题目: 属性异质信息网络上的半监督双聚类
期刊: Information Processing & Management (Volume 57, Issue 6)
论文代码: https://github.com/yuduo93/SCCAIN
异质信息网络上的节点聚类被用于许多实际应用。早先的方法独立地针对指定类型的节点进行结构相似性度量而忽视了不同类型节点之间的关联关系。本文研究同时聚合不同类型节点的问题,其目的是挖掘异质节点之间的潜在关联,并同时针对不同类型的节点进行聚类划分。该问题主要面临两个方面的挑战:1. 节点之间的相似性/相关性不仅和结构信息相关,同时也和离散/连续的节点属性相关;2. 聚类和相似性度量往往是相互促进的。为解决以上问题,本文首先利用多条元路径和节点属性,设计了一种融合结构和属性的可学习的整体相关性度量方法。继而,本文提出了属性异质网络半监督双聚类方法SCCAIN,基于约束的正交非负矩阵三分解对不同类型的节点同时进行聚类。最后,我们设计了一种端到端的优化框架,可以联合优化相关性度量和双聚类。在三个真实数据上的实验验证了模型的有效性。
1 引言
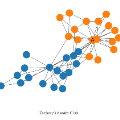
异质信息网络包含了多种类型的节点和边关系,融合了更多的结构信息和语义特征。在异质信息网路的聚类中,如何融合多关系下的节点之间的相似性度量是关键因素。以学术网络来说,作者(A)之间存在合作关系(A-P-A)和共同出席关系(A-P-C-P-A)。最近的一些方法提出融合多条元路径,自动学习不同元路径的权重。这些方法只利用了HIN中的结构信息,而忽视了节点上的属性特征。
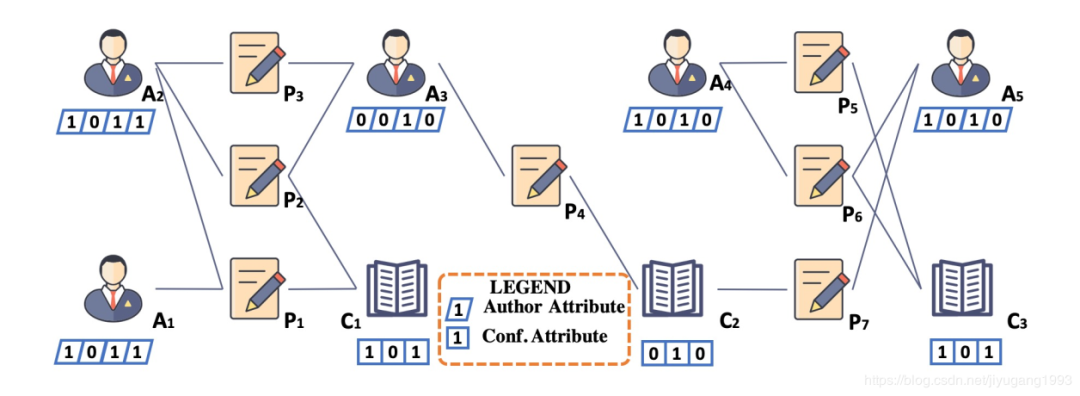
如图1所示,当只考虑结构信息时,基于A-P-A和A-P-C-P-A元路径,作者可以聚合成两类,即
和
。而当额外考虑属性信息时,我们可以更精细地将
和
分离开。
![]()
为了将属性信息进行整合,一种朴素的方案是将所有的属性视作节点,其维度作为节点类型,整合到原始的异质信息网络中。然而,这种方法只能处理离散特征如类别、城市、机构等,而难以刻画连续特征如年龄、合作作者数量等。一种更加合理的设计是将所有的属性信息构建成属性向量,其中每个维度表示一种属性特征。最近的工作,如SCHAIN和SCAN,主要针对相同类型的节点同时进行聚类。而实际上,不同类型的聚簇之间往往具有潜在的关联。例如,会议的聚类结果往往可以促进作者的聚类,反之亦然。
为了同时聚合不同类型的节点以及挖掘不同类型聚簇之间的潜在关联,双聚类/协同聚类是一个较好的选择。与传统聚类方法不同,双聚类利用特征与样本的对偶性,实现特征与样本的同时聚类。此外,双聚类方法能够在不同节点类型的簇之间推导出潜在的对应关系,从而使得到的簇更具可解释性。
