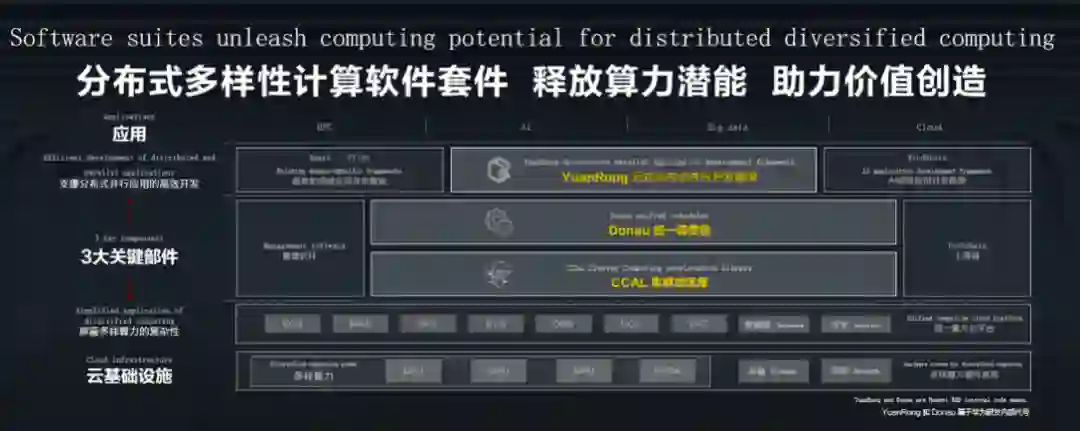
【新智元导读】5G+AI时代的来临,数据量呈爆炸式增长,深度学习模型也越来越大,算力和负载更加多样化,传统模式的调度器已经不能满足需求。为了支持更多的场景,华为研发了统一调度器,突破性的大规模分布式技术和调度算法,可以实现高达90%的资源利用率,百万核MPI 3分钟极速启动。
在自然界,存在各种各样神奇的分工和资源分配形式。
以蚁群为例,看似杂乱无章,成百上千的蚂蚁,却因为某种自发的机制而走向一种极具规律性,每只蚂蚁各司其职,最大限度地发挥了群体的优势。
但有时,蚂蚁这种群体行为也会造成一些麻烦。前一阵,LeCun转发了一条推特,几只蚂蚁找不到家了,结果整个蚁群都陷入了死循环,一直在转圈。
![]()
而同样的道理,计算机集群有时也会面临这种问题,某个节点出了差错,整个集群就无法高效运转,这时就需要一个调度系统。
在计算机中,调度就是一种将任务分配给资源的方法。无论是在单机系统还是分布式集群当中,调度器都是非常核心的组件。
![]()
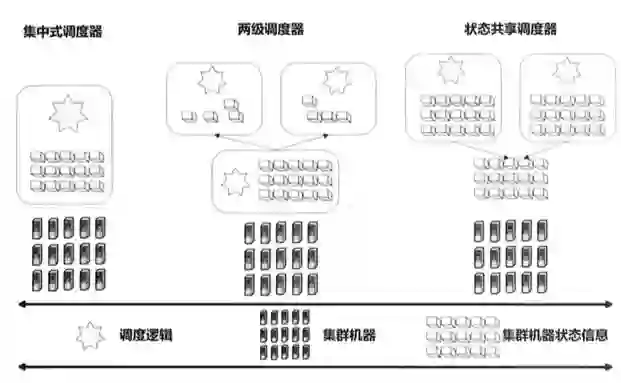
目前市面上的调度器主要有三种类型:集中式调度器、两级调度器、状态共享调度器。
![]()
而这三种模式的调度器都不能适配多种场景,第一种模式相对调度逻辑复杂,但是可以获得比较好的调度结果,第二种有调度效率的限制,不适合大数据场景;第三种会出现大作业饥饿现象,不适合HPC场景。
为了支持多种场景,华为结合了前两种模式研发了统一调度器,并做了优化。
要深入了解统一调度器的优势,我们首先要回顾一下传统模式的调度器。
单机系统的调度器功能相对简单,比如批处理任务、分配内存、定时执行等。
到了分布式系统,任务就变的复杂了
。原来我们只需要关注单个的CPU,进程间或者内核通信都比较简单,但是如果有成千上万台机器,就要考虑机器之间的通讯,遇到延迟或者通讯阻塞该怎么解决。
调度器尤其是大规模分布式系统的调度器,要考虑的远不止这些。
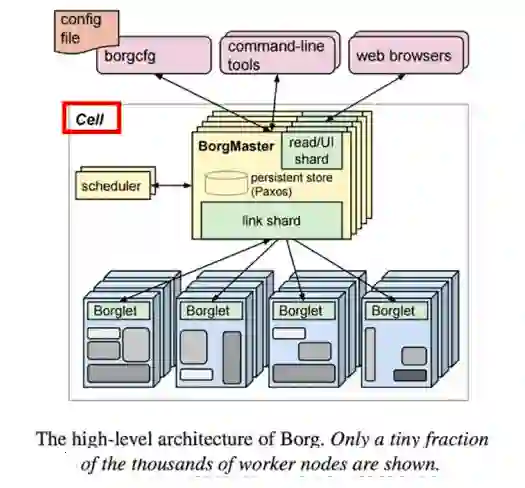
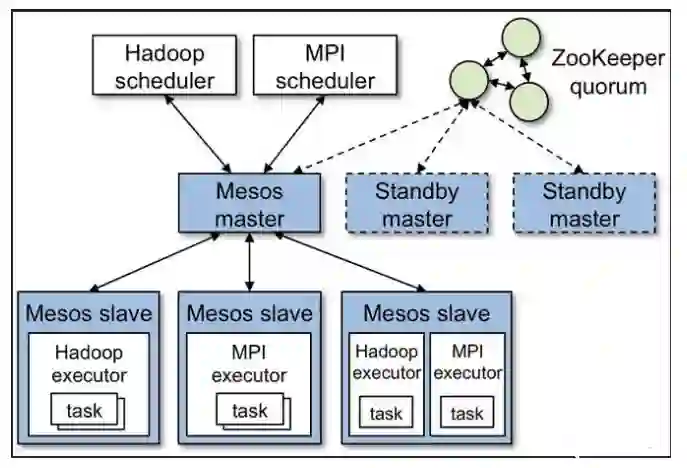
集中式调度器,只有一个单一的调度「总指挥」,在HPC高性能计算方面应用比较广泛。所有的任务和资源调度都在一个实例中完成,所以,集群的规模不能太大。Google的Borg就是一种典型的集中式调度器。
一个 Borg 集群由一个逻辑中央控制器 BorgMaster 和若干代理节点 Borglet 组成,属于集中式调度器。「Borg架构跟黑社会似的,一个老大,多个小弟」。
