超越BN和GN!谷歌提出新的归一化层:FRN
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
【前 言】目前主流的深度学习模型都会采用BN层(Batch Normalization)来加速模型训练以及提升模型效果,对于CNN模型,BN层已经上成为了标配。但是BN层在训练过程中需要在batch上计算中间统计量,这使得BN层严重依赖batch,造成训练和测试的不一致性,当训练batch size较小,往往会恶化性能。GN(Group Normalization)通过将特征在channel维度分组来解决这一问题,GN在batch size不同时性能是一致的,但对于大batch size,GN仍然难以匹敌BN。这里我们要介绍的是谷歌提出的一种新的归一化方法FRN,和GN一样不依赖batch,但是性能却优于BN和GN
从BN到GN
机器学习最重要的任务,是根据一些已观察到的证据(例如训练样本)来对感兴趣的未知变量(例如类别标记)进行估计和推测。概率模型(probabilistic model)提供了一种描述框架,将学习任务归结于计算变量
训练数据进行归一化处理有助于模型的优化,对于深度模型来说,归一化中间特征同样有助于训练,BN层就是最常用的归一化方法。BN层通过计算batch中所有样本的每个channel上的均值和方差来进行归一化,其计算方式如下所示:

以CNN模型为例,中间特征的维度为[B, H, W, C],BN首先在计算在(N H, W)维度上的均值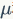
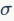
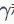
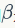
BN的一个问题是训练时batch size一般较大,但是测试时batch size一般为1,而均值和方差的计算依赖batch,这将导致训练和测试不一致。BN的解决方案是在训练时估计一个均值和方差量来作为测试时的归一化参数,一般对每次mini-batch的均值和方差进行指数加权平均来得到这个量。虽然解决了训练和测试的不一致性,但是BN对于batch size比较敏感,当batch size较小时,模型性能会明显恶化。对于一个比较大的模型,由于显存限制,batch size难以很大,比如目标检测模型,这时候BN层可能会成为一种限制。
解决BN上述问题的另外一个方向是避免在batch维度进行归一化,这样当然就不会带来训练和测试的不一致性问题。这些方法包括Layer Normalization (LN),Instance Normalization (IN)以及最新的Group Normalization(GN),这些方法与BN的区别可以从图1中看出来:
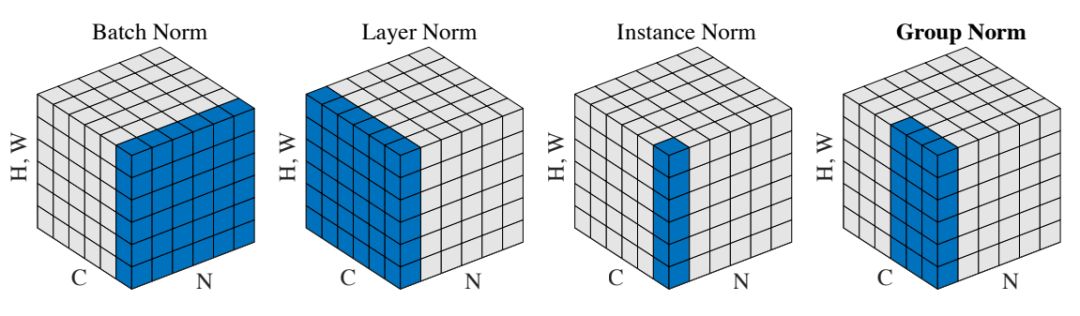
图1 不同的归一化方法对比
这些方法处理方式和BN类似,但是归一化的维度不一样,BN是在(N, H, W)维度上,LN是在(H,W,C)维度上,IN是在(H,W)维度上,GN更巧妙,其通过对C分组,此时特征可以从[N, H, W, C]变成[N, H, W, G, C/G],GN的计算是在[H, W, G]维度上。LN,IN以及GN都没有在B维度上进行归一化,所以不会有BN的问题。相比之下,GN是更常用的,GN和BN的效果对比如图2所示:
