CVPR 2019 开源论文 | 姿势服装随心换

编者按:近年来,基于人体姿态引导的图像生成算法受到越来越广泛的关注。该项技术不仅可以辅助图像/视频编辑、行人重识别(Re-ID),也为时尚领域的服饰设计、虚拟试衣等应用提供了支持。本文介绍了人体姿态引导下基于语义转换的无监督人物图像生成算法,能够有效保持人体和衣物的原有属性,提高图像的视觉质量。此外,该算法同时可以应用于衣物纹理转换、时尚图像编辑等任务中,让图像中的人物不仅可以随意变换姿势,还能够变换服装的款式和纹理,成为百变先生/小姐。

基于人体姿态引导的人物图像生成,是指给定源人物图像和目标人体姿态,生成目标姿态下的人物图像,同时保持源人物图像的外观特征。在该任务中,由于输入和输出图像的空域非对应性和几何形变,导致难以直接刻画输入图像和输出图像的映射关系;无监督条件下真实图像监督的缺乏,使这一映射关系的构建更加困难。
基于上述原因,当前无监督式方法生成的人物图像质量不太理想,主要表现在未能正确保持输入图像的原有衣物属性,包括纹理、衣物款式、人体形态结构等方面。
现有模型虽然尝试使用将输入图像和输出图像的直接映射关系分解(如按照前景背景分解、按照形状和外观分解),以简化对映射关系的建模过程,但是由于未对人体结构进行精细化分解,导致输出图像中人体结构的形状不完整,以及衣物属性未能保持。
为了解决上述问题,该文提出了基于语义转换的无监督人物图像生成算法,以人体语义图为引导,完成目标姿态下的人体图像生成。一方面,语义图不包含纹理信息,简化了无监督下输入输出的形状映射关系学习;另一方面,人体语义的引导对保持衣物的原始属性(款式、纹理等)提供了先验知识。
具体来讲,该文将人物图像生成分解为两部分:人体语义转换和人体外观生成,如图 1 所示。
在人体语义转换模块()中,根据输入图像的人体语义图和目标姿态,预测输出图像的人体语义图,其中,输入图像的人体语义图由现有人体语义分解器得到;在人体外观生成模块(
)中,根据预测的输出图像人体语义图和输入图像,在对应语义位置渲染输出人物图像的纹理,得到最终的输出图像。
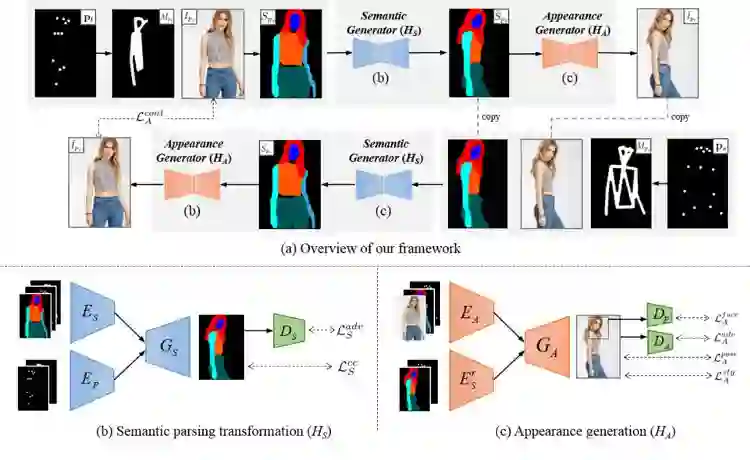
人体语义转换
人体语义转换模块旨在根据输入图像的人体语义图和目标姿态,生成输出人体语义图,以正确预测人体每一个语义结构的形状和边界。由于没有外观信息,不同外观下的人物图像可能共享相同的人体语义图。
根据这一特点,该文算法可在训练集中搜寻成对的人体语义图,它们满足:1)处在不同的姿态;2)具有相同的语义信息。利用这些成对的数据,该文以监督式的方法对语义转换模块进行预训练。在训练过程中的损失函数主要包括交叉熵函数和对抗损失函数。其中,交叉熵损失函数用来监督转换后的语义图生成,对抗损失函数能使生成的语义图在视觉效果上更加真实。
人物外观生成
在上一阶段预测的输出图像人体语义图的引导下,外观生成模块对每一个语义结构进行纹理渲染,以更好地保持人物图像的外观属性。由于没有真实图像的监督,人体外观生成的训练基于循环生成对抗网络(CycleGAN)的训练思想。在外观生成模块的训练中,损失函数主要包括以下几个部分:
1. 对抗损失函数:使生成的人物图像更加接近真实自然图像;
2. 人体姿态损失函数:约束生成的人物图像姿态和目标姿态一致;
3. 内容一致损失项:即 Cycle consistency 损失;
4. 语义引导的风格损失项:通过限制相同语义部分高维特征的 Gram 矩阵距离,约束相同语义部分的纹理迁移;
5. 人脸损失项:通过人脸上的节点定位人脸区域,对人脸部分设置独立的判别器,提升人脸部分的重建效果。
端到端训练方式
算法分析
图 2 对该文算法进行了分析,和 Baseline 相比,引入语义信息有效提升了网络的学习效果。此外,该文算法既可以分阶段训练(TS-Pred 以预测语义图为外观生成的输入,TS-GT 以真实语义图为外观生成的输入),也可以端到端训练(E2E),实验结果显示端到端训练的方式能够纠正语义转换模块中的错误,如第 1 行中人物的发型,第 2 行中人物的袖长。