从Borg的架构可以看出来,
集中式调度器适合吞吐量较大、运行时间较长的任务
,因为资源和任务在同一个实例中进行管理,各个节点的状态容易同步,并发好控制。
但集中式的调度器,调度逻辑全部在中央调度,
逻辑较为复杂,使用起来不够灵活
,不能针对任务做专门优化,新的调度策略嵌入到集中式调度器中二次开发的工作难度较大。
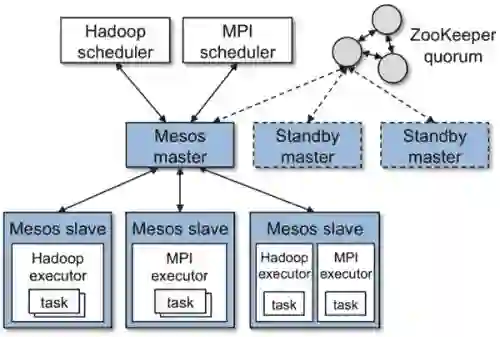
为了解决集中式调度器的调度策略不易调整的问题,两级调度器是一个很好的解决方案,它采用的是一种两级管理机制:
中央调度器
:中央调度器可以纵览全局,集群中所有机器的可用资源都由它来管理。
框架调度器
:各个计算框架在接收到所需资源后,可以根据自身计算任务的特性,使用自身的调度算法,来分配从中央得到的各种资源,Mesos就是一种典型的两级调度器。
两级调度器最大的优势在于
可以针对不同的作业设计不同的调度算法
。在这种两级调度器架构中,只有中央调度器能够观察到所有集群资源的状态,下面的框架并没有一个全局的视野,只能关注自己的一亩三分地。
比如,集群中有很多任务,下发到其中一个节点的任务失败了,是继续在这个节点等待,还是换到其他节点上重新跑,所有的节点都在满负荷运作,而这个任务需要很大的内存,这个节点不知道谁可以帮它,只能原地无脑等待。
另外,Mesos的调度器将资源分配给一个框架后,只能等该框架返回资源使用状态后,才能继续分配这个框架的资源,因此会影响系统的并发性能。
为了解决两级调度器的全局视野和并发问题,Google开发了下一代资源调度系统Omega。
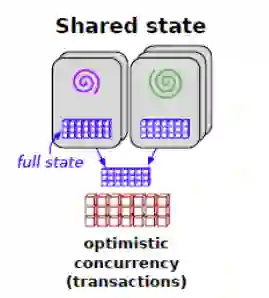
Omega是一种基于共享状态的调度器,该调度器将两级调度器中的集中式资源调度模块
简化成了一些持久化的共享数据(状态)和针对这些数据的验证代码
,这份数据被称为「单元状态」,由「中央调度器」来维护。
有了这些「共享数据」,就能实时了解整个集群的资源使用情况。每个子调度器都有了集群的状态副本,可以看到集群的全部负载信息,当子调度器的资源状态改变时,可以修改「单元状态」信息并同步给其他子调度器。
共享状态架构采用了效率优先的策略,当多个应用程序申请同一份资源时,Omega会把资源给优先级最高的,其他资源限制全部下放到各个子调度器, 弱化了中央调度器的功能。
此外,Omega采用了
基于多版本的并发访问控制方式(也称为「乐观锁」)
,大大提升了Omega的并发性。
