导语
2018 年,来自纽约大学、华盛顿大学、DeepMind 机构的研究者创建了一个多任务自然语言理解基准和分析平台——GLUE(General Language Understanding Evaluation)。GLUE 包含九个英文数据集,目前已经成为衡量模型在语言理解方面最为重要的一个评价体系之一。
然而对于中文 NLP 来说,目前缺少相对应的成熟的平台。针对这个问题,中文 NLP 热心人士发起了 ChineseGLUE(简称为 CLUE)项目。开展 CLUE 项目,一方面希望通过对中文 NLP 资源精心的整合为同学们的工作与研究提升效率,另一方面希望通过建立 leaderboard 榜单机制,为大家提供一个高质量的衡量模型效果的平台,促进模型在中文语言理解能力上的提升。
中文GLUE
相对于英文,中文 NLP 的资源比较匮乏并缺少有价值的整合。相信很多同学在做中文 NLP 相关工作的时候,都遇到过下面这些问题:
上面这些问题会花掉 NLP 同学很多的时间,严重影响工作效率,对初学者来说更是如此。我们宝贵的时间就在这些琐碎的令人头大的事情中流逝过去。
为了解决上述问题,一群热心的同学发起了 ChineseGLUE(简称为 CLUE),它的 Github 地址是:
https://github.com/chineseGLUE/chineseGLUE
https://github.com/CLUEbenchmark/CLUE
ChineseGLUE (CLUE) 如它的名字所示,是中文版的GLUE
[1]
。ChineseGLUE (CLUE) 为大家:1)收集处理了一系列性质各异的中文数据集(不同领域、不同规模、不同难度);2)构建了在线提交评测平台。这个平台能帮助我们横向比较不同的中文 NLP 模型,为大家选择模型提供依据;3)正在整理基准模型,帮助大家轻易地复现经典模型在一系列数据集上的结果。
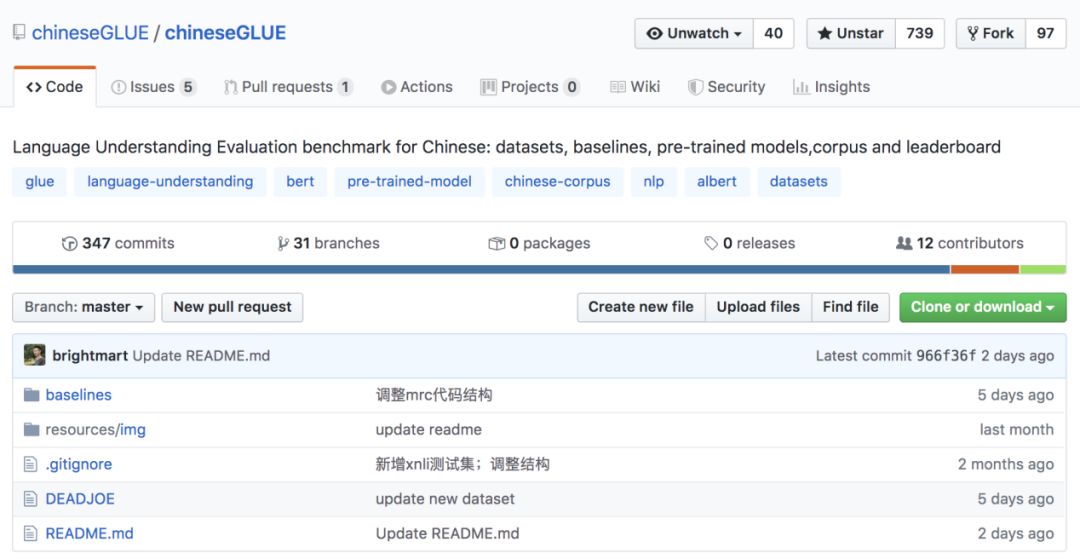
![]()
▲ ChineseGLUE(CLUE)的github截图
希望通过这些工作,让 NLP 同学能把更多的时间放在模型的学习与改进上,而不是浪费在寻找数据集等琐碎的事情之上。除此之外,我们希望 ChineseGLUE (CLUE) 能够以 leaderboard 榜单的形式促进更高质量的中文模型的产生以及针对中文 NLP 的优化。希望 ChineseGLUE 也能像 GLUE 见证 BERT [2],SpanBERT [3],ALBERT [4] 等重要模型出现一样,见证更好的中文 NLP 模型的出现。
ChineseGLUE Leaderboard
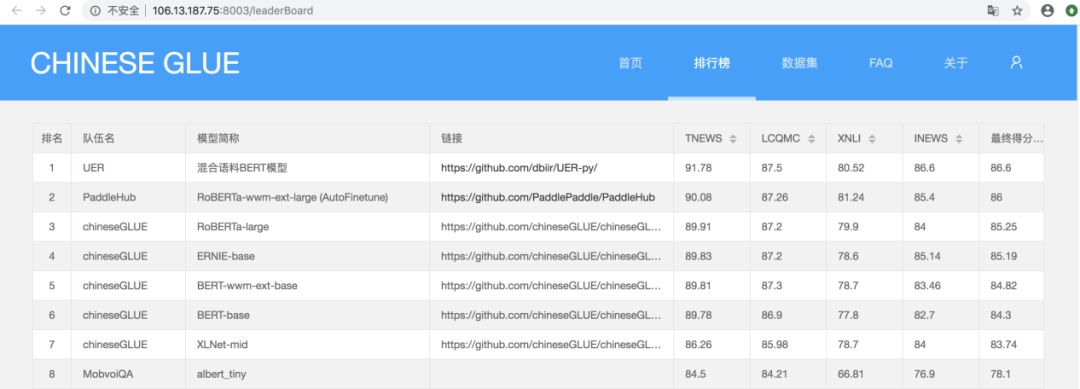
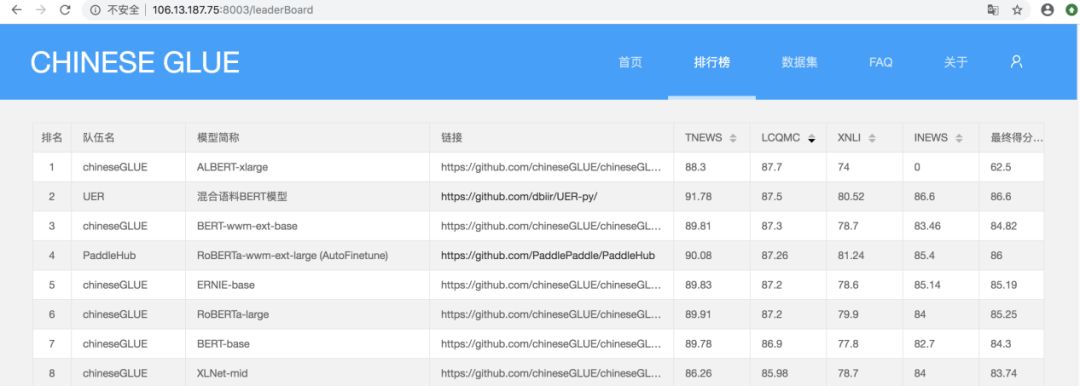
目前,ChineseGLUE 的 leaderboard 已经上线,地址为http://106.13.187.75:8003/leaderBoard。已经相继有队伍在上面验证不同模型的效果,不断提升榜单上的表现。下图展示了目前榜单的情况。通过榜单我们可以得到不少有价值的结论。
![]()
![]()
首先可以看到,目前榜单上已经包括了丰富的 NLP 模型,包括 BERT [2]、 BERT-WWM [5]、RoBERTa [6]、ALBERT [4]、ERNIE [7, 8] 等一系列模型,并且吸引了多个机构在上面提交自己的成绩。通过榜单我们可以看到不同模型在不同数据集上的成绩以及综合成绩(榜单支持针对综合成绩以及不同数据集的成绩进行排序)。这对于我们选择模型是非常重要的参考。
另外,我们可以看到目前榜单上表现最好的模型是混合语料 BERT 模型 [9, 10],是由腾讯 & 人大提供的。这个预训练模型在 BERT-WWM [5] 上叠加预训练,使用了百科类、新闻类、图书类、社交类语料的混合(语料可以从
https://github.com/brightmart/nlp_chinese_corpus 获取)
