微博在大规模、高负载系统问题排查方法。文尾有彩蛋

秦迪,微博平台及大数据技术专家,2013年加入微博,负责微博视频服务、通讯服务等核心系统的设计和研发、微博平台基础工具的开发和维护,并负责微博平台的架构改进工作,在工作中擅长排查复杂系统的各类疑难杂症。爱折腾,喜欢研究从内核到前端的所有方向,近几年重点关注大规模系统的架构设计和性能优化,重度代码洁癖:以code review为己任,重度工具控:有现成工具的问题就用工具解决,没有工具能解决的问题就写个工具解决。业余时间喜欢偶尔换个语言写代码放松一下。
背景
首先来介绍一下背景,微博主要面对的是高并发、大数据量、高负载的业务压力,并且伴随着热点事件会有突发的请求峰值。作为典型的互联网后端服务之一,微博平台部署了大规模的基于Linux系统的集群,使用Java作为主要语言,使用了一些外部的框架比如Tomcat、Storm、Hbase等,也应用了一些自研的系统,比如RPC框架Motan、服务发现Config Service等。不同企业和行业采用的方案可能有区别,但从问题排查这个角度来说都是类似的。
排查方法及线索
相比于设计系统或者编码,问题排查可以说是一个反向推导的过程,这个过程往往比理解原因或者解决问题复杂。
例1:邻居家的小孩很调皮,有一天拿弹弓玩,把我家玻璃打破了,这是个正向的推导逻辑,很好理解。但是反过来,我到回家,看到玻璃破了,想知道原因,这个过程就要复杂得多。
对于影响线上系统可用性的问题,都可以总结成这样一种模式:一个根本原因,经过一条或几条传播路径,最后表现出某些现象。
例2:某服务由于内存泄漏,导致操作系统消耗swap了、处理变慢、依赖它的服务超时、处理线程堆积,最终导致它的服务不可用。在这个例子中,内存泄漏是根本原因,服务不可用是现象,其他都是传播路径。
但原因、路径和现象不是一一对应的,我在以往排查问题的过程中,遇到的绝大多数都不是完全相同的问题,比如表现相同的问题,原因和路径完全不一样。或者是相同的原因通过不同路径表现出不同的现象。
例3:关于应用吃swap的问题,原因可以是堆外内存泄漏,可以是机器上启动了其他消耗内存的程序,还可以是numa配置引发的。同样,堆外内存泄漏可能导致吃swap,也可能导致OOM,还可能什么现象都没有。
所以单纯地看一些案例,了解“A会引发B”,对于今后问题排查来说会有一些帮助,但是帮助不大,在实际排查的过程中很多案例不能直接通过现象得出原因。更进一步,可以通过某个案例去了解“在出现B现象时,我可以通过某某手段去分析”,这种学习手段的办法会好一些,但是还不够。
随着新技术的使用和越来越高的访问峰值,新的问题层出不穷,如果在工作中经常引入新技术,必然会碰到无法通过现有案例解释的问题,此时更多是学习一些解决问题的思路。
现在还是回到本节的内容——排查问题。
我理解的排查就是一步步地收集线索、分析线索最终定位原因的过程,本节要讲的是如何更有效地发现和利用线索。总的来说,可以把问题排查分成以下这3个方面。
1.known-known
就是你想要知道,并且已经获取到的一些信息。比如日志业务表现、监控图上反映出来的信息。一般来说,比较容易获取的信息大概有以下这些。
服务表现:问题的具体表现(出错、超时等)、应用日志、依赖服务的状态等。
系统状态:操作系统指标(系统管理的各种资源的状态、系统日志等)、VM指标(主要是GC)。
硬件指标:CPU、内存、网络、硬盘是否达到瓶颈。
我们主要是通过框架定制+自研/开源工具的方式来获取上面说的几类信息,比如业务相关的指标是通过框架层输出日志+ELK/graphite之类生成图形。下图是Graphite做的业务监控图。
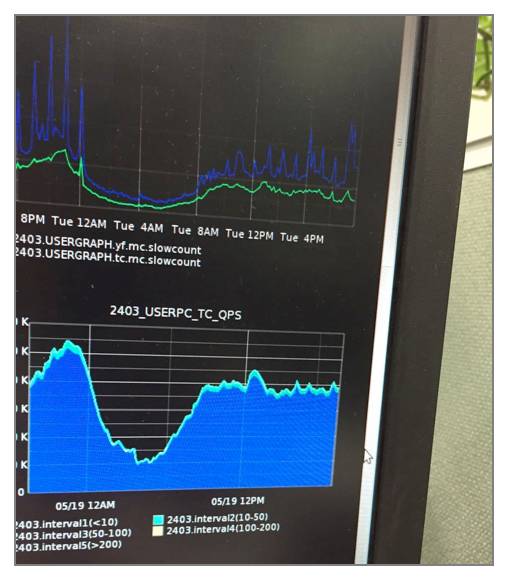
系统的监控用的是新浪内部的监控系统,也可以用开源的工具,比如Cacti/Zabbix,这里就不展开讲了。
一般的监控系统应该可以提供上面这些信息,而对于分布式的系统来说,除了上面这些独立的监控数据外,还有一个非常重要的线索,就是已知数据的定量分析和归类,比如重现概率、时间点、问题的共同特征。这些线索非常有可能因为描述得不够清楚而被忽略,但在实际排查中却很有价值。
