深度知识追踪入门

背景介绍
知识追踪(Knowledge Tracing)是根据学生过去的答题情况对学生的知识掌握情况进行建模,从而得到学生当前知识状态表示的一种技术,早期的知识追踪模型都是依赖于一阶马尔科夫模型,例如贝叶斯知识追踪(Bayesian Knowledge Tracing)。将深度学习的方法引入知识追踪最早出现于发表在NeurIPS 2015上的一篇论文《Deep Knowledge Tracing》,作者来自斯坦福大学。在这篇论文中,作者提出了使用深度知识追踪(Deep Knowledge Tracing)的概念,利用RNN对学生的学习情况进行建模,之后引出了一系列工作,2019年已经有使用Transformer代替RNN和LSTM并且达到了SOTA的论文。
由于深度学习并不需要人类教会模型不同题目的难易、考核内容等特定的知识,避免了大量的手工标注特征工作量,而且在互联网在线教育行业兴起后,拥有了海量的学生答题记录,这些答题记录就能教会模型将题库中成千上万条题目encode为一个向量,并且能类似于word2vec那样找出题目之间的关联。因此之后各种AI+教育、个性化、智能化教育的概念也火了起来。不过截止目前深度知识追踪仍然只是一个小领域,业界应该是做了不少工作的,但因为每个公司教育数据的私密性,不同公司数据的多样性,导致了数据集不公开,方法也大多不通用的情况,因此我们并不太能了解到那些在线教育巨头背后的AI技术,至于学界,论文大多发表在教育数据挖掘国际会议上(Educational Data Mining)。本文简单介绍深度知识追踪,给有兴趣入门的同学的作参考。
任务定义
模型
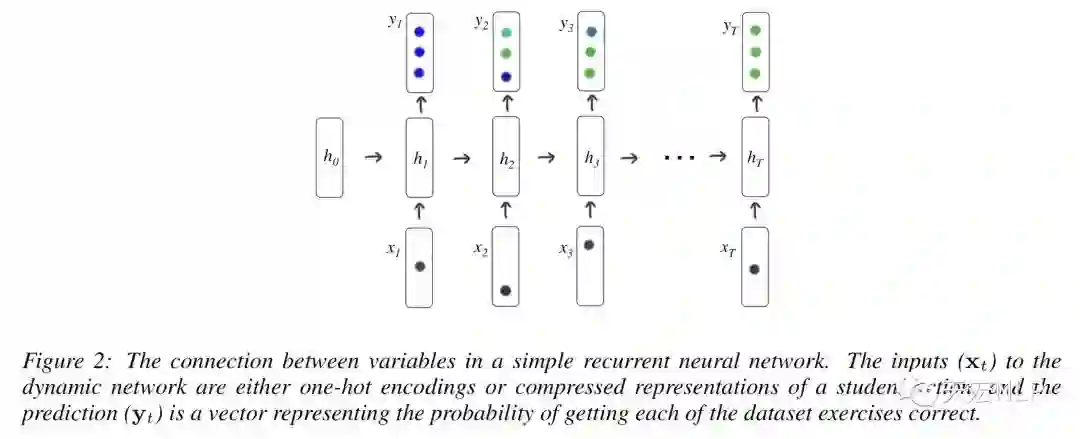
模型的输入和输出
Optimization
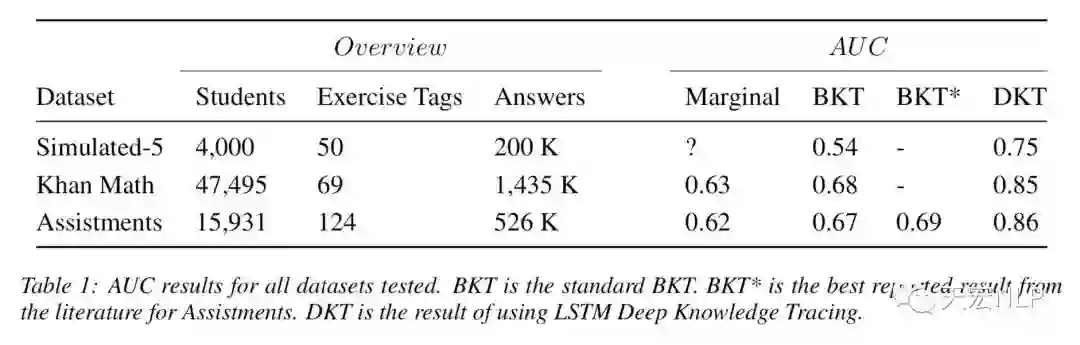