如果应用的规模较小,采用集中式调度器可以更好地掌控全局状态;如果应用规模较大,或者需要定制化开发自己的调度算法,可以考虑两级调度器的设计,但是两级调度器逻辑控制较为复杂。
现在的
算力变的多种多样,各种CPU、GPU以及NPU等
,但是如何利用这些多样化的算力,并将算力转化为高性能的分布式应用,面临诸多挑战。
比如,多样性算力如何和应用最佳匹配,分布式应用的并行化性能如何提升,应用性能如何随着系统规模增长而逼近线性增长,融合应用开发带来的学习成本高以及跨系统协同等问题。
![]() 集群数量增加时系统线性度下降管理复杂度提升
针对这些挑战,华为向业界发布了分布式多样性计算软件套件:集群加速库、统一调度器高效释放多样性算力潜力,分布式并行应用开发框架助力分布式应用价值创造。
当分布式系统的规模到达一定程度,调度器的可扩展性就会成为瓶颈。为了提供高可扩展性, 调度器不仅要应对管理数万台机器的挑战,也要能够处理动态增减节点这样的问题。
华为全自研的用于AI、大数据、HPC 混合负载的统一调度器应运而生
。
统一调度器可以
同时管理2万个节点,允许30万并行作业
,实现了大规模的分布式集群调度,规模不再是调度器的限制。
传统的调度器调度算法开发难度大,针对特定任务的调节很不方便,如果不能实现高效的资源调度,那它就失去了本来的价值。而利用统一调度器,可以实现
百万核MPI 3分钟启动,每秒5千个任务的智能调度,在真实工作场景中,每小时可完成4M运行作业量
。
集群数量增加时系统线性度下降管理复杂度提升
针对这些挑战,华为向业界发布了分布式多样性计算软件套件:集群加速库、统一调度器高效释放多样性算力潜力,分布式并行应用开发框架助力分布式应用价值创造。
当分布式系统的规模到达一定程度,调度器的可扩展性就会成为瓶颈。为了提供高可扩展性, 调度器不仅要应对管理数万台机器的挑战,也要能够处理动态增减节点这样的问题。
华为全自研的用于AI、大数据、HPC 混合负载的统一调度器应运而生
。
统一调度器可以
同时管理2万个节点,允许30万并行作业
,实现了大规模的分布式集群调度,规模不再是调度器的限制。
传统的调度器调度算法开发难度大,针对特定任务的调节很不方便,如果不能实现高效的资源调度,那它就失去了本来的价值。而利用统一调度器,可以实现
百万核MPI 3分钟启动,每秒5千个任务的智能调度,在真实工作场景中,每小时可完成4M运行作业量
。
统一调度器在整体架构上实现了调度和执行的分离,调度算法是插件化的,所以在调度阶段,调度算法和执行框架都是可配置的,这样就可以基于场景的特点编排出适应场景的资源调度器。
具体如何实现呢?