比如“不是全部请求都出错”,或者“刚才数据库和Web服务都出问题了”之类的描述,如果换成“线上请求有1/3出错,都是电信用户的请求”或者“Web服务18:12:11开始报异常,数据库18:12:30开始出现慢请求”,效果是不一样的。
例4:以前出现过一次线上未读数偶发清不掉的问题。出现问题时没有发现明显的异常,日志也没有问题,当时我们重启了前端服务,但是没有效果。之后我们统计了一下1分钟内出现问题的请求占正常请求的比例,大约是1/8,而这个服务依赖的另一个服务正好是8个实例,于是我们进一步统计出问题的请求,果然都调用到了同一个实例,于是当时下掉了这个可能有问题的实例,服务就恢复了。在之后通过进一步分析有问题的实例,定位了原因。
总结一下关于known-known类的线索:主要是在不丢失信息的情况下,对信息做定量和归类分析,定位进一步的排查方向。
2.known-unknown
这是指你想要知道但目前还不知道的信息,一般指不能直接看到的信息。可能你会疑惑为什么会有这个分类,它跟上面有什么区别。
例5:应用出现了慢请求问题,业务逻辑的处理时间好像没问题,假设这个时候我记起曾看到TCP文章里说socket有个接收队列,我隐约感觉问题可能出现在这里,应该看看有没有堆积,但是却不知道怎么看,这个时候要怎么办?
我们会很自然地想到,那就上网查一下怎么看好了,用不了10分钟就能解决。但是在实际排查问题的过程中,绝大多数情况下我并不会花费5分钟去研究怎么看队列长度,更有可能的做法是花1分钟查一下GC情况,花1分钟看看系统日志,再花2分钟去确认有没有看错应用日志。会这样做的原因有2个。
首先是因为在排查问题的过程中,收集到的线索更多是用于排除可能性,而不是用来证明可行性,在得到线索内容之前,我很难说某个线索比另一个线索更有价值,这时会很自然地倾向于那些时间成本更低的工作。
其次,在心理学上有个现象,叫作“熟悉偏好”,指的是人们在熟悉的事情和不熟悉的事情之间更喜欢选择熟悉的,会回避陌生的事情。在排查问题,尤其是线上问题的过程中,这种现象表现得尤其明显。在出现了问题之后,很多同学更倾向于利用已有经验排查问题。
以上2个原因跟技术关系不大,但是造成了虽然知道应该去获取某些信息,但实际上总会拖到实在没招的时候再去想办法查看“我觉得应该知道的信息”,实际浪费的时间远远大于新知识的学习时间。
如何获取这些隐藏的信息,我个人的经验是使用工具,不管是系统还是应用都可以给我们提供很多工具,在QCon的演讲里也提到了一些。无论是系统提供的,还是第三方的,或是自己开发的都可以辅助我们发现更多的线索。
但是就像刚才说的,在问题排查过程中,工具的学习和使用成本都是我们需要考虑的非常重要的因素。下面我来列举几点经常用到的信息和期望达到的效率,供大家参考。
30秒获取整体服务情况:请求量、响应时间分布、错误码分布。这里主要是用业务的监控系统。
3分钟了解某台机器的负载情况:最耗CPU的线程和函数(CPU)、TCP连接状态统计和buffer堆积状态(网络)、程序的内存分布,最耗内存的对象(内存)、当前是哪个程序在占用磁盘I/O、GC情况。这里主要是Linux和Java的一些辅助工具:top/perf/netstat/iftop/jmap/jstat等等。
3分钟了解请求的链路情况:网络传输、系统调用、库函数调用、应用层函数调用的调用链、输入、输出、时长。这里也有Linux和Java的一些辅助工具,TCPdump/strace/ltrace/btrace/housemd等。最近我们也在完善用于集群的调用链分析工具trace,希望在足够完善之后能开源出来。
3分钟检索当前系统的快照情况:线程栈情况、某个变量的值、存储或缓存里的某个值是什么。同样是系统和Java提供的一些已有工具,如jmap/jstack/gdb/pmap等。