。
这个预训练模型相对于 Google BERT 已经取得了一定的进步:分别在 TNEWS、LCQMC、XNLI、INEWS 数据集上提升了 2.0/0.6/2.7/3.9 个点的准确率。除了 LCQMC 之外,模型在另外几个数据集上的提升还是很显著的。当然,这个提升相对于英文上的提升还是小了很多 (RoBERTa [7]、ALBERT [4]、Google T5 [11] 在 BERT 的基础上提高了接近 10 个点)。我们也与提交榜单的队伍进行了沟通。
目前 ChineseGLUE (CLUE) 榜单上的结果其实还是比较低的,仍然有巨大的提升空间。目前在预处理、预训练、微调等方面仍有大量的技术可以去尝试,从而进一步提升效果。比如在预处理阶段可以使用数据增强;在预训练阶段可以使用多种预训练模型技术的组合;在微调阶段可以使用半监督的方式微调或者使用多任务微调;最后还可以进行模型的集成。
此外,在计算量和语料方面,虽然榜单上的很多模型都超过了去年 10 月份 Google 推出的中文 BERT-base 模型,但是目前中文模型的计算量和语料大小远远达不到目前英文 SOTA 模型的水准。因此我们非常相信,现在的结果远远没有到达天花板,仍有巨大的进步空间。
PaddleHub RoBERTa-wwm-ext-large (AutoFinetune) 模型在 RoBERTa-wwm-ext-large 的基础上,采用了 Discriminative Fine-tuning 分层学习率策略,同时,模型采用 PaddleHub AutoDL Finetuner 功能进行超参优化,对学习率,分层策略进行自动化搜索,进一步提升了模型性能,模型在 XNLI 数据集上的表现达到了 SOTA 的成绩。
此外,我们也鼓励使用小模型去在榜单上进行提交。后续我们会考虑把参数量、FLOPs 等指标加上,把模型分成不同量级,去比较模型之间的效果。在目前的榜单中,有一个极小的模型 ALBERT_tiny。ALBERT
[4] 通过编码层参数共享和词向量层分解这两项技术减少了模型的参数量,ALBERT_tiny 只有 4M 大小,约是 BERT-base 模型大小的百分之一,但是仍然在一些数据集上取得不错的成绩。
在很多情况下,我们需要对模型的效率和效果进行权衡。在这种情况下,ChineseGLUE 榜单可以给我们提供很好的参考。我们非常期待通过技术的进步,让一个比 BERT 小很多的模型,能在榜单上取得和 BERT 相似甚至更好的成绩。
目前,榜单上的数据集以及提交接口是完全对外开放的,大家可以随时用自己的模型去上面刷榜,验证自己工作的效果。希望后面能看到大家在榜单上激烈的竞争,从而促进中文 NLP 领域的发展。
此外有一点需要注意的是,目前榜单上的测试集是对外开放的(后续我们会维护 privately-held 测试集)。因此建议大家在榜单上拿到 SOTA 效果的同时,不要忘记分享自己模型的改进以及各种细节。这样能让其他人也能受益于您的工作成果,从而更好的促进中文 NLP 领域的发展。目前榜单只包括四个数据集,我们会尽快加入更多的数据集。
未来规划
1. 我们计划在 12 月 5 号前后发布新版的测评基准,包括 12 大任务、基线模型及代码、toolkit(工具包)、测评系统;
2. 继续向大家征集数据集,并(依据数据集领域、规模、难度等因素)从中选出合适的数据集构成 ChineseGLUE (CLUE);
3. 逐步构建 privately-held 测试集,使得 ChineseGLUE (CLUE) 的榜单更加的客观可靠;
4. 根据模型参数数量,FLOPs,语料大小等指标,对模型进行分级。这种方式能够引导我们在提升模型效果的同时也考虑到效率,而不是一味的追求大语料和大计算量。
结语