-
在异质信息网络中如何同时考虑属性和结构信息进行相关性度量:不同类型的节点之间存在多条非对称的元路径;不同类型的节点属性特征不同,不能直接用欧式距离、余弦相似度等进行度量。
-
如何利用约束信息同时优化相关性度量和双聚类:在异质信息网络中,存在一些约束条件,如must-link和cannot-link的节点对,这些约束条件同时促进了相关性度量和双聚类。如何设计有效的半监督框架,将相关性度量和双聚类进行融合,是另一个挑战。
2 方法
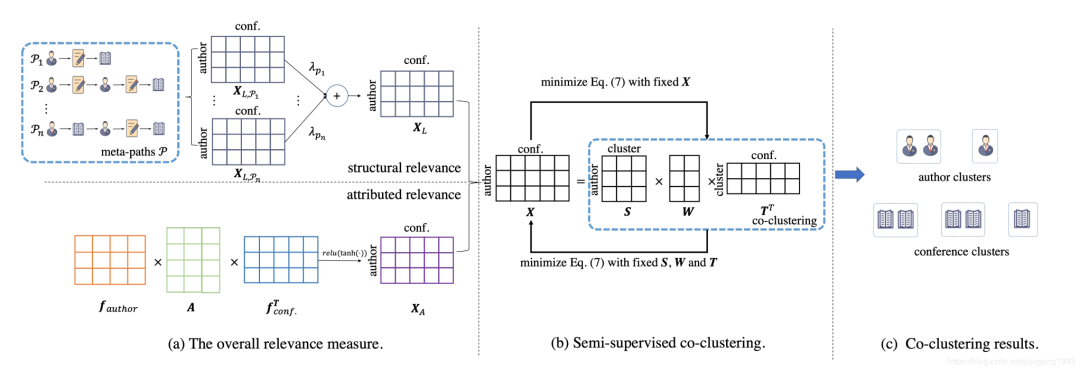
SCCAIN中,我们首先分别提出了异质节点的结构和属性相关性度量,继而设计一种统一的相关性度量方法。其次,我们设计了一种半监督的正交矩阵三分解框架,用于分解不同类型的节点聚类和聚簇相关性挖掘。最后,我们将相关性度量和双聚类融合到一个统一的框架中,迭代优化相关性度量和双聚类。
2.1 相关性度量
结构相关性度量:考虑到节点类型不同,节点之间的结构信息可以通过非对称元路径构成,我们基于HeteSim来度量单一元路径上的相关性,即:
其中,
和
分别表示
类型的节点
和
类型的节点
,
表示构成元路径的关系类型序列。
和
表示出度和入度。考虑到存在多条元路径,我们分别针对每条元路径进行相关性度量,并通过元路径权重参数融合多条元路径,即:
其中,
表示所有元路径的集合,
表示对应的元路径权重,且
。
属性相关性度量:给定
节点的属性特征
,以及
节点的属性特征
,我们通过关联矩阵
将不同类型的属性投影到相同空间度量节点相关性,即:
其中,
表示激活函数,这里我们选取Relu,用于保证相关性取值非负。
整体相关性度量:同时考虑结构相关性和属性相关性,SCCAIN通过平衡因子
将两者融合在一起,构建成整体相关性,即:
其中,
取值为0-1之间,用以保证相关性非负。我们通过must-link 和cannot-link来优化相关参数,其loss value表示为:
其中,
表示监督/约束信息,0表示cannot-link,1表示must-link。
2.2 半监督ONMTF
当给定相关性矩阵时,我们设计了一个半监督非负矩阵正交三分解框架来同时聚合不同类型的节点,并挖掘节点之间的相关性。其公式如下:
其中,
表示相关性矩阵,
,
,
分别表示source节点,target节点的聚类结果以及source聚类和target聚类之间的关联矩阵。这里的
和
具有正交约束,是硬聚类,即不同簇之间没有共同元素。此外,
和
分别表示must-link和cannot-link的约束,当具有must-link/cannot-lin时,取值为1,否则为0.
