以莺尾花数据集为例,探讨R模型部署之道
作者:数据栗子,资深数据分析师,擅长数据挖掘,可视化,机器学习! 团队公众号:数据取经团(ID:zlx19930503),欢迎大家关注!
内容概要:
1、iris数据集简介
2、R模型部署的可能方案
3、H2o.ai框架及pojo/mojo模型部署
正式内容:
iris data set简介
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
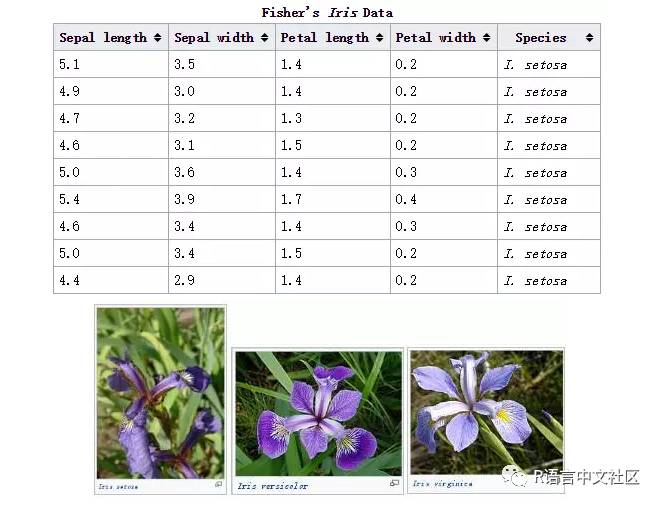
数据集链接:http://archive.ics.uci.edu/ml/datasets/Iris
图片来源:
https://en.wikipedia.org/wiki/Iris_flower_data_set
R模型部署的可能方案
R语言模型部署的相关内容网络或者书籍上介绍的比较少,博主在一段时间摸索后对自己了解的可能方案进行如下归纳,仅供参考:
部署方式 |
涉及的包及工具 |
简介 |
Mojo/Pojo |
H2O |
H2O可以将训练好的model转换为Plain Old Java Object (POJO) or a Model ObJect, Optimized (MOJO),从而很容易嵌入java环境中。仅需通过提供的h2o-genmodel.jar生成相应的war包即可。 |
