Scikit-learn玩得很熟了?这些功能你都知道吗?

大数据文摘作品
编译:汪小七、笪洁琼、Aileen
分享一些Scikit-learn程序包里鲜有人知的遗珠功能。
Scikit-learn是Python所有的机器学习程序包中,你必须掌握的最重要的一个包,它包含各种分类算法,回归算法和聚类算法,其中包括支持向量机、随机森林、梯度提升、k均值和基于密度的聚类算法(DBSCAN),且旨在与Python数值库NumPy和科学库SciPy进行相互配合。
它通过一个接口,提供了一系列的有监督和无监督算法。此库希望在生产中使用时,能具有很好的稳健性和支撑性,所以它的着重点在易用性,代码质量,协同工作,文档生成和性能等问题上。
不管是对机器学习的初学者还是经验丰富的专业人士来说,Scikit-learn库都是应该熟练掌握的优秀软件包。然而,即使是有经验的机器学习从业者可能也没有意识到这个包中所隐藏的一些特性,这些特性可以轻松地帮助他们完成任务。接下来本文将列举几个scikit-learn库中鲜为人知的方法或接口。
管道(Pipeline)
这可以用来将多个估计量链化合一。因为在处理数据时,通常有着一系列固定的步骤,比如特征选择、归一化和分类,此时这个方法将非常有用。
更多信息:
http://scikit-learn.org/stable/modules/pipeline.html
网格搜索(Grid-search)
超参数在参数估计中是不直接学习的,在scikit-learn库中,超参数会作为参数传递给估计类的构造函数,然后在超参数空间中搜索最佳的交叉验证分数在构建参数估计量时提供的任何参数都是可以用这种方式进行优化的。
更多信息:
http://scikit-learn.org/stable/modules/grid_search.html#grid-search
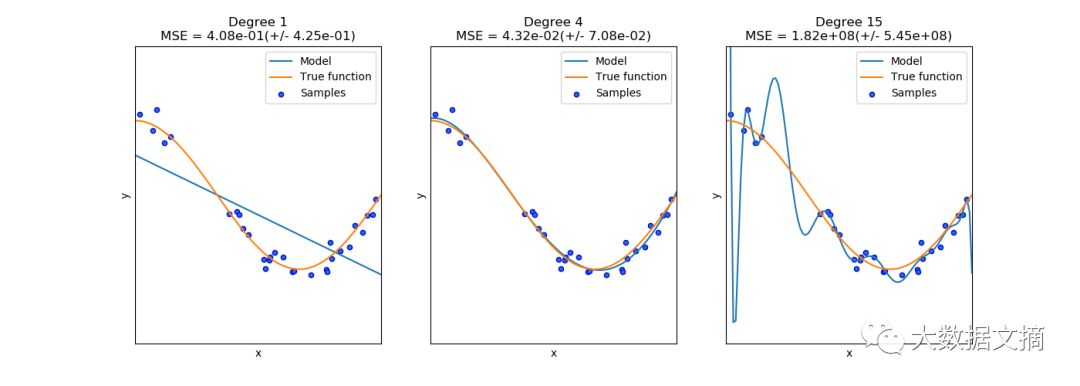
验证曲线(Validation curves)
每种估计方法都有其优缺点,它的泛化误差可以用偏差、方差和噪音来分解。估计量的偏差就是不同训练集的平均误差;估计量的方差是表示对不同训练集的敏感程度;噪声是数据本身的一个属性。
绘制单个超参数对训练分数和验证分数的影响是非常有用的,因为从图中可以看出估计量对于某些超参数值是过拟合还是欠拟合。在Scikit-learn库中,有一个内置方法是可以实现以上过程的。
更多信息:
http://scikit-learn.org/stable/modules/learning_curve.html
分类数据的独热编码(One-hot encoding of categorical data)
这是一种非常常见的数据预处理步骤,在分类或预测任务中(如混合了数量型和文本型特征的逻辑回归),常用于对多分类变量进行二分类编码。Scikit-learn库提供了有效而简单的方法来实现这一点。它可以直接在Pandas数据框或Numpy数组上运行,因此用户就可以为这些数据转换编写一些特殊的映射函数或应用函数。
Scikit-learn库更多信息:
http://scikit-learn.org/stable/modules/preprocessing.html#encoding-categorical-features
多项式特征生成(Polynomial feature generation)
对于无数的回归建模任务来说,一种常用的增加模型复杂程度的有效方法是增加解释变量的非线性特征。一种简单而常用的方法就是多项式特征,因为它可以得到特征的高阶项和交叉项。而Scikit-learn库中有现成的函数,它可根据给定的特征集和用户选择的最高多项式生成更高阶的交叉项。
更多信息:
http://scikit-learn.org/stable/modules/preprocessing.html#generating-polynomial-features
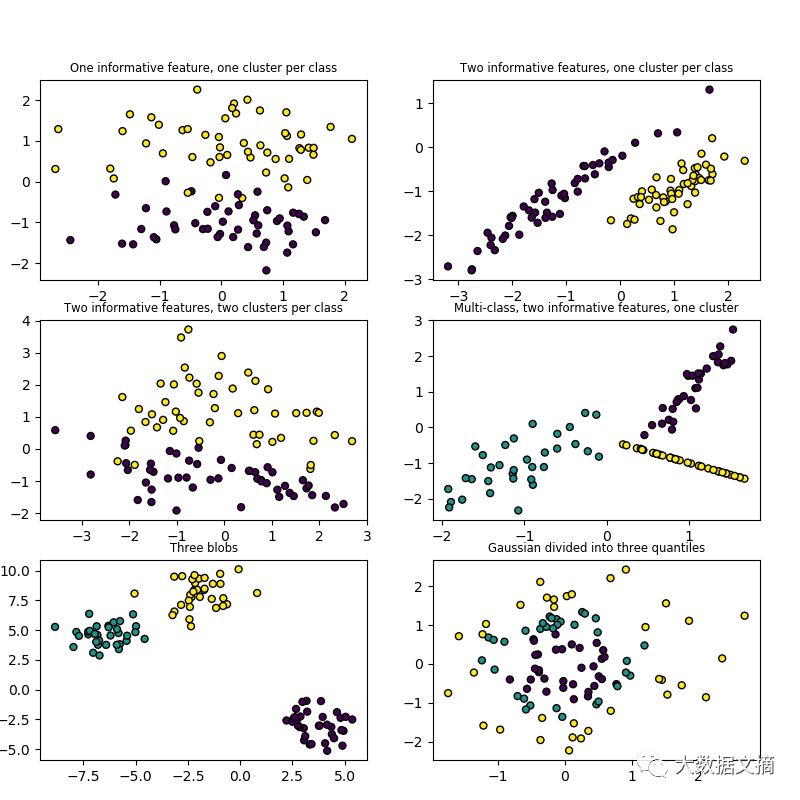
数据集生成器(Dataset generators)
Scikit-learn库包含各种随机样本生成器,可以根据不同大小和复杂程度来构建人工数据集,且具有分类、聚类、回归、矩阵分解和流形测试的功能。
更多信息:
http://scikit-learn.org/stable/datasets/index.html#sample-generators
相关报道:
https://heartbeat.fritz.ai/some-essential-hacks-and-tricks-for-machine-learning-with-python-5478bc6593f2
【今日机器学习概念】
Have a Great Definition

志愿者介绍
回复“志愿者”加入我们








