针对 3D 计算机视觉的简介

雷锋网按:本文为 AI 研习社编译的技术博客,原标题 An introduction towards 3D Computer Vision, Jian Shi。
翻译 | 江舟 校对 | Lamaric 整理 | MY
随着 AR / VR 技术和自动驾驶汽车技术的发展,3D 视觉问题变得越来越重要,它提供了比 2D 更丰富的信息。本文将介绍两种用于 3D 场景分析的基本深度学习模型:VoxNet 和 PointNet。
3D 图像介绍
3D 图像会多包含一个维度,即深度。有两种最广泛使用的 3D 格式:RGB-D 和点云。
RGB-D
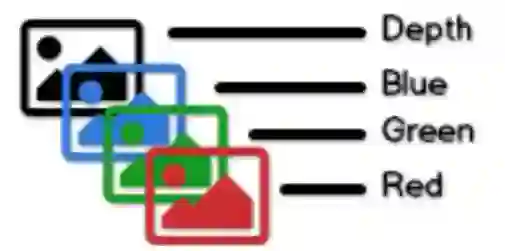
RGB-D 格式图像就像一堆单值图像,每个像素都有四个属性,红色,绿色,蓝色和深度。
在普通的基于像素的图像中,我们可以通过(x,y)坐标定位任何像素,然后就可以分别获得三种颜色属性(R,G,B)。而在 RGB-D 图像中,每个(x,y)坐标将对应于四个属性(深度,R,G,B)。RGB-D 和点云之间的唯一区别在于,在点云中,(x,y)坐标反映了其在现实世界中的实际值,而不是简单的整数值。
点云

网上的点云样例
点云可以由 RGB-D 图像构建。如果你有已扫描的 RGB-D 的图像,并且还知道扫描相机的内在参数,那么你可以以 RGB-D 图像创建点云,方法是通过使用相机内在参数计算真实世界的点(x,y)。这个过程被称为相机校准。因此,到目前为止,你知道了 RGB-D 图像是网格对齐的图像,而点云是更稀疏的结构。
3D 视觉
就像 2D 问题一样,我们想要检测并识别 3D 扫描图像中的所有对象。但与 2D 图像不同的是,为了充分使用 CNNs 方法的数据,它的最佳输入格式该是什么就成了一个需要解决的问题。
体素化网格
体素化网格是将 3D 对象拟合到网格中的最直观的方法,为了使其看起来像是像素图像,我们在这里将其称为体素。在这种情况下,3D 图像由(x,y,z)坐标描述,它看起来就会像乐高一样。
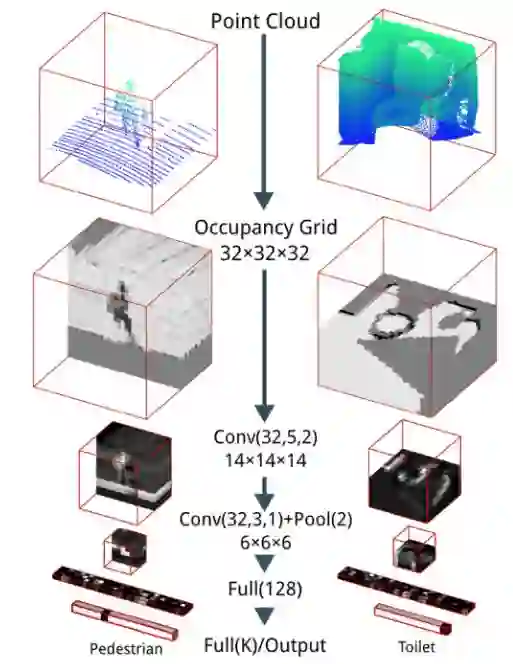
VoxNet 架构来自“VoxNet:一个用于实时物体识别的 3D 卷积神经网络”,作者:Daniel Maturana 和 Sebastian Scherer。
VoxNet 是一种基于深度学习的框架,它使用占据网格方法对 3D 点云进行分类,VoxNet 在分类问题上非常有效。
例如,如果我们将点云拟合到 32x32x32 的体素化网格,我们可以构建一个全部填充为零的 32x32x32 的数组。然后缩放点云来计算每个体素内的有多少个点。
在获得体素化网格后,我们接下来执行 3D 卷积计算,这有效地在基于体素的图像上滑动立方体(译者注: 3D 卷积是通过堆叠多个连续的帧组成一个立方体,然后在立方体中运用 3D 卷积核)。
我们将扫描扩展到相同的基础。我们设想如果我们进行大规模扫描,每个物体将只是一个会导致一些问题的体素。而且,由于那些上采样操作,不容易确定每个体素的 RGB 颜色。
对于简单的数据集(具有相似的点数,相似的扫描比例),VoxNet 可能是一个简单而效果好的方法。但如果遇到复杂的数据集,它可能并不是一个好的选择。
点
虽然基于体素化的方法可以在分类问题上展现很好地工作效率,但它为上采样操作牺牲了大量信息。因此,我们希望能够在点上来训练有更好效果的网络。
第一个问题是点的顺序,我们知道点云对点的顺序是不变的。
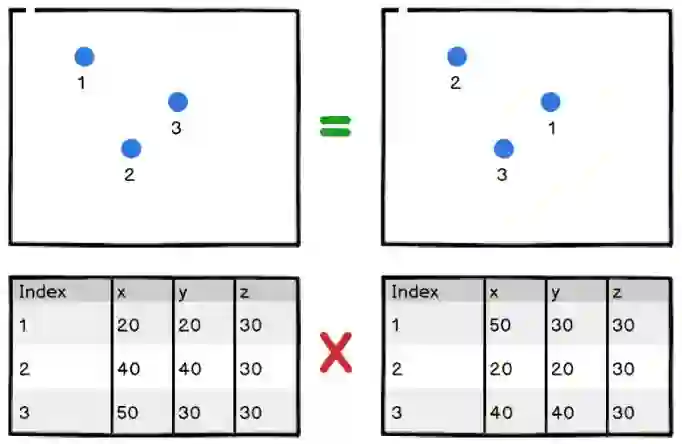
点云文件可以在不更改实际渲染的情况下被更改。
处理此问题(PointNet)有三种策略:
对点进行排序。
输入为 RNN 的序列,此序列通过增加各种排列来增大。
使用对称函数来聚合来自每个点的信息。在此对称函数中,+ 或 * 是对称的二元函数。
在 PointNet 的论文中,文中说第一种方法会产生一定的计算强度,第二种方法则不够健壮。因此,在这里将使用最大池和对称函数。而最大池是这里的主要操作。
整个框架如下文所述,你也可以去 GitHub 参见完整的实现过程。
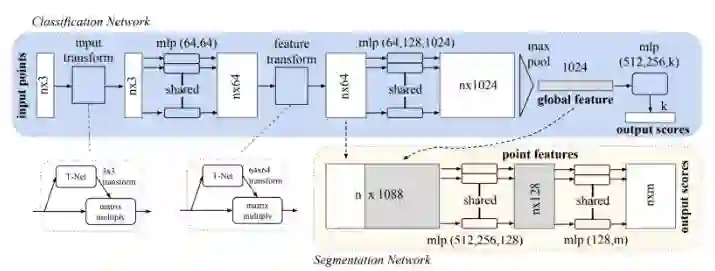
PointNet 的架构中,mlp 代表多层感知器。T-Net 是一个微小的变换网络。
通常,它是卷积、完全连接和最大池化层的一种灵活使用方式。我发现一开始可能会很难理解这些,因此我们可以直接看代码去更好地理解。
首先,我将给出一个示例点云,它每行是(x,y,z,r,g,b)。其中每行代表一个点。假设我们在这个例子中有 n 个点。

