不要再用arxiv链接了!为了让论文引用更规范,上交毕业生、南加州大学华人博士创建了一个小工具
机器之心报道
只需两步,将文献的 arXiv 信息转换为正式来源信息。
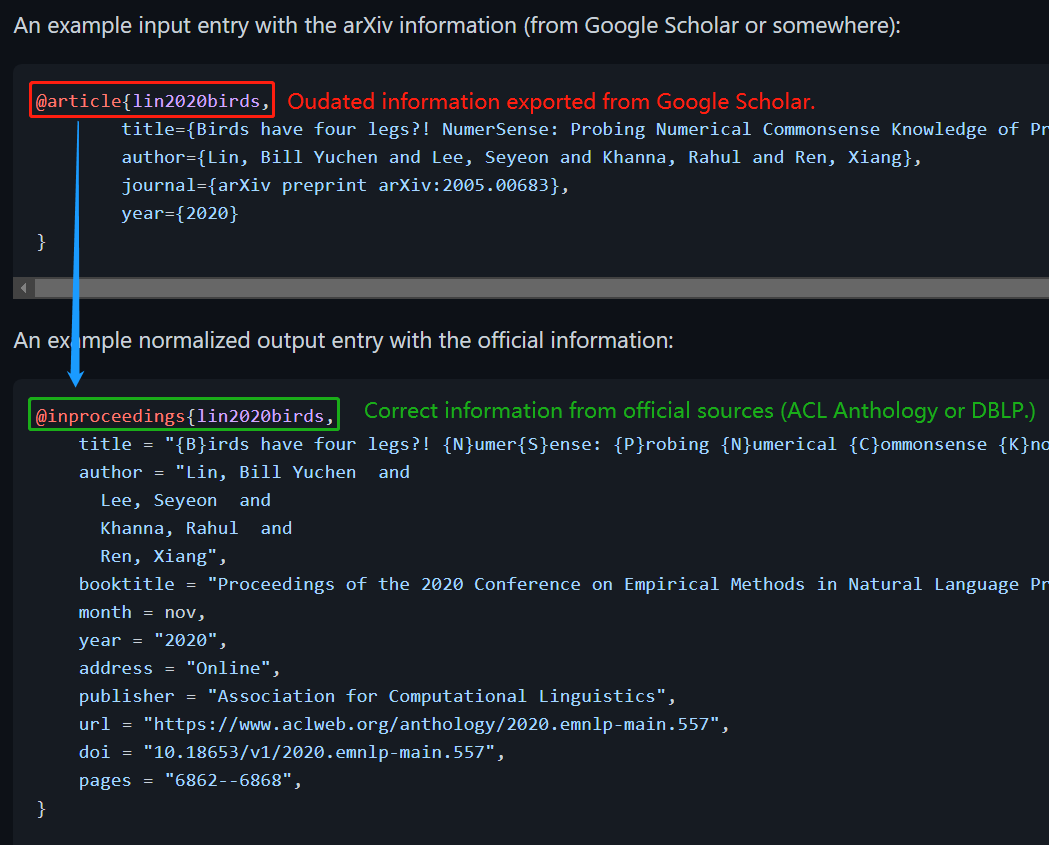
git clone https://github.com/yuchenlin/rebiber.gitpip install bibtexparser tqdmcd rebiber
python normalize.py -i example_input.bib -o example_output.bib -l bib_list.txt
报告内容涵盖人工智能顶会趋势分析、整体技术趋势发展结论、六大细分领域(自然语言处理、计算机视觉、机器人与自动化技术、机器学习、智能基础设施、数据智能技术、前沿智能技术)技术发展趋势数据与问卷结论详解,最后附有六大技术领域5年突破事件、Synced Indicator 完整数据。
识别下方二维码,立即购买报告。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

专知会员服务
16+阅读 · 2019年10月25日
Arxiv
5+阅读 · 2020年10月6日
Arxiv
6+阅读 · 2018年4月12日





相关VIP内容
专知会员服务
16+阅读 · 2019年10月25日
相关资讯
相关论文
Arxiv
5+阅读 · 2020年10月6日
Arxiv
6+阅读 · 2018年4月12日