▲ 图2. 算法分析

实验
该文算法可以运用在三个任务上:基于人体姿态引导的人物图像生成,衣物纹理迁移和时尚图像编辑。
图 4 展示了人体姿态引导的人体图像生成算法在 DeepFashion 数据库 [8] 上的效果,比较的方法包括 PG2 [2],Def-GAN [3],UPIS [4],和 V-Unet [5],其中 PG2,Def-GAN 为监督式算法,而 UPIS,V-Unet 是无监督算法。在无监督的情况下,本文的工作不仅能够生成更加真实的图像,也同时能够保持衣物的原有属性,如衣物的纹理(第 1,2,4 行),衣物的类型(3,5 行)。

▲ 图4. 人体姿态引导的图像生成
同时,本文的工作可以应用在衣物纹理的迁移之中,如图 5 所示,将人物 A 和人物 B 的衣物互换,和 Image analogy [6] 和 Neural doodle [7] 相比,该文算法能够生成自然真实的结果,同时实验结果也表明该文模型能够本质上学习到对应语义区域之间的映射。

▲ 图5. 衣物纹理迁移
此外,该文算法也可以作为时尚图像编辑的支撑,通过改变人体语义图,可以将人物的衣服款式做出相应变化。如下图,无袖 T 恤可通过编辑语义图改为长袖(第 1 行),裙装可以改为裤装(第 2 行)。

▲ 图6. 时尚图像编辑
以上是无监督场景下的训练结果,有监督情况下的生成质量更高。
该团队日前开源了有监督场景下的工作 [9]。基本采用了基于语义转换的思路,并且由于更强的监督信息,生成的图像更加逼真,并且能保持更多的图像细节。

图 7 展示了有监督下的生成结果,在细节区域(如衣物纹理、头发、人脸)的生成上大大改善。该工作首先优化了生成网络中的卷积模型,提出用 tree-dilation block 替代传统的 res-block。由于引入多尺度、大感受野的信息,在面部、衣服细节上都有了明显改善。最终的生成图像尽可能地保留了源图像中的细节。

图 8 表明,该方法相对于目前的主流方法,对细节部分的把握更胜一筹。

该工作目前已在 Github 上开源:
实习生招聘
该团队目前正在招聘实习生,感兴趣的同学请发送简历至:wzhang.cu@gmail.com
参考文献

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码