2.3 联合优化框架
由于相关性度量矩阵和双聚类紧密相关,我们提出联合优化两部分,即最终的loss value由三部分构成:
其中,
表示L2范式约束,用于避免过拟合。在SCCAIN中,我们迭代地优化
和
,分为两步骤。
固定
优化
:当以上更新完成后,我们固定双聚类结果,优化相关性度量参数,则优化的目标值为:
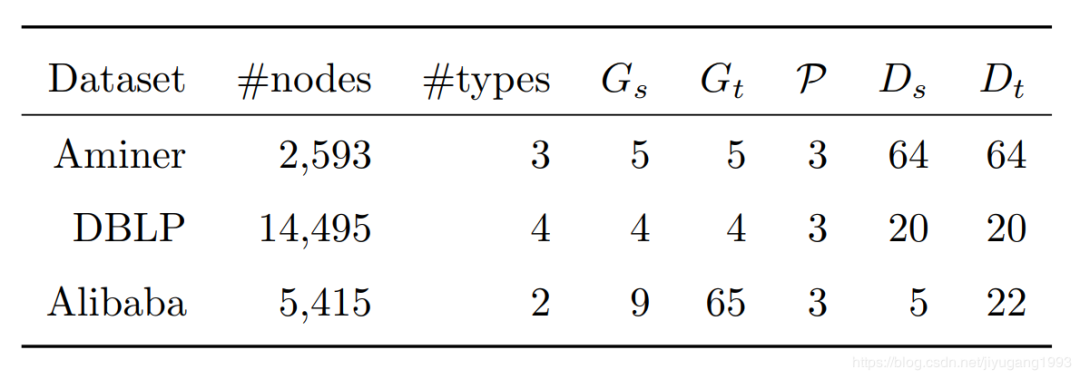
3 实验
我们在Aminer,DBLP和Alibaba等公开数据集上进行了实验。并对双聚类结果进行了可视化分分析。此外,我们对比了只考虑结构和只考虑属性的变种实验,验证了模型的快速收敛特性,最后分析了调节因子
对于模型的影响。
![]()
对比模型选择双聚类DNMTF和CPSSCC,网络表示学习的GCN和HIN2vec,以及ONMTF。在GCN和HIN2vec中,我们将学习到的embedding输入到k-means中进行聚类。在ONMTF中我们选择所有meta-path的相关性的均值作为节点的相关性。
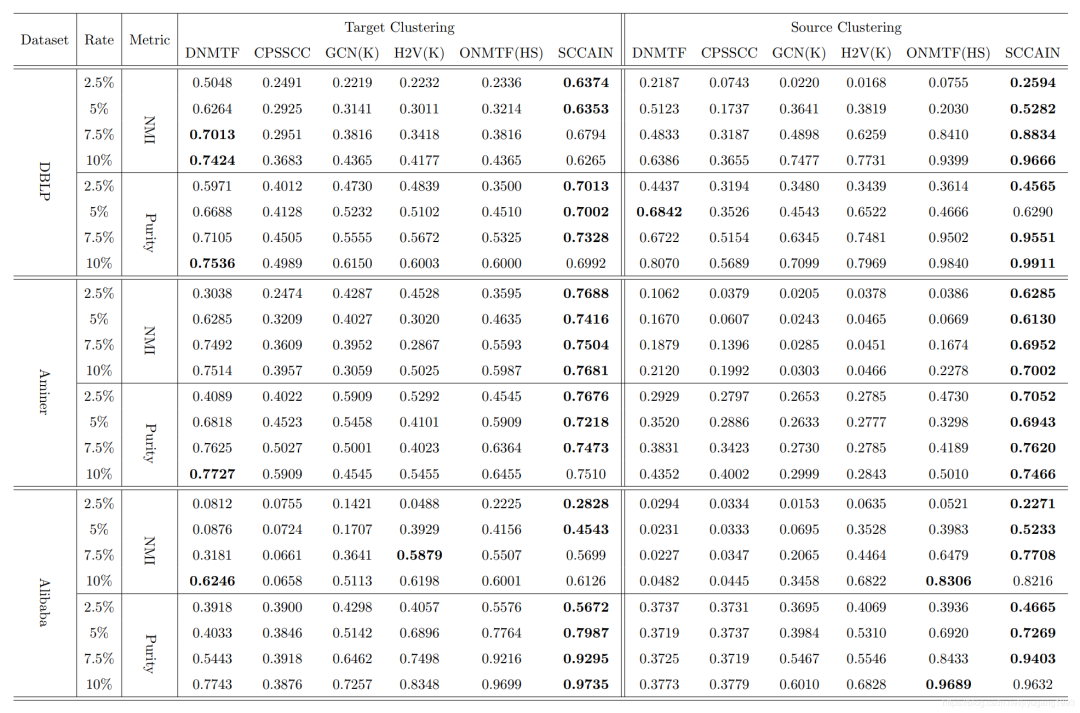
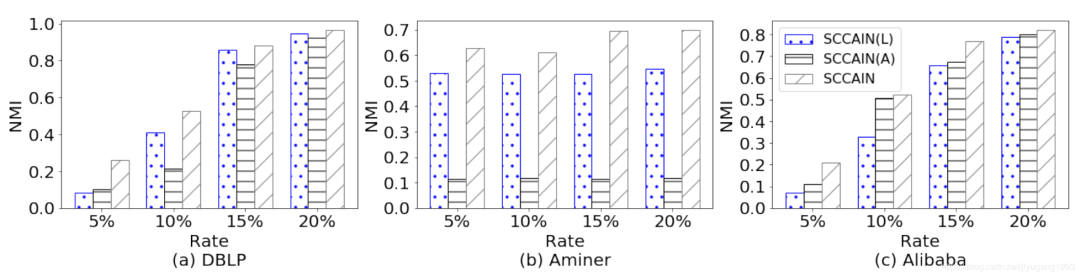