首先统一调度器模块划分也更细小,有接入模块、核心作业管理模块、调度模块、执行模块。各个模块之间事件驱动,内部全并行和异步化,既提升了效率,又降低了复杂度。
其次统一调度器不是简单的把调度划分为两层,各层之间无法协调,导致调度效率的低下。调度本质是资源和需求的匹配,匹配可以有多个阶段,每个阶段都有不同的调度侧重点,并且可以设置不同的调度策略。
针对不同的资源池,采用并行化的模式。所以调度阶段之间可以很好的协调,也可以提高效率。调度阶段和策略都可以用户自己配置,或者结合机器学习来做到模式场景的自适应。
所以,统一调度器可以融合多种负载,HPC可以有适配HPC的调度策略和执行框架,AI和大数据也有自己的,但是这些策略和框架都同时存在于一个统一调度器中,能相互协同,使得大规模集群的资源利用率提升到90%。
作为一个底层的调度工具,统一调度器让开发人员从繁杂的调度算法中解脱出来,更加专注于业务的创新,超大规模的集群调度,释放出了前所未有的潜力,以前不敢想、不敢干的深度模型也可以上马一试了。
传统的HPC任务大多是计算密集型的,而新的工作负载(如AI)是数据密集型,负载的多样性对于计算资源的合理分配对开发人员来说也是一个新命题,
不同的用户对HPC、AI等工作负载有着不同的需求
。
超算的用户对HPC了解的比较多,但是缺乏对AI计算的了解,如果有融合计算的需求,往往要与硬件厂家或者外包服务提供商一起定制化开发,而统一调度器消除了这一步骤,无论你是AI用户,还是HPC用户,又或者是大数据分析人员,都能利用统一调度器实现计算资源的智能调度。
现在,高性能计算也希望从海量数据中挖掘更多价值,深度学习的崛起及大规模预训练模型可以帮助优化很多以前无法解决的问题。
人工智能可以帮助高性能计算任务跳出传统的圈子,比如AI可以更好地预测和理解上下文,使用推理来填补数据空白
。
HPC和AI的高效协同工作,不光能提升硬件资源的利用率,未来,还将催生更多的智能计算解决方案。
https://www.yinxiang.com/everhub/note/be221530-b343-436d-a48d-2ab62085e346
https://zhuanlan.zhihu.com/p/33823266
https://draveness.me/system-design-scheduler/
https://matt33.com/2018/09/01/yarn-architecture-learn/#%E4%B8%A4%E7%BA%A7%E8%B0%83%E5%BA%A6%E5%99%A8


 集群数量增加时系统线性度下降管理复杂度提升
集群数量增加时系统线性度下降管理复杂度提升