web API |
pumber包 |
Turn your R code into a web API https://www.rplumber.io,而且还可以通过PM2/ Docker等方式实现服务托管 |
PMML |
r2pmml包 |
R package for converting R models to PMML,然后用java调用pmml进行部署 |
H2o.ai框架及pojo/mojo模型部署
H2o.ai为开源的AI平台(Open Source AI Platform),提供了R、python、h2oflow等作为前端的机器学习建模平台,支持的算法有:监督学习(GLM、GBM、Deep Learning、Distributed Random Forest、Naive Bayes、Stacked Ensembles),非监督学习(GLRM、K-Means、PCA)以及Word2vec模型。

H2o.ai模型的部署方式
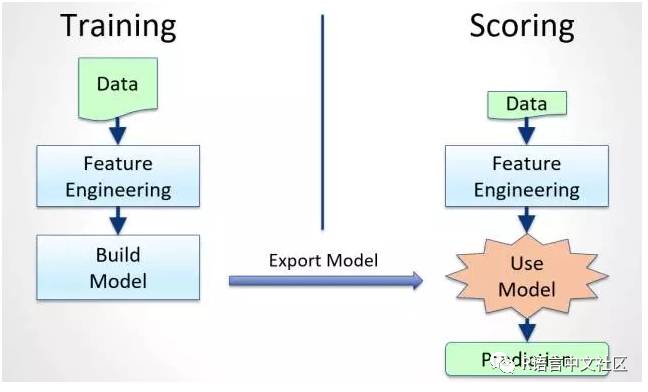
训练分类模型(GBM)=>model输出为pojo格式 =>pojo转换为war包 =>jetty容器运行war包 =>api服务
使用h2o+R训练GBM分类器
#加载包
library(h2o)
#h2o环境初始化