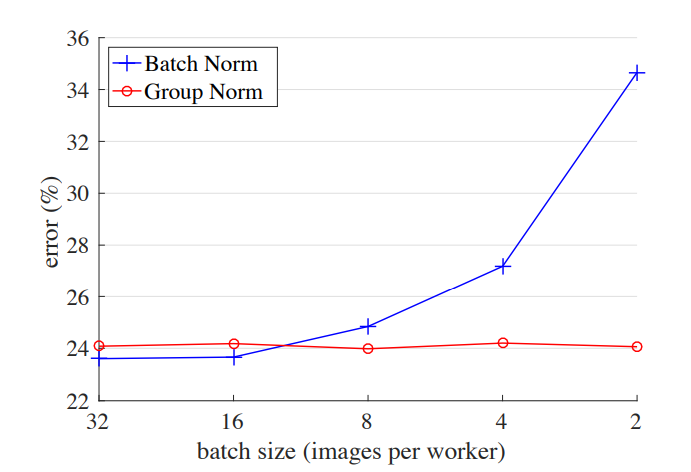
图2 ResNet50模型采用BN和GN在ImageNet上不同batch size下的性能差异
从图中可以看到GN基本不受batch size的影响,而BN在batch size较小时性能大幅度恶化,但是在较大batch size,BN的效果是稍好于GN的。
解决BN在小batch性能较差的另外一个方向是直接降低训练和测试之间不一致性,比较常用的方法是Batch Renormalization (BR),它主要的思路是限制训练过程中batch统计量的值范围。另外的一个解决办法是采用多卡BN方法训练,相当于增大batch size。
FRN
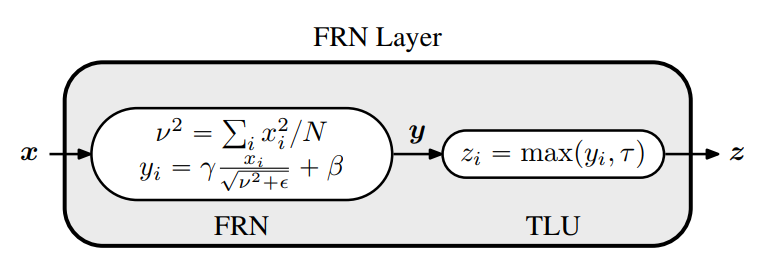
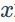 就是一个N维度(HxW)的向量,所以FRN没有BN层对batch依赖的问题。BN层采用归一化方法是减去均值然后除以标准差,而FRN却不同,这里没有减去均值操作,公式中的
就是一个N维度(HxW)的向量,所以FRN没有BN层对batch依赖的问题。BN层采用归一化方法是减去均值然后除以标准差,而FRN却不同,这里没有减去均值操作,公式中的
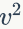 是
是
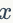 的二次范数的平均值。这种归一化方式类似BN可以用来消除中间操作(卷积和非线性激活)带来的尺度问题,有助于模型训练。
的二次范数的平均值。这种归一化方式类似BN可以用来消除中间操作(卷积和非线性激活)带来的尺度问题,有助于模型训练。
 是一个很小的正常量,以防止除0。FRN是在H,W两个维度上归一化,一般情况下网络的特征图大小N=HxW较大,但是有时候可能会出现1x1的情况,比如InceptionV3和VGG网络,此时
就比较关键,图4给出了当N=1时不同
下归一化的结果。当
值较小时,归一化相当于一个符号函数(sign function),这时候梯度几乎为0,严重影响模型训练;当值较大时,曲线变得更圆滑,此时的梯度利于模型学习。对于这种情况,论文建议采用一个可学习的
。对于不含有1x1特征的模型,论文中采用的是一个常量值1e-6。值得说明的是IN也是在H,W维度上进行归一化,但是会减去均值,对于N=1的情况归一化的结果是0,但FRN可以避免这个问题。
是一个很小的正常量,以防止除0。FRN是在H,W两个维度上归一化,一般情况下网络的特征图大小N=HxW较大,但是有时候可能会出现1x1的情况,比如InceptionV3和VGG网络,此时
就比较关键,图4给出了当N=1时不同
下归一化的结果。当
值较小时,归一化相当于一个符号函数(sign function),这时候梯度几乎为0,严重影响模型训练;当值较大时,曲线变得更圆滑,此时的梯度利于模型学习。对于这种情况,论文建议采用一个可学习的
