业界 | 英伟达的新GPU来了,FPGA和ASIC要扔掉吗?
AI科技评论消息,美国时间5月10日,NVIDIA CEO黄仁勋在开发者大会GTC2017上发布新一代GPU架构Volta,首款核心为GV100,采用台积电12nm制程,最大亮点是成倍提升了推理性能,意欲在目前称霸机器学习训练场景的基础上,在推理场景也成为最佳商用选择。
GV100 GPU


据AI科技评论了解,Volta架构GV100 GPU采用台积电(TSMC)12nm FFN制程,具有5120个CUDA核心。相比上一代16nm制程的Pascal架构GPU GP100,晶体管数目增加了38%,达到了惊人的211亿个;核心面积也继续增加33%,达到令人生畏的815mm2,约等于一块Apple Watch的面积,据黄仁勋称这样的面积已经达到了制造工艺极限。随着核心的增大,GV100的单、双精度浮点性能也大幅提升了41%。然而这还不是重点,为了满足GPU在机器学习中的性能需求,Volta架构中引入了新的张量运算指令Tensor Core,让机器学习中训练速度提升约3倍、推理性能提升约10倍(相比上一代自家GPU GP100)。
GV100搭载在TESLA V100开发板上亮相,配合来自三星的16GB HBM2显存,显存带宽也达到了900GB/s之高。
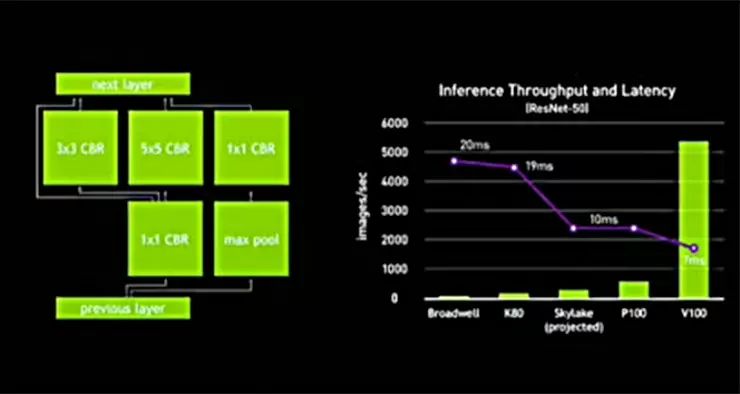
根据现场演讲PPT,推理场景下,V100比上一代搭载GP100 CPU的P100板卡,图像处理能力提升了约10倍,延迟也下降了约30%。在这样的性能提升之下,GPU已经可以让FPGA和ASIC几乎没有用武之地,在商用场景中几乎满足全部计算需求。(详细分析见文末)
DGX-1V、DGX Station![]()


随着GV100 GPU发布,NVIDIA的深度学习超级计算机也进行了升级。老款DGX-1把原有Pascal GPU升级为Volta GPU,名字也更新为DGX-1V。它内置八块 Tesla V100开发板,合计显存128G、运算能力为 960 Tensor TFLOPS,即将迈入下一个时代。黄仁勋表示,过去 Titan X 需花费八天训练的神经网络,用 DGX-1V 只需八个小时。它相当于是“把 400 个服务器装进一个盒子里”。
DGX Station 则是缩小版的 DGX-1V,黄仁勋称其为“Personal DGX”,堪称是终极个人深度学习电脑,各方面指标均为DGX-1V的一半,但仍然已经非常强大。英伟达内部使用DGX Station已经很久,每个工程师要么有 DGX-1V,要么有 DGX Station,再要么两个都有。既然它确实能够满足工程师的需求,英伟达决定把这款产品推广给公众市场。
NVIDIA意图通过GV100完全称霸机器学习硬件市场
据AI科技评论了解,机器学习中需要用到高计算性能的场景有两种,一种是训练,通过反复计算来调整神经网络架构内的参数;另一种是推理,用已经确定的参数批量化解决预定任务。而在这两种场景中,共有三种硬件在进行竞争,GPU、FPGA和ASIC。
GPU(以前是Graphics Processing Unit图形计算单元,如今已经是General Processing Unit通用计算单元)具有高的计算能力、高级开发环境、不影响机器学习算法切换的优点,虽然同等计算能力下能耗最高,但仍然在算法开发和机器学习训练场景中占据绝对的市场地位。
FPGA(Field-Programmable Gate Array,现场可编程矩阵门)是一种半成型的硬件,需要通过编程定义其中的单元配置和链接架构才能进行计算,相当于也具有很高的通用性,功耗也较低,但开发成本很高、不便于随时修改,训练场景下的性能不如GPU。
ASIC(Application Specific Integrated Circuits,专用集成电路)是根据确定的算法设计制造的专用电路,看起来就是一块普通的芯片。由于是专用电路,可以高效低能耗地完成设计任务,但是由于是专用设计的,所以只能执行本来设计的任务,在做出来以后想要改变算法是不可能的。谷歌的TPU(Tensor Processing Unit张量处理单元)就是一种介于ASIC和FPGA之间的芯片,只有部分的可定制性,目的是对确定算法的高效执行。
所以目前的状况是,虽然GPU在算法开发和机器学习训练场景中占有绝对地位;但是由于FPGA和ASIC在任务和算法确定的情况下,在长期稳定大规模执行(推理)方面有很大优势,所以GPU跟FPGA和ASIC之间还算互有进退,尤其GPU相同性能下功耗很高,对大规模计算中心来说电费都是很高的负担。但随着GV100对推理计算能力的约10倍提升,商用场景下已经没有必要为了推理场景更换硬件了,同一套GPU可以在训练场景的计算能力和推理场景的计算能力同时达到同功耗下最佳,还具有最好的拓展和修改能力,简直别无所求。
面对提升如此明显的GPU,一众投身机器学习硬件的FGPA和ASIC厂商前景令人担忧。也许现在唯一能让他们松口气的就是GV100 GPU的量产出货时间要到2017年三四季度。等2018年,希望大规模部署后的GV100能用成倍提升后的性能给我们带来新的惊喜。
报名 |【2017 AI 最佳雇主】榜单

在人工智能爆发初期的时代背景下,雷锋网联合旗下人工智能频道AI科技评论,携手《环球科学》和 BOSS 直聘,重磅推出【2017 AI 最佳雇主】榜单。
从“公司概况”、“创新能力”、“员工福利”三个维度切入,依据 20 多项评分标准,做到公平、公正、公开,全面评估和推动中国人工智能企业发展。
本次【2017 AI 最佳雇主】榜单活动主要经历三个重要时段:
2017.4.11-6.1 报名阶段
2017.6.1-7.1 评选阶段
2017.7.7 颁奖晚宴
最终榜单名单由雷锋网、AI科技评论、《环球科学》、BOSS 直聘以及 AI 学术大咖组成的评审团共同选出,并于7月份举行的 CCF-GAIR 2017大会期间公布。报名期间欢迎大家踊跃自荐或推荐心目中的最佳 AI 企业公司。
报名方式
如果您有意参加我们的评选活动,可以点击【阅读原文】,进入企业报名通道。提交相关审核材料之后,我们的工作人员会第一时间与您取得联系。
【2017 AI 最佳雇主】榜单与您一起,领跑人工智能时代。





