“来自蒙娜丽莎的凝视”— 结合 TensorFlow.js 和深度学习实现

客座博文 / Emily Xie,软件工程师
背景
坊间传闻,当您在房间里走动时,蒙娜丽莎的眼睛会一直盯着您。
这就是所谓的“蒙娜丽莎效应”。兴趣使然,我最近就编写了一个可互动的数字肖像,通过浏览器和摄像头将这一传说变成现实。

这个项目的核心是利用 TensorFlow.js、深度学习和一些图像处理技术。总体思路如下:首先,我们必须为蒙娜丽莎的头部以及从左向右注视的眼睛生成一系列图像。从这个动作池中,我们根据观看者的实时位置连续选择并显示单个帧。
TensorFlow.js
https://tensorflow.google.cn/js
接下来,我将从技术层面详细介绍该项目的设计和实现过程:
通过深度学习为蒙娜丽莎添加动画效果
图像动画是一种调整静止图像的技术。使用基于深度学习的方式,我可以生成极其生动的蒙娜丽莎注视动画。
具体来说,我使用了 Aliaksandr Siarohin 等人在 2019 年发布的一阶运动模型 (First Order Motion Model, FOMM)。直观地讲,此方法由两个模块构成:一个模块用于提取运动,另一个模块用于生成图像。运动模块从摄像头记录的视频中检测关键点并进行局部仿射变换 (Affine Transformation)。然后,将在相邻帧之间这些关键点的值的差值作为预测密集运动场的网络的输入,并且用作遮挡掩模 (Occlusion Mask),遮挡掩模可以指定或根据上下文推断需要修改的图像区域。之后,图像生成网络会检测面部特征,并生成最终输出,即根据运动模块结果重绘源图像。
一阶运动模型
http://papers.nips.cc/paper/8935-first-order-motion-model-for-image-animation.pdf
我之所以选择 FOMM 是因为它易于使用。此领域以前使用的模型都“针对特定目标”:需要提供详细的特定目标数据才能添加动画效果,而 FOMM 则不需要知道这些数据。更为重要的是,这些作者发布了开箱即用的开源实现,其中包含预先训练的面部动画权重。因此,将该模型应用到蒙娜丽莎的图像上就变得十分简单:我只需将仓库克隆到 Colab Notebook,生成一段我眼睛四处观看的简短视频,并将其与蒙娜丽莎头部的屏幕截图一起传进模型。得到的影片超级棒。我最终仅使用了 33 张图片就完成了最终的动画的制作。

源视频和 FOMM 生成的图像动画预测示例

使用 FOMM 生成的帧示例
图像融合
虽然我可以根据自己的目的重新训练该模型,但我决定保留 Siarohin 得到的权重,以免浪费时间和计算资源。但是,这意味着得到的帧的分辨率较低,且输出仅有主体的头部。介于我希望最终图像包含整个蒙娜丽莎,即包括手部、躯干和背景,我选择将生成的头部动画叠加到油画图像上。

头部帧叠加到基础图像上的示例:为了说明问题,此处显示的版本来自项目的早期迭代,其中头部帧存在严重的分辨率损失
然而,这带来了一系列难题。查看上述示例时,您会发现,模型输出的分辨率较低(由于经过了 FOMM 的扭曲程序,背景附带有一些细微的更改),从而导致头部帧在视觉上有突出的效果。换句话说,很明显这是一张照片叠加在另一张照片上面。为了解决这个问题,我使用 Python 对图像进行了一些处理,将头部图像“融合”到基础图像中。
首先,我将头部帧重新 resize 到其原始分辨率。然后,我构造一个新的帧,该帧的每个像素值由原图像素和模型输出的像素求均值后加权 (alpha) 求得,离头部中心越远的像素权值越低。
用于确定 alpha 的函数改编自二维 sigmoid,其表达式为:
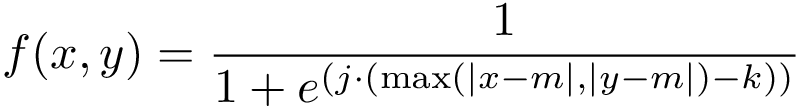
其中,j 确定逻辑函数的斜率,k 为拐点,m 为输入值的中点。以下是函数的图形表示:
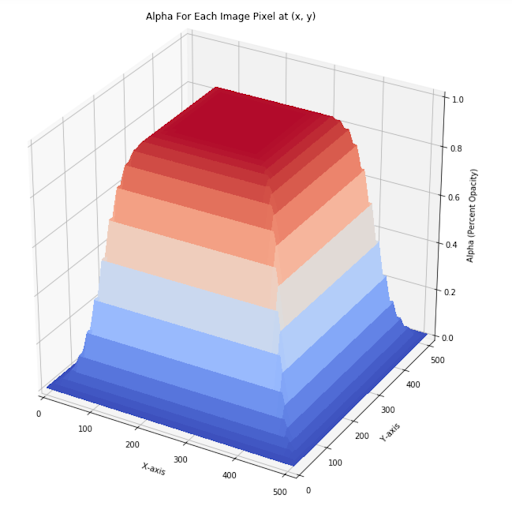
我将上述过程应用到动画集中的所有 33 个帧之后,得到的每个合成帧都会让人深信不疑这就是一个图像:

通过 BlazeFace 跟踪观看者的头部
此时,剩下的工作就是确定如何通过摄像头来跟踪用户并显示相应的帧。
当然,我选择了 TensorFlow.js 来完成此工作。这个库提供了一组十分可靠的模型,用于检测人体,经过一番研究和思考后,我选择了 BlazeFace。
BlazeFace
https://github.com/tensorflow/tfjs-models/tree/master/blazeface
BlazeFace 是基于深度学习的目标识别模型,可以检测人脸和面部特征。它经过专门训练,可以使用移动相机输入。它特别适合我的这个项目,因为我预计大部分观看者都会以类似方式(即头部位于框内、正面拍摄以及非常贴近相机)使用摄像头,无论是使用移动设备还是笔记本电脑。
但是,在选择此模型时,我最先考虑到的是它异常快的检测速度。为了让这一项目有意义,我必须能够实时运行整个动画,包括面部识别步骤。BlazeFace 采用 Single-Shot 检测 (SSD) 模型,这是一种基于深度学习的目标检测算法,在网络的一次正向传递中可以同时移动边界框并检测目标。BlazeFace 的轻量检测器能够以每秒 200 帧的速度识别面部特征。

BlazeFace 在给定输入图像时的捕获内容演示:包围人体头部以及面部特征的边界框
选定模型后,我持续将用户的摄像头数据输入 BlazeFace 中。每次运行后,模型都会输出一个含有面部特征及其相应二维坐标位置的数组。借助此数组,我计算两只眼睛之间的中点,从而粗略估算出面部中心的 X 坐标。
最后,我将此结果映射到介于 0 与 32 之间的某个整数。您可能还记得,其中的每一个值分别表示动画序列中的一个帧,0 表示蒙娜丽莎的眼睛看向左侧,32 表示她的眼睛看向右侧。之后,就是在屏幕上显示结果了。
欢迎您亲自尝试!
您可以在 monalisaeffect.com 上玩一玩这个项目。要想关注我的更多作品,请随时访问我的个人网站或GitHub。
个人网站
https://xie-emily.com/GitHub
https://github.com/emilyxxie
致谢
感谢 Andrew Fu 阅读本文并给我提出反馈意见,感谢 Nick Platt 耐心倾听并就前端错误给出建议,感谢 Jason Mayes 及 Google 团队的其余工作人员参与本项目并使其得到增强。
点击 “阅读原文” 立即体验!