。对于不含有1x1特征的模型,论文中采用的是一个常量值1e-6。值得说明的是IN也是在H,W维度上进行归一化,但是会减去均值,对于N=1的情况归一化的结果是0,但FRN可以避免这个问题。
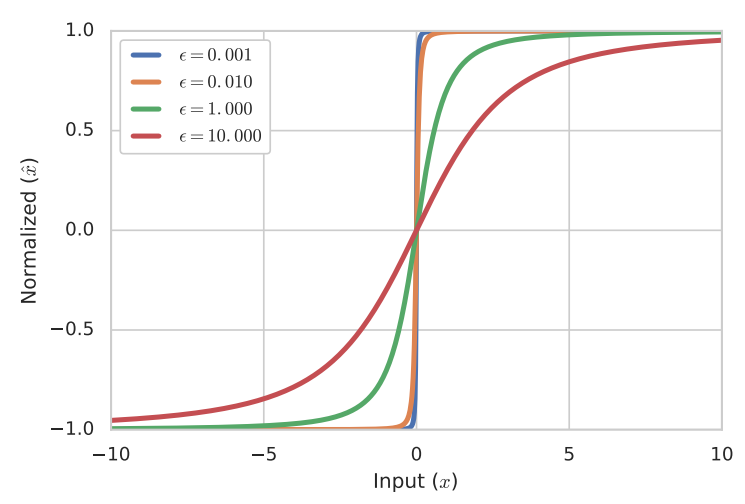
图4 当N=1时不同e对FRN归一化的影响
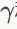 和
和
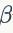 也是可学习的参数(参数大小为C):
也是可学习的参数(参数大小为C):
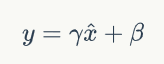
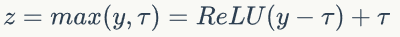
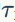 是一个可学习的参数。论文中发现FRN之后采用TLU对于提升性能是至关重要的。
是一个可学习的参数。论文中发现FRN之后采用TLU对于提升性能是至关重要的。
def FRNLayer(x, tau, beta, gamma, eps=1e-6):# x: Input tensor of shape [BxHxWxC].# alpha, beta, gamma: Variables of shape [1, 1, 1, C].# eps: A scalar constant or learnable variable.# Compute the mean norm of activations per channel.nu2 = tf.reduce_mean(tf.square(x), axis=[1, 2],keepdims=True)# Perform FRN.x = x * tf.rsqrt(nu2 + tf.abs(eps))# Return after applying the Offset-ReLU non-linearity.return tf.maximum(gamma * x + beta, tau)
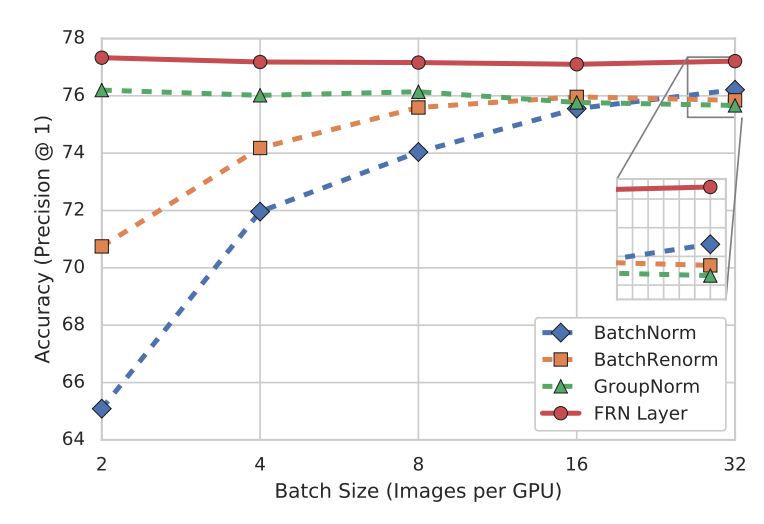
可以看到FRN是不受batch size的影响,而且效果是超越BN的。论文中还有更多的对比试验证明FRN的优越性。
小结
BN目前依然是最常用的归一化方法,GN虽然不会受batch size的影响,但是目前还没大范围采用,不知道FRN的提出会不会替代BN,这需要时间的检验。
-
Group Normalization.: https://arxiv.org/pdf/1803.08494.pdf -
Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks.: https://arxiv.org/abs/1911.09737 -
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.:
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、OCR、姿态估计等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~