可能大家觉着这个指标定得有些低,有不少信息都是可以通过一个命令看到的,这里特别强调一下,我指的是从头脑中有要看的想法,到看到并理解实际信息的时间。Google一下命令的用法、安装工具之类的时间也要算进去。
刚才说到关键点是如何提高效率,熟练工是一个方法,但是降低工具的使用成本更有效一些。我们做了一些排查问题相关的工具和系统,相信很多公司也有类似的内部系统。
总之,关于known-unknown只强调一点:如果要做用于排查问题的工具,若一次查询的时间超过3分钟,那在实际排查的过程中很有可能无法发挥此工具的价值。
3.unkonwn-unknown
我个人有个体会,在高负载系统出现的问题中,有很大一部分问题的产生原因是我原先根本不了解的,比如JVM里的某个Bug,或者某些内核在实现中有一些之前听都没听过的特殊机制。
这里其实有个误区,超出知识体系并不意味着不能分析问题。我们在遇到一些超出以往知识体系的棘手的问题时,很有可能会产生焦虑感,认为这个问题不科学、无法解决,并且做一些没有价值的事情,比如反复检查日志、反复重启,甚至开始论证这个问题不可能发生。
这个时候其实就没有很具体的方法了,不过还是说一些思路跟大家分享一下:对于这类场景可以做减法,尽可能缩小范围,当范围可控之后,再去了解相应的原理。
下面是几个具体的解决方式:
尝试重现问题,修改变量后尝试是否能复现。
对比正常系统和异常系统的不同,找出异同点。
通过已有知识剔除异常中正常的部分,缩小异常范围。
通过看书或者教程了解原理;通过看源码了解实现机制。
例6:前几天分析了一个Tomcat突然请求变慢的问题,日志异常、性能没有瓶颈、线程数正常,通过工具也没找到什么新线索,就是不知道慢在哪了。
当时我的做法是先尝试复现问题,不管是测试环境压测、TCPcopy还是保留现场等都可以用于复现现场。
问题复现之后尝试缩小范围:一次HTTP请求的过程包括TCP三次握手、应用Accept连接、接收request、应用层处理、发送response、关闭连接这个过程,于是我用TCPdump和strace直接跟踪了网络包状况和系统调用,梳理了某一次调用的时间轴,发现时间浪费在三次握手和Accept之间。
之后通过Accept关键字在Tomcat源代码中查找,分析了Accept相关的代码,找到了Tomcat的一个Bug:在bio方式下如果应用有stackoverflow,那么线程会退出,但是连接计数没有减掉,这会导致新请求不能被Accept。
特别说一下,这个Bug存在于Tomcat 7.0.42之前的版本,后面的版本修复了这个问题。
总结
以上是我关于known-known、known-unknown、unkonwn-unknown的一些理解。在排查的时候大家可能会交替地遇到这几种场景,不过只要掌握诀窍,逐个击破就好。
下面给大家一些系统设计方面的建议,其实在上面的内容中已经体现过了,我在这里只是总结一下。
首先,问题排查是复杂的、不可控的,所以不要把排查和解决混在一起,尽量先解决、再排查。解决的方式基本上都是那么几板斧:重启、回滚、扩容、降级、迁移,具体方案这里就不展开了。
其次,系统要尽可能地对外暴露内部状态和干预手段,比如说少打了一句日志,没把变量输出出来,那么出现问题的时候就不得不使用某些复杂的工具去查询这个变量,而且很有可能还要多绕一个大圈。
再次,系统是不稳定的,所以对于高可用架构设计来说,隔离是必须的,不管是何种依赖方式,都需要考虑“实在不行了”的情况。
最后,问题的原因、传播路径和现象不是一一对应的。对同一个问题来说,这次的表现是多打了一行WARN日志,下次可能就是一次系统雪崩。墨菲定律说如果有可能出问题,就一定会出问题。
如果有读者没看过我之前在Qcon上的演讲地址,可以跟本节的内容对比着看一下:http://www.infoq.com/cn/presentations/typical-problems-of-weibo-in-large-scale-high-load-system。
疑问与解惑
Q:在线JVM的信息排查,是在开源工具上进行的封装,还是自己写的工具?