实验结果
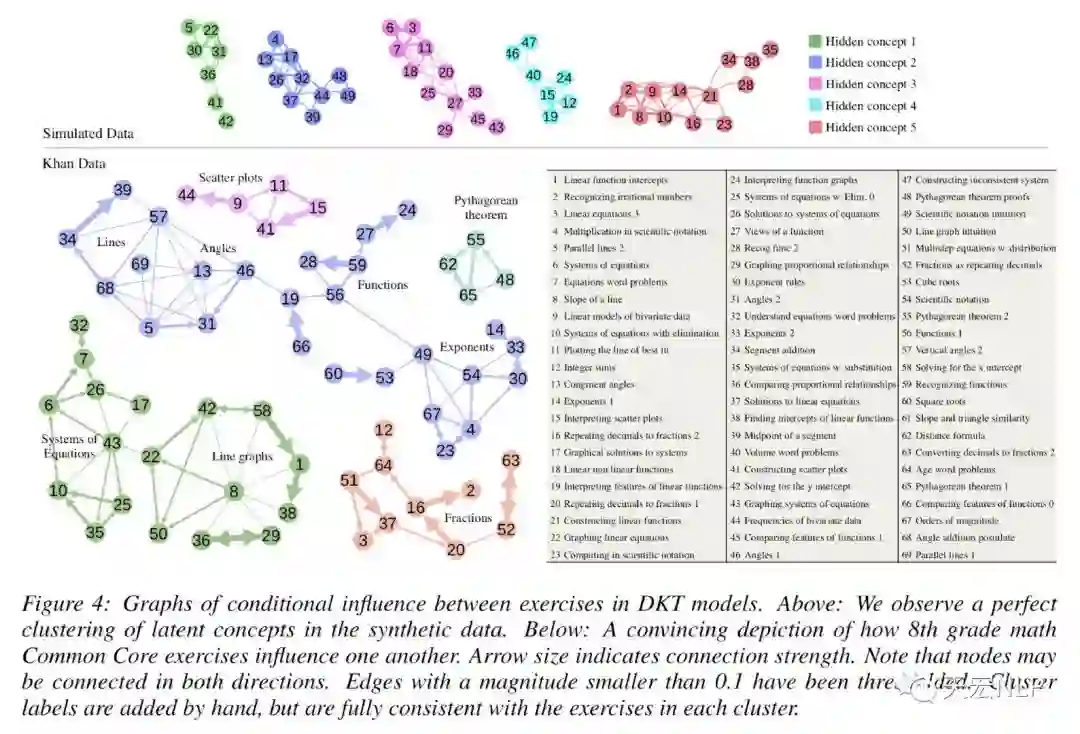
优缺点
优点
-
能根据学生最近的答题情况记录较长时间的知识情况。 -
能根据每次答题更新知识状态,只需要保存上一个隐层状态,不需要重复计算,适合线上部署。 -
不需要domain specific的知识,对任何用户答题数据集都适用。 -
能够自动捕捉相似题目之间的关联。
-
当答题序列被打乱时,模型输出的结果波动大,即相同的题目和相同的回答,当答题顺序不一致时,得到的知识状态不同。 -
由于上述问题,且学生在答题过程中对知识的掌握程度不一定具有连续一致性,导致对学生知识状态的预测受顺序影响发生偏差。 -
黑盒,有时会出现第一题答对导致对之后的预测概率都偏高,而第一题答错对之后的预测概率都偏低的奇怪情况。
总结
-
How Deep is Knowledge Tracing? -
Going Deeper with Deep Knowledge Tracing -
Incorporating Rich Features into Deep Knowledge Tracing -
Addressing Two Problems in Deep Knowledge Tracing via Prediction-Consistent Regularization -
A Self-Attentive model for Knowledge Tracing
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
深度学习如何入门?这本“蒲公英书”再适合不过了!豆瓣评分9.5!【文末双彩蛋!】
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





