比AlphaGo Zero更强的AlphaZero来了!8小时解决一切棋类!

来源:知乎作者@PENG Bo
读过AlphaGo Zero论文的同学,可能都惊讶于它的方法的简单。另一方面,深度神经网络,是否能适用于国际象棋这样的与围棋存在诸多差异的棋类?MCTS(蒙特卡洛树搜索)能比得上alpha-beta搜索吗?许多研究者都曾对此表示怀疑。
但今天AlphaZero来了(https://arxiv.org/pdf/1712.01815.pdf),它破除了一切怀疑,通过使用与AlphaGo Zero一模一样的方法(同样是MCTS+深度网络,实际还做了一些简化),它从零开始训练:
4小时就打败了国际象棋的最强程序Stockfish!
2小时就打败了日本将棋的最强程序Elmo!
8小时就打败了与李世石对战的AlphaGo v18!
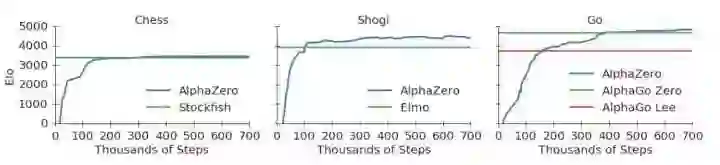
在训练后,它面对Stockfish取得100盘不败的恐怖战绩,而且比之前的AlphaGo Zero也更为强大(根据论文后面的表格,训练34小时的AlphaZero胜过训练72小时的AlphaGo Zero)。

这令人震惊,因为此前大家都认为Stockfish已趋于完美,它的代码中有无数人类精心构造的算法技巧。
然而现在Stockfish就像一位武术大师,碰上了用枪的AlphaZero,被一枪毙命。
在reddit的国象版面的讨论中(Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm • r/chess),大家纷纷表示AlphaZero已经不是机器的棋了,是神仙棋,非常优美,富有策略性,更能深刻地谋划(maneuver),完全是在调戏Stockfish。
喜欢国象的同学注意了:AlphaZero不喜欢西西里防御。
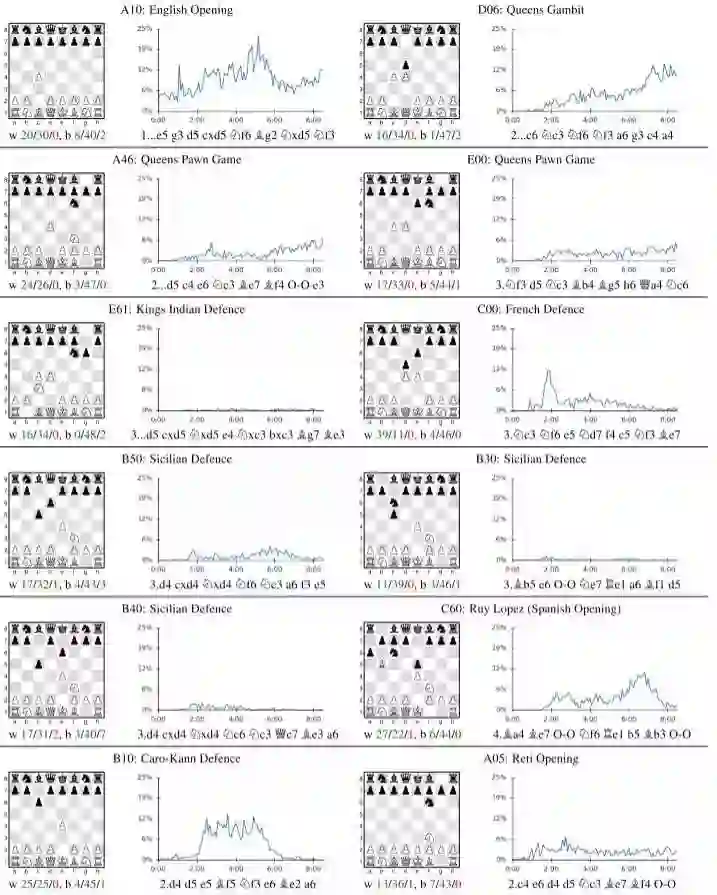
训练过程极其简单粗暴。超参数,网络架构都不需要调整。无脑上算力,就能解决一切问题。
Stockfish和Elmo,每秒种需要搜索高达几千万个局面。
AlphaZero每秒种仅需搜索几万个局面,就将他们碾压。深度网络真是狂拽炫酷。

当然,训练AlphaZero所需的计算资源也是海量的。这次Deepmind直接说了,需要5000个TPU v1作为生成自对弈棋谱。
不过,随着硬件的发展,这样的计算资源会越来越普及。未来的AI会有多强大,确实值得思考。
个人一直认为MCTS+深度网络是非常强的组合,因为MCTS可为深度网络补充逻辑性。我预测,这个组合未来会在更多场合显示威力,例如有可能真正实现自动写代码,自动数学证明。
为什么说编程和数学,因为这两个领域和下棋一样,都有明确的规则和目标,有可模拟的环境。
在此之前,深度学习的调参党和架构党估计会先被干掉...... 目前的很多灌水论文,电脑以后自己都可以写出来。
也许在5到20年内,我们会看到《Mastering Programming and Mathematics by General Reinforcement Learning》。然后许多人都要自谋出路了......
版权归原作者所有,如有侵权请联系小编删除。
📚往期文章推荐

🔗CFP | Virtual Images for Visual Artificial Intelligence
🔗何时机器会掌握常识?Hinton坚持10年内,Lecun说20年
🔗人工智能名人堂第55期 | BP算法之父: Paul J. Werbos
🔗中国工程院院士李正名谏言教育部长:科研评价过于注重论文篇数

德先生公众号 | 往期精选
在公众号会话位置回复以下关键词,查看德先生往期文章!
人工智能|机器崛起|区块链|名人堂
虚拟现实|无人驾驶|智能制造|无人机
科研创新|网络安全|数据时代|人机大战
……
更多精彩文章正在赶来,敬请期待!


点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。