得益于热心中文 NLP 人士的努力和关注,ChineseGLUE (CLUE) 慢慢成长起来,在 Github 上突破了 700 星,并收到了很多留言与反馈。我们深知 ChineseGLUE 是一个长期的、复杂且琐碎的工作。为此我们制定了详细的发展规划。在未来的工作中,我们会继续努力,严格把关项目质量,为中文 NLP 模型提供一套可靠的评价指标,以及一个易于使用,良性竞争的平台。希望 ChineseGLUE (CLUE) 的工作能为中文 NLP 领域的发展做出一些贡献。
参考文献
[1] Wang A, Singh A, Michael J, et al. Glue: A multi-task benchmark andanalysis platform for natural language understanding[J]. arXiv preprintarXiv:1804.07461, 2018.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deepbidirectional transformers for language understanding[J]. arXiv preprintarXiv:1810.04805, 2018.
[3] Joshi M, Chen D, Liu Y, et al. Spanbert: Improving pre-training byrepresenting and predicting spans[J]. arXiv preprint arXiv:1907.10529, 2019.
[4] Lan Z, Chen M, Goodman S, et al. Albert: A lite bert forself-supervised learning of language representations[J]. arXiv preprintarXiv:1909.11942, 2019.
[5] Cui Y, Che W, Liu T, et al. Pre-Training with Whole Word Maskingfor Chinese BERT[J]. arXiv preprint arXiv:1906.08101, 2019.
[6] Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bertpretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
[7] Sun Y, Wang S, Li Y, et al. ERNIE: Enhanced Representation throughKnowledge Integration[J]. arXiv preprint arXiv:1904.09223, 2019.
[8] Sun Y, Wang S, Li Y, et al. Ernie 2.0: A continual pre-trainingframework for language understanding[J]. arXiv preprint arXiv:1907.12412, 2019.
[9] https://github.com/dbiir/UER-py/
[10] Zhao Z, Chen H, Zhang J, et al. UER: An Open-Source Toolkit forPre-training Models[J]. arXiv preprint arXiv:1909.05658, 2019.
[11] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits oftransfer learning with a unified text-to-text transformer[J]. arXiv preprintarXiv:1910.10683, 2019.
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
▽ 点击 | 阅读原文 | 访问项目主页