Nature论文预测余震只是炒作?数据科学家历时半年揪出漏洞
机器之心报道
参与:张倩、shooting
「《nature》、《Science》等或许是最负盛名的期刊,但其学术态度未必是最严谨的。」
最近,四川宜宾、云南楚雄接连发生地震,再次掀起人们对地震的恐慌。预测地震自古以来都是地震科学工作者的奋斗目标。在深度学习如此火爆的今天,人们不禁想到,强大的深度学习能否用于地震预测?
去年 8 月,《Nature》上发表了一篇题为《Deep learning of aftershock patterns following large earthquakes》的火爆论文。该论文由哈佛和谷歌的数据科学家联合撰写,论文一作所属单位是哈佛大学地球与行星科学系。
该论文展示了如何利用深度学习技术预测余震。研究者指出,他们利用神经网络在预测余震位置方面的准确率超越了传统方法。
但很快,这一方法就遭到了深度学习从业者的质疑。一位名叫 Rajiv Shah 的数据科学家表示,论文中使用的建模方法存在一些根本性的问题,因此实验结果的准确性也有待考究。这名数据科学家本着严谨的精神在通过实验验证之后联系了原作和《Nature》,却没得到什么积极的回复。
于是,Rajiv Shah 在 medium 上写了一篇博客揭露论文中存在的根本性缺陷以及《Nature》的不作为,后来这件事又在 Reddit 上引起了广泛的讨论。下面我们回顾一下事件的始末。
文章有点长,目录预览:
《Nature》原论文介绍
Rajiv Shah 博客揭露问题
论文作者的回复
Reddit 热评精选
谷歌&哈佛团队利用深度学习预测余震,准确率空前

这篇名为《Deep learning of aftershock patterns following large earthquakes》的论文展示了如何利用深度学习技术预测余震。
论文指出,解释和预测余震的空间分布非常困难。库仑破裂应力变化可能是解释余震空间分布最常用的判据,但其适用性一直存在争议。于是,研究者使用了深度学习方法来确定一种基于静态应力的准则,该准则无需提前假设破坏的方向就能预测余震的位置。
研究者在超过 131,000 个主震-余震对上训练了一个神经网络,然后在一个包含 30000 多个主震-余震对的独立测试集上测试其预测余震位置的准确率。
研究者利用 ROC 曲线来衡量神经网络预测余震位置在测试数据集上的准确率。为了构建这些曲线,他们绘制了一个二元分类器的真阳性率与该分类器所有可能阈值的假阳性率。ROC 的曲线下面积用来度量模型在所有阈值下的测试性能(如图 1 所示)。

图 1:主震-余震对示例
下图 2 的测试结果表明,神经网络预测余震位置的准确率(AUC 为 0.849)高于经典的库仑破裂应力变化(AUC 为 0.583)。
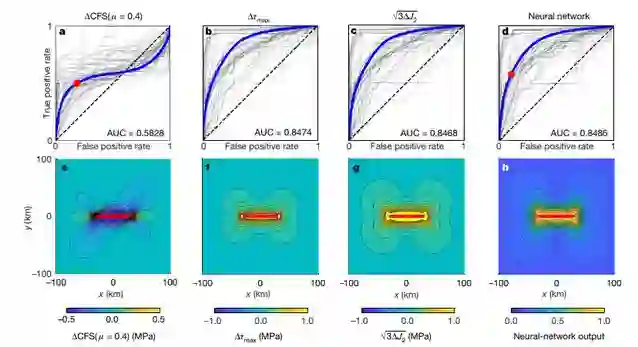
图 2:模型性能比较。
论文链接:https://www.nature.com/articles/s41586-018-0438-y
论文全文:https://sci-hub.tw/https://www.nature.com/articles/s41586-018-0438-y
Rajiv Shah 博客揭露论文根本缺陷
以下是 Rajiv Shah 题为《Stand Up for Best Practices: Misuse of Deep Learning in Nature』s Earthquake Aftershock Paper》的博客内容。
机器学习炒作的危害
AI、深度学习、预测建模、数据科学等方面的从业者数量在过去的几年里急剧增长。这个混合了多种知识且曾被认为有利可图的领域正在成为一个快速发展的行业。随着人们对 AI 的热情持续高涨,机器学习增强、自动化和 GUI 工具的浪潮将促进预测模型构建者人数的持续增长。
但问题是,尽管使用预测模型的工具变得越发简单,但预测建模所需的知识还不是一种大众化的商品。错误可能是违反直觉且微妙的,你一不小心就会得出错误的结论。
