机器学习安全的许多方面,以实现我们构建安全、广泛分布的人工智能的目标)。
想要了解对抗样本看起来是什么样的,请参考《解释和利用对抗样本》(Explaining and Harnessing Adversarial Examples)中的阐释:从一张熊猫的图像开始,攻击者添加一个小干扰,且该小干扰被计算出来,使图像被认为是一个具有高置信度的长臂猿。

覆盖在典型图像上的对抗输入会导致分类器将熊猫误归类为长臂猿
这种方法相当具有鲁棒性;最近的研究表明,对抗样本可以在标准纸张上打印出来,然后用标准智能手机拍摄,而且用的仍然是傻瓜系统。

对抗样本可以在标准纸张上打印出来并用标准分辨率的智能手机拍照,并且在这种情况下仍然会导致分类器将“洗衣机”标记为“安全”
对抗样本是有潜在危险性的。例如,攻击者可以通过这种方法攻击自动驾驶汽车:使用贴纸或涂料创建一个对抗性的停车标志,让车辆将其解释为“屈服”或其他标志,就像《使用对抗样本对深度学习系统进行实用黑盒攻击》(Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples)中所述的那样。
加州大学伯克利分校、OpenAI和宾夕法尼亚州立大学的新研究《对神经网络策略的对抗性攻击》(Adversarial Attacks on Neural Network Policies)以及内华达大学雷诺分校的研究《深度强化学习对策略诱导攻击的脆弱性》(Vulnerability of Deep Reinforcement Learning to Policy Induction Attacks)表明,强化学习智能体也可以被对抗样本操纵。研究表明,诸如DQN、TRPO和A3C等这些广泛使用的RL算法,很容易受到对抗输入的影响。即使是在所存在的干扰微小到人类无法察觉,这些也会导致性能下降,使智能体在应该将乒乓球拍向上移动的时候将它向下移动了,或者使其在Seaquest中发现对手的能力受到了干扰。
如果你想尝试打破你自己的模型,你可以使用cleverhans,这是一个由Ian Goodfellow和Nicolas Papernot共同开发的开源库,用来测试你的AI对对抗样本的漏洞。
对抗样本让我们在人工智能安全方面有了一些动力
当我们思考人工智能安全的研究时,我们通常会想到这个领域中最困难的一些问题——我们如何确保那些比人类聪明得多的复杂的强化学习智能体能够以它们的设计者所期望的方式行事?
对抗样本告诉我们,对于监督和强化学习而言,即使是简单的现代算法,也已经可能以并非我们所想的令人惊讶的方式表现出来。
防御对抗样本所做出过的尝试
如权值衰减(weight decay)和dropout等这种使机器学习模型更具有鲁棒性的传统技术,通常不能为对抗样本提供实际的防御。到目前为止,只有两种方法提供了重要的防御。
对抗性训练:这是一种暴力破解(brute force)的解决方案。其中,我们只是简单地生成很多对抗样本,并明确训练模型不会被它们中的任何一个愚弄。对抗性训练的开源实现可以在cleverhans库中找到,下面的教程对其用法在进行了说明。
防御性精炼:这是一种策略。我们训练模型来输出不同类的概率,而不是将哪个类输出的艰难决策。概率由早期的模型提供,该模型使用硬分类标签在相同的任务上进行训练。这就创建了一个模型,其表面在攻击者通常会试图开拓的方向上是平滑的,从而使它们难以发现导致错误分类的对抗输入调整(精炼(Distillation)最初是在《神经网络中知识的精炼》(Distilling the Knowledge in a Neural Network)中作为模型压缩的一种技术而被引入的,在这种技术中,一个小模型被训练以模仿一个大模型,以便节省计算量)。
然而,即使是这些专门的算法,也可能被拥有了更多计算火力的攻击者轻易破解。
失败的防御:“梯度掩码”(gradient masking)
举一个简单防御失败的例子,让我们考虑一下为什么一种叫做“梯度掩码”的技术不起作用。
“梯度掩码”是一个在《使用对抗样本对深度学习系统进行实用黑盒攻击》(Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples)中所引入的术语,用于描述一整套失败的防御方法——它们试图阻止攻击者访问一个有用的梯度。
大多数对抗样本构造技术使用模型的梯度来进行攻击。换句话说,它们看一张飞机的图片,它们对图片空间进行测试,以发现哪个方向使“猫”类的概率增加,然后它们给予这个方向一点推动力(换句话说,它们扰乱输入)。这张新的、修改后的图像被错误地认为是一只猫。