在训练模型时,选择2.5%~10%的监督样本进行训练,度量指标为NMI和Purity。分别度量source的聚类结果和target的聚类结果。对比实验结果如下图所示。
![]()
-
SCCAIN普遍取得了更好的效果。与矩阵分解模型对比,我们提出了一种可学习的度量框架,同时融合了属性信息和结构信息;与网络表示模型对比,我们的模型设计了一种统一的框架来利用异质信息和属性信息。
-
在少量的监督信息时,模型就可以取得较好的效果,这表明模型可以利用更少的监督信息达到较好的效果,而GCN和DNMTF则增长缓慢。
-
与ONMTF相比较,我们模型有明显的提升,其主要原因在于设计了一种高效的整体相关性度量方案。
![]()
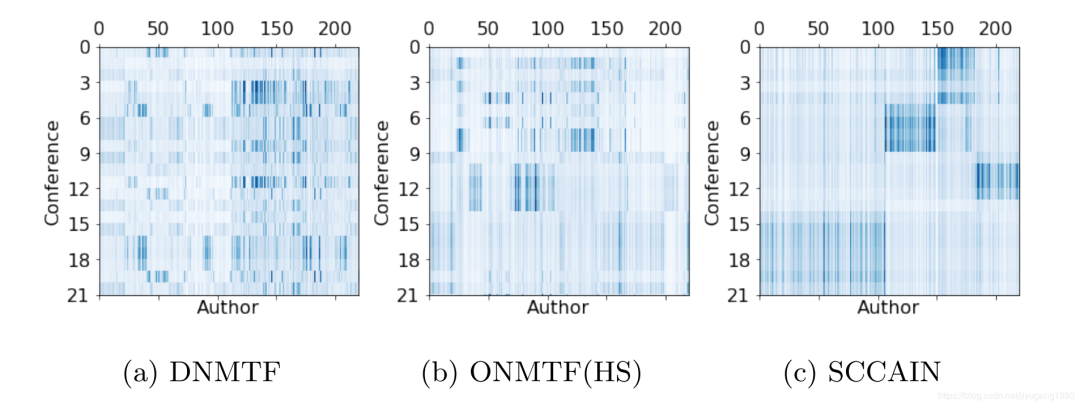
图5. 双聚类可视化效果
我们将SCCAIN的双聚类结果和ONMTF以及DNMTF的双聚类结果进行了可视化。我们将conference和author的聚合结果排序,深色表示相关。从图5中可以看出,相比于DNMTF和ONMTF,SCCAIN可以更好地挖掘conference和author之间的关联特征。
![]()
图6中,我们分别只考虑结构信息和属性信息,设计了相应的变种实验SCCAIN(L)和SCCAIN(A)。分析实验结果可以发现,SCCAIN取得了更好的效果;此外,不同数据集上结构信息和属性信息对于双聚类的贡献程度不同,这表明融合属性信息和结构信息是必要的。