我是一名数据科学家,与数十位数据科学专家共事,每天目睹这些团队努力构建高质量模型。最好的团队通力合作,检查他们的模型以找出问题。有很多问题可能难以被检测到,这样就会得到有问题的模型。
挑毛病的过程一点也不好玩,需要承认那些振奋人心的结果「好得不真实」,或者他们的方法不是正确的方法。换句话说,这是一门严谨的学科,与那些登上头条的性感数据科学炒作没多大关系。
糟糕的方法得到糟糕的结果
大约在一年前,我读到了《Nature》上的一篇论文,论文作者声称他们利用深度学习预测余震达到了前所未有的准确率。读过之后,我对他们的结果产生了深深的怀疑。他们的方法根本不具备一个严谨预测模型的诸多特征。
因此我开始深挖。与此同时,这篇论文成了爆款,而且得到了广泛认可,甚至出现在 TensorFlow 的版本更新公告中,用于说明深度学习的应用。
然而,我在深挖过程中发现了论文的重大缺陷,即导致不真实准确率得分的数据泄漏(data leakage)以及模型选择(当一个较为简单的模型可以提供相同水平的准确率时,完全不必构建一个 6 层的网络)。

测试集的 AUC 比训练集高得多……这不正常。
如上所述,这些都是很微小但却非常基础的预测模型错误,可能导致整个实验结果无效。数据科学家在工作中会学着识别并避免此类问题。我认为作者只是忽视了这一点,因此我与她取得了联系,以告知她这些问题来提高分析结果。但她没有回复我的邮件。
他们充耳不闻,我不能
那么我接下来该做什么呢?我的同事建议我发篇 twitter 就算了,但我想站出来,为那些好的建模实践发声。我认为理性的推理和良好的实践会比较有说服力,因此我开始了一场为期六个月的研究,并写下我的结果分享给《Nature》。
分享了我的结果之后,我在 2019 年 1 月收到了《Nature》的一份通知,称虽然担心数据泄漏和建模选择可能会使实验无效,但他们认为没必要纠正错误,因为「Devries 等人的主要目的是将机器学习作为一种工具来深入了解自然界,而不是设计算法的细节。」而作者给出了更严厉的回应。
仅仅用「失望」来表达我的感受是远远不够的。这可是一篇重要论文(《Nature》发的!),这助长了 AI 的炒作之风,尤其是在其使用了有缺陷的方法之后还是得到了发表。
就在这周,我偶然看到了 Arnaud Mignan 和 Marco Broccardo 发表的关于这篇余震预测论文的文章。这两位数据科学家也注意到了论文中的缺陷。
Arnaud Mignan 和 Marco Broccardo 的论文:A Deeper Look into 『Deep Learning of Aftershock Patterns Following Large Earthquakes』: Illustrating First Principles in Neural Network Physical Interpretability
论文链接:https://link.springer.com/chapter/10.1007/978-3-030-20521-8_1
我把我的分析和可复现代码贴在了 GitHub 上。
GitHub 链接:https://github.com/rajshah4/aftershocks_issues
你可以亲自运行分析,看看问题所在
支持预测建模方法,但论文存在根本缺陷
我想说清楚的一点是:我的目的并不是诋毁余震预测论文的作者。我相信他们不是恶意的,我觉得他们的目标可能只是想展示机器学习如何应用于余震。Devries 是一位有成就的地震科学家,她只是想在自己的研究领域中使用最新的方法,并从中发现了令人兴奋的结果。
但问题是:他们的见解和结果是基于有根本缺陷的方法。「这不是一篇机器学习论文,而是关于地震的论文。」这样评价是不够的。如果你使用预测建模方法,那结果的质量是由建模质量决定的。如果你做的是数据科学工作,那你的科学严谨性岌岌可危。
在这个领域,人们对使用最新技术和方法的论文有着极大的兴趣。而一旦有问题,收回这些论文又比较困难。