注意:PointNet 的实际输入使用标准化 RGB 色域,基点的 x,y 在空间的中心是对齐的。为了不与浮点数之间发生混乱,在这里我没有这样做。
PointNet 中的分类
第一步操作是进行 2d 卷积,其内核大小为(1,6),它用来聚合一个点的相关信息(x,y,z,r,g,b;总共六个)。此处的输出应为(n,1,64)。

注意:每层都有批量标准化,我将其删除以简化演示过程。此外,原始 PointNet 使用 9 个特征作为输入(x,y,z,r,g,b,normalized_x,normalized_y,normalized_z)。
这里是几个 1x1 卷积运算以逐个像素点的方式检测这些特征。因此,我们将在这之后产生一个(n,1,1024)的数组。

接下来是最重要的步骤,最大池会选择所有点中最显著的特征。这就是函数对点的顺序不变的原因。由于我们在先前的图层中有 1024 个过滤器,因此该图层将输出 1024 个特征。

之后,所有特征将通过完全连接层被完全连接。

注意:这里的批量大小是 1。PointNet 的输入是一个扫描的场景,此场景将被分成小批量(每批有 4096 点)。PointNet 将执行特征检测批处理程序。
到目前为止,如果你再添加一个完全连接的图层来输出类标签的数量,则可以回到之前的图,而这就是 PointNet 在点云上进行分类的方式。简单地可以分为以下三点:
汇总每个点信息。
找到每个点最显著的特征。
然后完全连接来分类。
PointNet 中的语义分割
分割可看作分类模型不断发展的结果。不过,我们希望网络能够忽略点的顺序。因此,我们将每个点特征与全局特征连接起来,让每个点都知道上下文。

然后我们将使用几个 1x1 卷积内核来提取新的逐点特征。

然后我们就能做出逐点预测。例如,每个点有 13 个类。

原文链接:
https://medium.com/@jianshi_94445/an-introduction-towards-3d-computer-vision-71be8ce11956
点击文末【阅读原文】即可观看更多精彩内容:
针对 3D 计算机视觉的简介
十大预训练模型助你学习深度学习 —— 计算机视觉篇
在树莓派上实现人脸识别
用深度学习技术,让你的眼睛可以控制电脑
斯坦福CS231n李飞飞计算机视觉经典课程(中英双语字幕+作业讲解+实战分享)
等你来译:
神经网络中的梯度优化算法
使用转置卷积进行上采样
在容器生态中运行 GPU
医学图像文本注释的实例