主要都是开源的,一小部分是自己写的。
Q:日常分析问题的工具如何能做到持续好用?
一是把框架和逻辑分离,增加逻辑时不用改代码,写一个脚本就可以简单地完成。二是尽可能优化工具的效率,这个是问题排查工具的核心价值。
Q:当系统出错了,在你们排除问题的同时,怎么保证不影响线上呢?
首先要解决问题,通过运维的一些介入手段把服务恢复,同时尽量保留现场(比如保留一台出问题的机器只摘除不重启)。其次是通过监控或者日志初步定位原因之后在线下复现问题,这时再排查就没有什么心理负担了。
Q:不同语言(如PHP/Java)的应用,还有不同的层面(如网络/操作系统/数据库)问题的排查,都有什么模式和异同?
我理解思路上都是类似的:找线索,推测原因,再找线索证明。区别主要是问题的原因具体用到的工具可能不一样,现象基本上都是那么几种:慢了、死了、处理出错了。
Q:业务系统的日志,是通过外挂工具收集,还是要侵入到业务里面写日志?如果侵入到业务里面,有没有一些日志方案可以推荐?
有一部分是外挂工具,还有一部分是业务里面,不过业务里面指的也是业务的框架层去集中输出这些日志,具体写业务的人不用管。日志方案我们主要用Scribe,也有一部分用Logstash,运行得都挺好。
Q:线上出现请求block或请求慢时,一般会保留哪些现场数据?如果线下难以重现,线上问题的时间窗口也滑过去了,是不是可能会变成无解问题?
一般来说,不重启是最重要的。其次,Java会把jstack/jmap/jstat之类都来一遍,其他类型的Linux程序主要会留gcore和各种指标类的数据,top/perf/strace。
Q:想请教一下,做监控的话,对一些metric的阈值,你们是怎么设置的?是靠人工观察得经验得出,还是使用了一些自动化(比如机器学习)的方案?
一般根据请求量和监控系统的处理能力来决定,通常来说,简单的指标分析都是靠经验定的阈值,但针对一些复杂的、经常变化且与业务相关的阈值,我们会根据历史数据自动设置。
Q:Java在请求无法响应时,这时候jdump命令需要很长的时间,线上无法服务,有没有更好、更快速的方法可以保留现场?
我们在dump时,这台节点已经从线上摘掉了,所以慢不是问题。如果不能摘,可以考虑用btrace、housemd这类工具直接挂到进程上分析,不过btrace有可能导致应用假死,几率是几十分之一,慎用。
Q:业务出问题后是多个部门一起查找问题吗?有些问题既要懂业务又要懂技术细节,在微博上有多少人能达到您的排查问题水平,每次出问题都需要您出马吗?有没有自动诊断问题的工具?
我也很想要问题自动诊断,最近也想继续改进工具。不过更多的可能还是有工具自动把一些现象把帮我汇总出来,我感觉在分析方面还是做不到自动化。
本文节选自《高可用架构(第1卷)》一书

内容提要
《高可用架构(第1卷)》由数十位一线架构师的实践与经验凝结而成,选材兼顾技术性、前瞻性与专业深度。各技术焦点,均由极具代表性的领域专家或实践先行者撰文深度剖析,共同组成“高可用”的全局视野与领先高度,内容包括精华案例、分布式原理、电商架构等热门专题,及云计算、容器、运维、大数据、安全等重点方向。不仅架构师可以从中受益,其他IT、互联网技术从业者同样可以得到提升。
购买链接点击「阅读原文」
留言点赞抢书活动参与方式
在文末留言
“对高可用架构一书的想法或想读此书的理由”
截止至2017年 12 月 2 号前
留言被点赞最多的前5名用户
可以获得《高可用架构》一书