IBM 研究员带你揭开神秘面纱,使用机器学习如何能更好地评估肝病?
作者:IBM 研究院研究员Uri Kartoun
我是在 2016 年 9 月加入位于坎布里奇的 IBM 研究院的,在此之前,我在麻省总医院 (MGH) 与哈佛的研究员们紧密合作,完成了 3 年的博士后深造。现在,MGH 与 IBM 研究院之间的一项合作取得了令人满意的成果, 我们的手稿“MELD-Plus:一种可普及的肝硬化风险预测评分(A Generalizable Prediction Risk Score in Cirrhosis)”已在 PLOS ONE 上发表。PLOS ONE是一个由同行评审的在线科学期刊。
这次合作可以追溯到近 2 年前,那时我在旧金山举行的 AMIA 年会上展示了一项研究 [1]。完成演讲后,观众向我提问。IBM 研究院的研究员 Kenney Ng 问了一个与一种称为 k-折交叉验证的机器学习技术相关的问题,我感到很意外。通常在此类大会上,人们会要求我们解释是如何执行相关研究的,还从来没有人问我这种明确的方法论问题。我说道:“您的思考方式就像计算机科学家一样。” Kenney 则回复道:“因为我就是计算机科学家!”120 位观众哄堂大笑,然后我回答了 Kenney 的问题。
在 MGH,我花了很大一部分时间对 314,292 位代谢综合征患病风险增加的患者进行了调查 [2]。我与 MGH 和哈佛的同事合作,实践了各种预测建模方法,并结合文本处理技术来更好地理解各种疾病及其并发症。我们重点研究了心血管疾病、失眠症和肝病。研究群体的信息包含 1992 年到 2010 年间在 MGH 或布莱根妇女医院 (BWH) 接受过治疗的患者的完整临床细节。
2014 年末,心脏病专家 Stanley Shaw 博士任研究员期间,在他的实验室接待了我,并向我引荐了肝脏病学家 Kathleen Corey 博士。我开始与 Kathleen Corey 合作对这群患者进行询问,希望在患有肝病和相关并发症的患者中识别与结果相关的新的生物标志物。我们的努力最终让我们发表了多篇研究论文,其中一篇发表在美国胃肠病学杂志上。
在此期间,我查阅了其他研究人员与肝病相关的研究论文,并尝试新的研究方向。我第一次认识到终末期肝病模型 (MELD) 风险评分的重要性,这是医学界最重要且使用最广泛的风险预测评分之一。特别是 2002 年以来,MELD 对确定等待名单上的哪位患者接下来将接受肝脏移植发挥着关键的作用 [3]。
作为研究员,我可以有机会访问更多 MGH 的宝贵数据。这些文献让我颇受启发,我决定尝试识别肝硬化的新生物标志物,据说这是对人类最致命的疾病之一。以前的大部分研究都是根据手动选择的少量生物标志物来预测死亡率,我认为这是一个不错的研究方向。
哈佛综合生物学和临床信息学 (i2b2) 小组的其他研究成果也启发了我,因此我们采取了一种无偏评估的方法来发现生物标志物。在这种方法中,我们使用一种特征选择机器学习算法来查阅大量医疗记录,识别出少数可用于特定医疗结果的最高效预测指标的变量。我们使用了经过充分研究的监督式学习模式来评估准确率;还应用了传统的统计方法来评估这种方法的有效性。我们发现,通过将 MELD 的组件(或其扩展版 MELD-Na 的组件)与多个容易获取的变量相结合,可以构造出一种准确率大约高出10% 的新评分。我们将这种新评分称为 MELD-Plus。
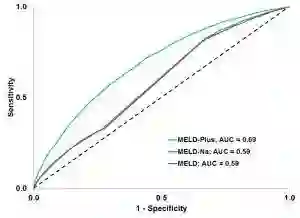
IBM Explorys Network 粗略估计了24,042 位与肝硬化相关的入院患者1 年的死亡率。MELD-Plus 比传统的 MELD 和 MELD-Na 评分更优秀。
加入 IBM 研究院后不久,我就开始与管理 IBM 研究院健康分析小组的 Kenney合作,进一步评估 MELD-Plus。我们在一个名为 IBM Explorys Network 的数据库上部署了原始的 MGH 广义线性模型方程。我们使用了该数据库的部分数据进一步评估 MELD-Plus 的有效性,这部分数据代表了从多个医疗系统获取的约 1800 万位患者信息。
事实证明,同我们所期望的一样, MELD-Plus 比 MELD 和 MELD-Na 更优秀,这与我们将它应用到 MGH/BWH 数据库时的发现类似,准确率进一步提升了。我们相信,在大型电子医疗记录集合上应用机器学习和统计技术,进而在独立数据源上完成进一步验证的方法,可能会改善肝病患者的治疗,因为这种方法能够设计出改进的风险评分机制,为制定更好地监视高风险患者的相关决策提供了基础。令人兴奋的是,PLOS ONE 收录了我们的手稿,希望我们的方法能够提供更准确的工具来评估肝病严重程度,从而推动肝病学领域的不断进步 [4]。
参考文献
Kartoun U、Kumar V、Cheng SC、Yu S、Liao K、Karlson E、Ananthakrishnan A、Xia Z、Gainer V、Cagan A、Savova G、Chen P、Murphy S、Churchill S、Kohane I、Szolovits P、Cai T、Shaw SY。演示在依赖于时间的电子医疗记录上应用数据挖掘技术的优势(Demonstrating the advantages of applying data mining techniques on time-dependent electronic medical records)。美国医学信息学会 2015 年会,2015 年 11 月 14 至18 日,加利福尼亚州旧金山。
Kartoun U. The man who had them all. ACM Interactions 2017;24(4):22–3。
Kamath PS、Kim WR。终末期肝病模型 (MELD)。肝病学 2007;45(3):797–805。
Kartoun U、Corey K、Simon T、Zheng H、Aggarwal R、Ng K、Shaw S。MELD-Plus:一种可普及的肝硬化风险预测评分(A generalizable prediction risk score in cirrhosis)。PLOS ONE 2017(已收录手稿,即将发表)。

点击“阅读原文”,了解更多资讯。