但如果我们允许有基本问题的论文或项目继续推进,那会对所有人都不利。它破坏了预测建模领域。
请反对不好的数据科学,公布那些糟糕的发现。如果他们不行动,那就去推特发帖子,公布你发现的结果,让大家能够知道。如果我们希望机器学习领域继续发展并保持信誉,那我们需要的是良好的实践。
论文作者回应
上文中,Rajiv Shah 对论文作者的回应仅用了一个词:严厉。而 Reddit 网友发现,作者的回复可以说是很不客气了。在下面这篇写给《Nature》编辑的回复中,论文作者在最后一段甚至这么表述:「我们是地震科学家,你是谁?」

以下是作者回复原文:
我们很高兴人们下载我们的数据并运行代码。但这些具体的评论并不值得在《Nature》上发表。他们并不了解这个领域;事实上,这些观点要么是错的,要么是完全忽略了科学的要点,同时又想方设法让自己的观点处于一种居高临下的地位。
总之,这些评论可以分为三点:1)「数据泄漏」的想法可能会夸大结果;2)随机森林方法的表现类似于神经网络;3)我们学习的是一个简单的信号。下面,我们将依次解决这几个问题。
1)对「数据泄漏」夸大结果的担忧在科学背景下毫无意义。如论文中所说的,我们根据不同的主震随机划分训练/测试数据集,并根据简单、固定的 time-window 方法选择余震。
评论者正确地指出,这种方法意味着在一些训练/测试样本中,会出现主震 B 被包含在主震 A 的余震序列中的情况。如果断章取义地来看,这似乎会夸大结果。但如果你考虑了具体的科学方法,就会发现根本不是这样的。
例如,假设主震 A 被分配到训练数据集,主震 B 被分配到测试数据集,但主震 B 被包括在主震 A 的余震中。神经网络会在主震 A 的余震序列上接受部分训练(使用主震 A 引起的应力变化作为输入)。由于主震 B 包含在主震 A 的余震中,网络可能会在一些相同的余震上进行测试,但使用主震 B 引起的应力变化作为输入。
网络把建模的应力变化映射至余震,这种映射对于训练数据集和测试数据集中的样本来说是完全不同的,尽管它们在地理上重叠。训练数据集中没有任何信息会帮助网络在测试数据集中表现良好,相反,测试数据集会要求网络解释它在训练数据集中见过的相同余震,但这些余震的主震不同。如果主震相似,的确会损害网络在测试数据集上的性能。
由于这种「数据泄漏」,评论者称我们夸大了神经网络的性能。如上所述,我们随机将数据分成训练集和测试集,并早早地留出了测试数据集。这是一种标准的方法。在最后的评估中,最大剪应力变化、米塞斯屈服准则(von-Mises yield criterion)和神经网络在测试数据集上都表现相似(AUC 得分为 0.85)。
神经网络的良好性能、最大剪应力变化和米塞斯屈服准则是本论文的中心结果之一。神经网络有可能在地震触发中发挥作用。迄今为止,最大剪应力变化和米塞斯屈服准则尚未在地震触发文献中广泛使用。
2)评论者说这篇论文会「给人一种误解,即只有深度学习能够学习余震」。在论文中,我们使用神经网络作为工具来深入了解余震模式;但我们并没有认为其它机器学习方法是无用的。
神经网络和随机森林通常在浅显或不可感知的机器学习任务上表现相似。这并不奇怪。论文中有一个深刻的结果:神经网络学到了一个与简单的基于物理的应力量高度相关的位置预测。就算另一种机器学习方法也可以提供这些见解,也不能否认这个结果。这就好像在说「我们在用铅笔而不是钢笔写着同样的内容」,科学还没有进步。
3)神经网络学习一个简单的模式是论文的要点。神经网络学习了一个与非常简单却很少使用的量高度相关的模式——最大剪应力和偏应力张量的第二个不变式。如上所述,我们在论文中对此进行了大量讨论,因为这就是论文的要点。
评论者没有专业背景。我们是地震科学家,我们的目标是使用深度学习方法来深入了解余震位置模式。我们实现了这一目标,但那些评论者没有,如果《Nature》选择发表那些评论,我们将会非常失望。
Reddit 热评精选