但是如果没有梯度,如果对图像进行一个无穷小的修改会导致模型的输出没有变化,那该怎么办?这似乎提供了一些防御,因为攻击者不知道是向哪个方向“助推”图像。
我们可以很容易地想象一些非常简单的方法来摆脱梯度。例如,大多数图像分类模型可以在两种模式下运行:一种模式是只输出最可能的类的标识,另一种模式是输出概率。如果模型的输出是“99.9%的可能是飞机,0.1%的可能是猫”,那么对输入的微小改变会给输出带来很小的变化,而且梯度告诉我们哪个变化会增加“猫”类的概率。如果我们在输出只是“飞机”的模式下运行模型,那么对输入的微小改变就完全不会改变输出,而且梯度不会告诉我们任何东西。
让我们进行一个思考实验,看看我们在“最可能的类”模式下,而不是“概率模式”下,能够以怎样的程度来保护我们的模型抵抗对抗样本。攻击者不再知道去哪里寻找那些将被归类为猫的输入,所以我们可能有了一些防御。不幸的是,之前被归类为猫的每张图像现在仍然被归类为猫。如果攻击者能够猜测哪些点是对抗样本,那么这些点仍然会被错误分类。我们还没有使这个模型更具鲁棒性;我们刚刚给了攻击者更少的线索来找出模型防御漏洞的位置。
更不幸的是,事实证明,攻击者有一个非常好的策略来猜测防守漏洞的位置。攻击者可以训练出自己的一种具有梯度的平滑模型来为它们的模型提供对抗样本,然后将这些对抗样本配置到我们的非平滑模型上。很多时候,我们的模型也会对这些样本进行错误的分类。最后,我们的思考实验表明,隐藏梯度并没有给我们带来任何帮助。
执行梯度掩码的防御策略通常会导致一个模型在特定的方向和训练点的附近非常平滑,这使得攻击者很难找到指示好候选方向的梯度,从而以损害模型的方式干扰输入。然而,攻击者可以训练一种替代模型:一种通过观察被防御模型分配给攻击者精心选择的输入的标签来模仿防御模型的副本。
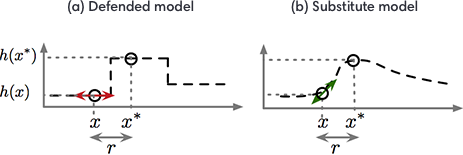
在“黑箱攻击”论文中引入了执行这种模型提取攻击的过程。然后,攻击者还可以使用替代模型的梯度来找到被防御模型错误分类的对抗样本。在上图中,对从《机器学习中的安全和隐私科学》(Towards the Science of Security and Privacy in Machine Learning)中找到的梯度掩码的讨论再现,我们用一维的ML问题来说明这种攻击策略。对于更高维度的问题,梯度掩码现象将会加剧,但难以描述。
我们发现,对抗性训练和防御性精炼都意外地执行了一种梯度掩码。这两种算法都没有明确地被设计来执行梯度掩码,但是当算法被训练来保护自己并且没有给出具体的指令时,梯度掩码显然是一种机器学习算法可以相对容易地发明出的防御措施。如果我们将对抗样本从一个模型迁移到另一个用对抗性训练或防御性精炼训练过的模型,攻击通常也会成功,即使对第二个模型直接的攻击失败了。这表明,这两种训练技术都会做更多的工作来使模型平滑并消除梯度,而不是确保它能够正确地对更多的点进行分类。
为什么很难防御对抗样本
难以防御对抗样本,因为难以构建一个对抗样本制作过程的理论模型。对于包括神经网络在内的许多ML模型来说,对抗样本是对非线性和非凸性的优化问题的解决方案。因为我们没有很好的理论工具来描述这些复杂的优化问题的解决方案,所以很难做出任何理论上的论证来证明一个防御系统会排除一系列对抗样本。
难以防御对抗样本,还因为它们要求机器学习模型为每一个可能的输入产生良好的输出。大多数情况下,机器学习模型运行得很好,但所能处理的只是它们可能遇到的所有可能输入中的很小一部分。
我们迄今为止测试的每一种策略都失败了,因为它不是自适应的:它可能会阻止一种攻击,但是留给攻击者另一个漏洞,而攻击者知道此次所使用的防御。设计一种可以防御强大的、自适应的攻击者的防御系统是一个重要的研究领域。
结论
对抗样本表明,许多现代机器学习算法可以以多种令人惊讶的方式被打破。机器学习的这些失败表明,即使是简单的算法也能与其设计者的意图截然不同。我们鼓励机器学习研究人员参与进来并设计防范对抗样本的方法,以缩小设计师意图和算法行为之间的差距。
原文链接:https://blog.openai.com/adversarial-example-research/
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【学界】CVPR2018 | 海康、UCLA、北理联合提出3D DescriptorNet:可按条件生成3D形状,克服模式崩溃
☞【深度】Yoshua Bengio团队通过在网络「隐藏空间」中使用降噪器以提高深度神经网络的「鲁棒性」