![]()
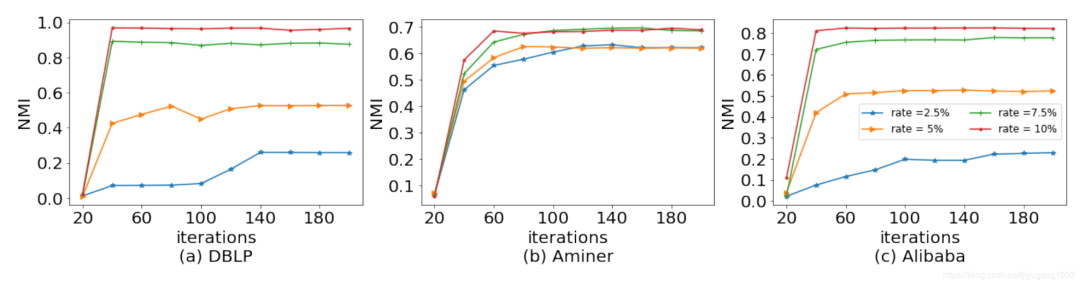
我们对模型的收敛性进行了讨论,迭代次数从0-200,可以看出,随着监督样本的增加模型收敛性持续增强。此外,模型在较小的迭代就可以达到收敛。
![]()
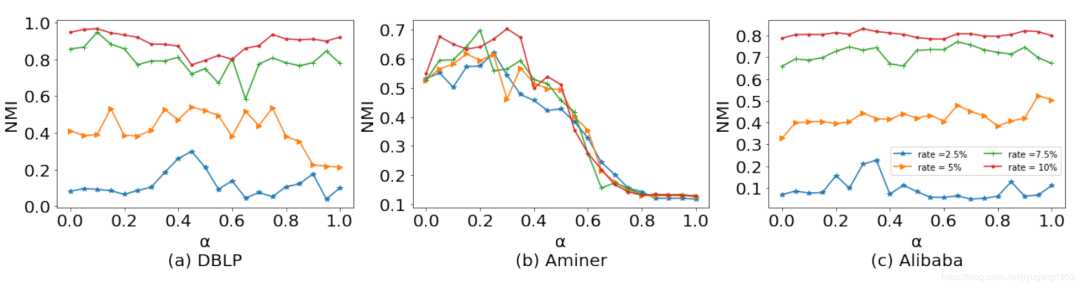
最后,我们调节
从0~1,用以验证模型效果。图8中的结果表明,单一考虑结构信息和属性信息具有局限性。在DBLP和Alibaba中,结构信息和属性信息都具有一定的效果,而在Aminer中单一考虑属性信息效果很差,这侧面证明,同时融合属性信息和结构信息并进行半监督学习可以有效地提升性能。
4 总结
我们提出了一种属性异质信息网络上的双聚类算法,同时考虑结构和属性信息构建现惯性举证,基于半监督ONMTF对不同类型的节点同时进行双聚类。在未来的工作中,我们聚焦于动态属性异质信息网络上的相关性度量和多类型节点聚类。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
![]()
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源