h2o.init()
fr <- as.h2o(iris)
my_model <- h2o.gbm(x=1:4,y=5,training_frame=fr)
h2o.download_pojo(my_model,getwd())
h2o.shutdown()

构建H2O预测服务器
a.准备工作:
Java 1.6、rJava、jetty-runner环境的安装,Linux/ Mac OSX系统

b.build the H2O Prediction Service Builder:
克隆steam文件git clone https://github.com/h2oai/steam
打开一个terminal窗口,进到steam/prediction-service-builder目录下
Run ./gradlew build 来构建服务
出现BUILD SUCCESSFUL message之后,Run ./gradlew jettyRunWar 来运行builder service
打开浏览器,输入localhost:55000,出现模型builder界面,选择 GBM_model_R_XXX.java/h2o-genmodel.jar包(上一步生成的文件),此时会生成一个war,保存(拷贝到~/steam/prediction-service-builder目录下)以便下一步使用。

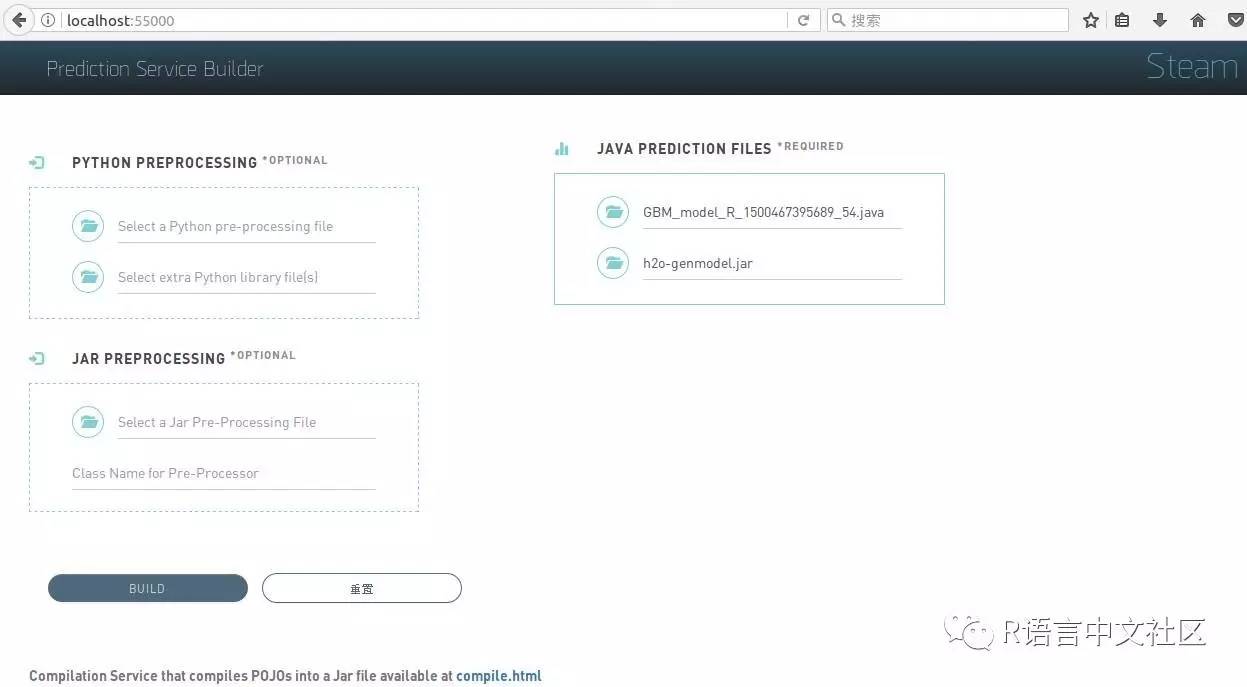
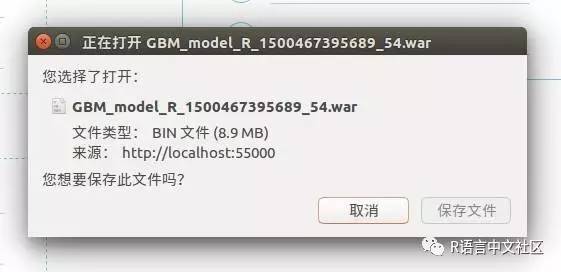
Run the Builder Service
新开一个一个terminal窗口,进到~/steam/prediction-service-builder目录下,运行:java -jar jetty-runner-9.3.9.M1.jar --port 55001 ~/GBM_model_R_1500467395689_54.war
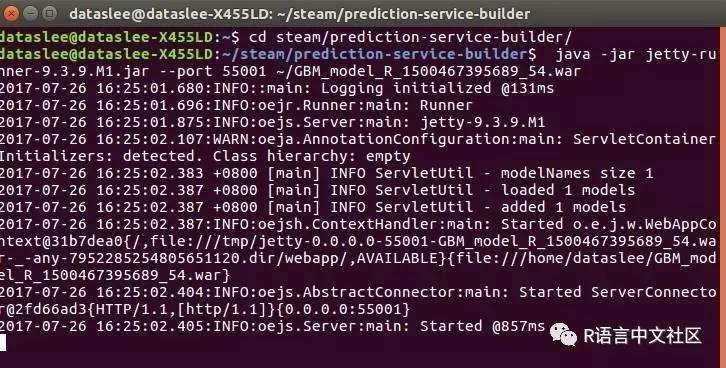
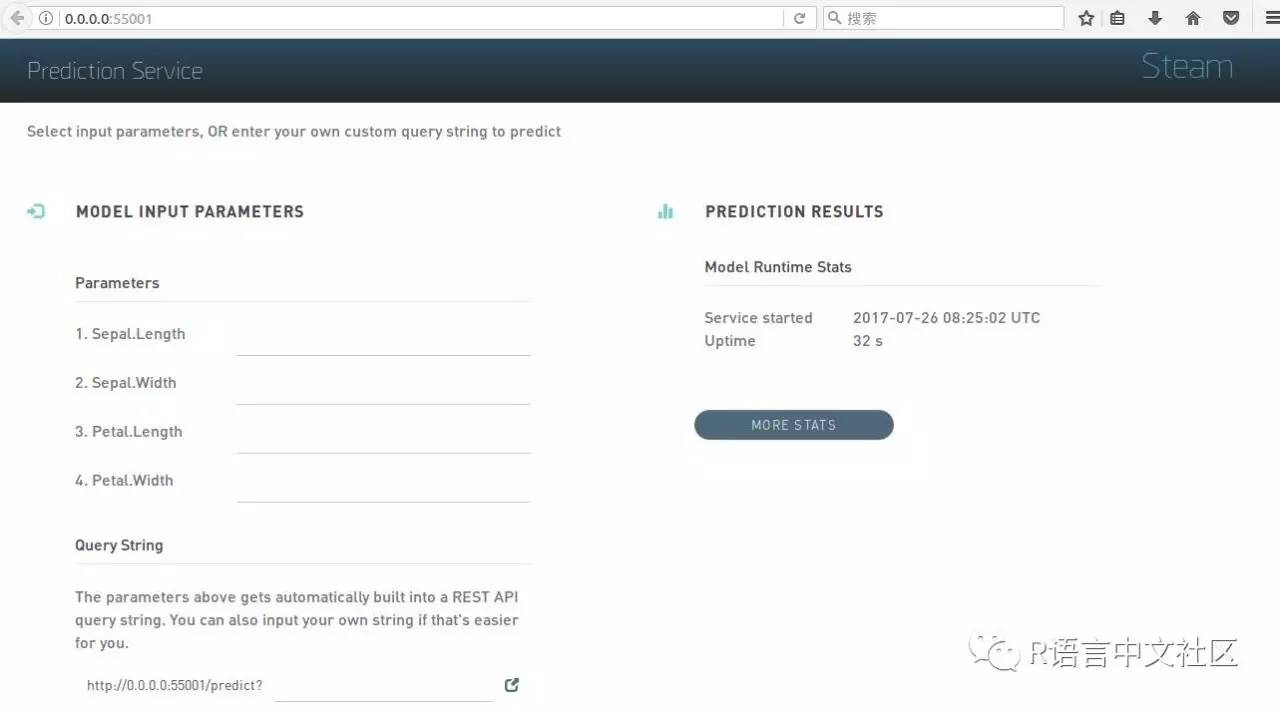
浏览器输入http://localhost:55001,进入预测界面:
输入相关参数,点击predict,页面右侧就出现了预测结果:分属于每一个类别的概率。
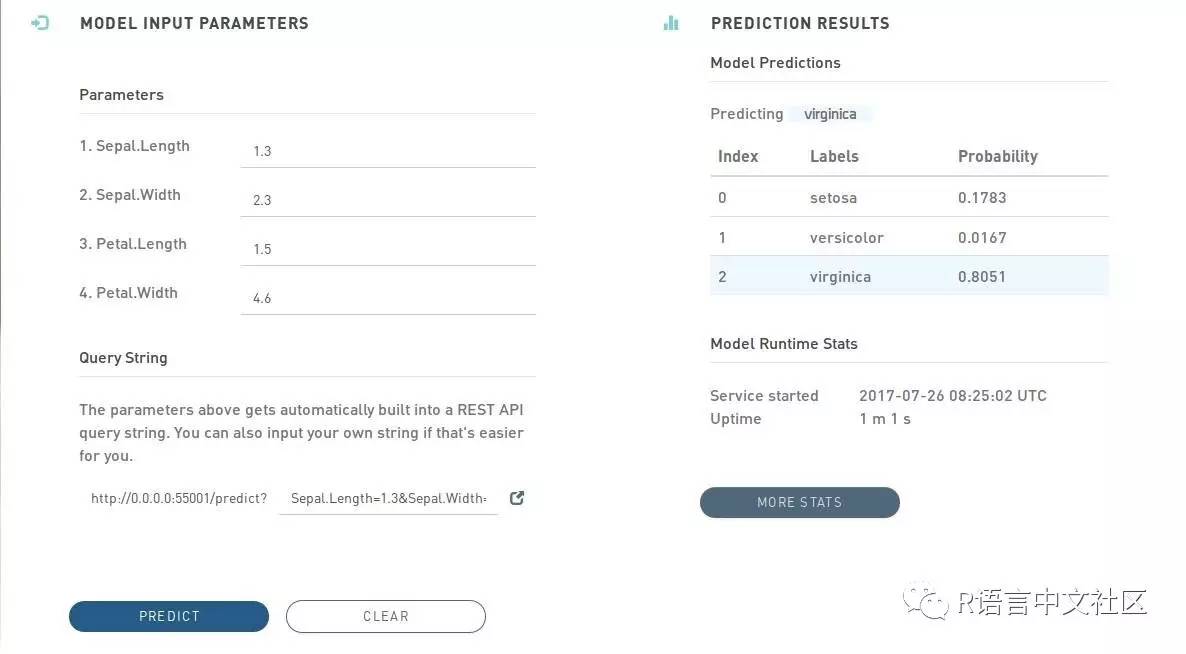
同时,还可以点击

参考文档:
https://github.com/h2oai/steam/tree/master/prediction-service-builder
PS:
本次只对mojo/pojo的方式进行了阐述,后期会对其他两种方式进行探讨,敬请期待。