在 Rajiv Shah 发表自己的分析结果之后,一位网友将此事发到了 reddit 平台上,引发了众多讨论。

热评 1:相比评论者(Rajiv)的言论,作者的回复更居高临下。
评论者认为更简单的方法可以达到差不多的效果,强调了进行适当控制变量实验的必要性。作者回复的最后一段基本上在说「我们是地震科学家,你是谁?」,并告诉《Nature》如果发表这些评论他们会很失望。
为什么评论者的这些担忧不值得在《Nature》上发表?为什么这些评论要被限制?发表它们不是会促进更健康的科学讨论吗?如果我在为机器学习大会审查这篇论文,我也会有类似的担忧。至少需要一些控制变量实验吧。
热评 2:论文的论点有些奇怪,Rajiv 的批评可以更具体
个人认为,Rajiv 犯的一个错误是指出更简单的模型可以做同样的工作,这让他的批评焦点变得不明确。这个问题并不会使论文无效,它更适合单独写一篇文章来讨论,就像 Mignan 和 Broccardo 所做的那样。
不过,在作者的回复中,论文的论点有些令人困惑:他们的论点似乎是「剪应力的最大变化和米塞斯屈服准则是有用的量,因为神经网络得出的准确率与它们相同」。如果这些基于非机器学方法的 AUC 分数只能相对于神经网络来解释,那准确地实现神经网络非常重要。
总之,我认为 Rajiv 最好这么做:1)明确指出对该研究应做的修改,例如更新 AUC 分数并在论文中解释方差值;2)写下他更广泛的评论并发表在 arXiv 或类似的网站上。
btw,我的博士生导师经常说,像《Nature》和《Science》这样的顶级期刊有相对较高的几率发表那种后来无法复现或者被发现有某种缺陷的论文。它们可能是最负盛名的期刊,但这并不意味着它们是最科学严谨的。
热评 3:《Nature》负有不可推卸的责任,不作为实在令人恼火
人们都把注意力集中在作者身上,但有网友指出,《Nature》本身也有责任。人们花了那么多钱才能读他们的内容,因此他们应该花功夫仔细审查,避免发表错误的方法。
另一位网友表示,Ta 被《Nature》的反应惹火了。《Nature》好像在说,「反正大众也不懂这些批评,所以我们什么也不用做」。至少要让论文作者更新论文来应对批评啊。
热评 4:论文作者真的懂什么是数据泄漏吗?
博客中已经提到,这篇论文的两大问题之一在于「数据泄漏」,那么什么是数据泄漏呢?
Reddit 热评认为,数据泄漏是指当你进行预测时,使用了一些现实上无法用于预测的信息,比如说 2017 年做预测的时候无法获得关于 2018 年的数据。网友认为,关于地震预测,使用的数据只能用来预测关于同一场地震的信息,而如果要预测未来的地震,你没有相关的信息数据来训练模型。
网友 Xorlium 表示,Ta 没看论文,因此也不太理解其它讨论。但作者关于数据泄漏的回答却似乎暴露了其没有真正理解数据泄漏的真相。
热评 5:他们只是为了经费
一位网友表示,「你们是地震科学家,那么你们应该知道自己的知识和教育边界,而机器学习并没有包括在里面。」
这只是众多真正的科学家走向堕落的故事之一。他们不是为了科学,而是为了得到关注(发表),以此获得更多的经费,然后利用这些经费得到更多的关注。这不再是关于真理的研究。因此他们那「更加严厉」的回应是出于自我防卫。他们根本不在乎真理和真正的科学。

参考链接:
https://towardsdatascience.com/stand-up-for-best-practices-8a8433d3e0e8
https://github.com/rajshah4/aftershocks_issues/blob/master/correspondence/Authors_DeVries_Response.pdf
https://www.reddit.com/r/MachineLearning/comments/c4ylga/d_misuse_of_deep_learning_in_nature_journals/
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




