神奇GANs在哪里(二)
论智

作者 | Guim Perarnau
编译 | Bing
编者按:昨天我们介绍了生成对抗网络的基本知识,以及最初的发展历程。今天,论智君将继续为大家带来“神奇GANs在哪里”的第二部分。本文将继续上篇,为你讲述GANs的发展。
上篇回顾
首先,让我们先快速回顾一下上一篇讲了哪些要点。
什么是GANs:生成对抗网络是两个神经网络相互对抗和学习的过程,一般用于生成逼真的图像,也可以用于无监督学习(例如从没有标签的数据中学习)。
上篇的相关模型:
生成对抗网络:最原始的GANs模型。
深度卷积生成对抗网络(DCGANs):这是GAN体系结构的首次重大改进,在训练稳定性和样本质量方面都有了提升。
Improved DCGANs:改善了DCGANs的基准线,能够生成更高分辨率的图像。
Conditional GANs(cGANs):使用标签信息来提高图像质量并可以控制这些图像的外观。
InfoGANs:这种模型能够以完全无监督的方式将有意义的图像特征进行编码。例如,在MNIST的数据集上,InfoGANs可以编码数字的旋转角度。
Wasserstein GAN(WGAN):该方法重新设计了与图像质量相关的原始损失函数。这提高了训练的稳定性,使WGANs更少地以来网络架构。
GANs的演化(Part II)
Improved WGANs(WGAN-GP)
在本文中,研究人员发现weight clipping是导致训练不稳定,以及难以捕捉复杂概率分布的元凶,所以文章提出通过梯度惩罚来对判别器实施Lipschitz限制。实验结果表明这种方法能使训练更加稳定,收敛更快,同时能够生成更高质量的样本。
论文地址:https://arxiv.org/abs/1704.00028
代码地址:https://github.com/igul222/improved_wgan_training
问题。为了满足Lipschitz约束,WGAN中会执行weight clipping,使得WGAN有时会产生低质量的样本,或者在某些情况下不能收敛。那么为什么weight clipping是个问题呢?因为它限制了WGAN使用更简单的函数。这意味着WGAN可能无法用类似简单的方法来模拟复杂的数据(见下图)。此外,weight clipping可能会导致梯度消失或爆炸。
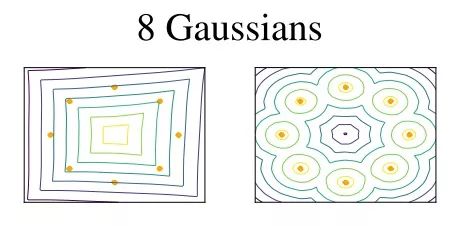
梯度惩罚。那么我们该如何摆脱weight clipping呢?WGAN-GP(GP表示梯度惩罚)的作者建议使用梯度惩罚来执行Lipschitz约束。梯度惩罚把判别器的梯度norm限制在1附近,所以梯度的可控性非常强,容易调整到合适的尺度大小。
优点。因此,用梯度惩罚代替weight clipping能让WGAN具有更快的收敛性。此外,在不再需要调参的情况下,使用的体系结构就不重要了,训练更加稳定。WGAN-GP同样能生成高质量的样本,但很难分辨提高了多少质量。在经过测试的结构上,这些样本的质量与WGAN的基准线非常相似:

WGAN-GP明显优于其他GAN的架构。例如,就我所知,这是GAN首次在剩余网络架构上工作:

除此之外,WGAN-GP还有很多有趣的细节,在这里就不展开讲了。若想了解更多,可以查看这篇文章(https://arxiv.org/abs/1704.00028)。
适合使用WGANs-GP的情况:
你想让WGAN的收敛速度更快、支持更多架构和数据集、无需调整参数时。
Boundary Equilibrium GANs(BEGANs)
这是一个用自动编码器作为判别网络的GAN。他们可以在简单的结构上成功训练。BEGAN包含一个动态参数,能平衡生成网络和判别网络。这里插播一个有趣的事实:BEGANs与WGAN-GP的论文同一天发表。
论文地址:https://arxiv.org/abs/1703.10717
理念。BEGAN与其他GANs不同的原因是,BEGAN使用自动编码器体系结构作为判别器(与EBGAN类似),并为此建立了一个特殊的函数。
为什么要重建损失?作者的解释是,我们可以依靠与重构损失分布匹配的假设,最终匹配样本分布。重要的一点是,自动编码器或鉴别器的重建损失并不是BEGAN最小化的最终损失(即输入图像,生成质量最好的重建图像)。重建损失只是计算最终损失的一个步骤。最后的损失是使用Wasserstein距离在真实数据和生成数据的重建损失之间计算的。
信息量可能有点大,但我相信,一旦我们看到这个损失函数应用于生成网络和判别网络,结果会更清晰:
生成网络致力于生成能让判别网络重建的图像。
判别网络试图尽可能重建真实图像,同时以最大误差重建生成的图像。
多样性因素。多样性因素是另一个有趣的地方。这个因素控制着你想让判别网络更多专注于完美重建高质量的真实图像,还是区分生成图像与真实图像的区别。然后,他们更进一步,利用这种多样性因素平衡训练期间的生成网络和判别网络。与WGAN类似,它们使用两个网络之间的平衡作为影响收敛速度的因素,从而影响图片质量。然而,与WGANs和WGANs-GP不同,它们使用Wasserstein距离的方式不需要Lipschitz约束。
结果。BEGAN不需要特殊的架构来训练,正如文章中提到的:“没有批规范化,没有丢失,没有转置卷积,也没有卷积滤波器和指数增长。”生成的样本质量让人印象深刻:

想了解更多信息,可以阅读这篇博客(https://blog.heuritech.com/2017/04/11/began-state-of-the-art-generation-of-faces-with-generative-adversarial-networks/)。
适合使用BEGAN的情况:
和WGANs-GP相同,它们的特点非常相似:稳定的训练过程,简单的架构,与图像质量相关的损失函数。只是方法有所不同。由于评估生成模型的困难,很难决定哪一个更好,二者都非常具有创新性。
Progressive growing of GANs(ProGANs)
作者在训练期间逐渐添加新的高分辨率图层,生成极度逼真的图像。同时还提出了其他改进和新的评估方法,生成的图像质量非常惊人。
论文地址:https://arxiv.org/abs/1710.10196
代码地址:https://github.com/tkarras/progressive_growing_of_gans
生成高分辨率的图像是一个巨大的挑战。图像越大,网络越容易失败,因为它需要学习生成更细微和更复杂的细节。在这以前,生成的图像大约是256x256,ProGANs生成的图像达1024x1024的全新水准。
理念。ProGANs建立在WGANs-GP之上,通过在训练期间逐渐增加新的图层,让生成网络和判别网络的每层图像都达到更高的分辨率。具体步骤如下所示:
1.一开始用低分辨率的图像训练生成网络和判别网络;
2. 在某一时刻(例如当它们开始收敛时)增加分辨率。为了平滑地构建深度增长网络,整个过程中使用类似残差网络拼接特征图的方式。
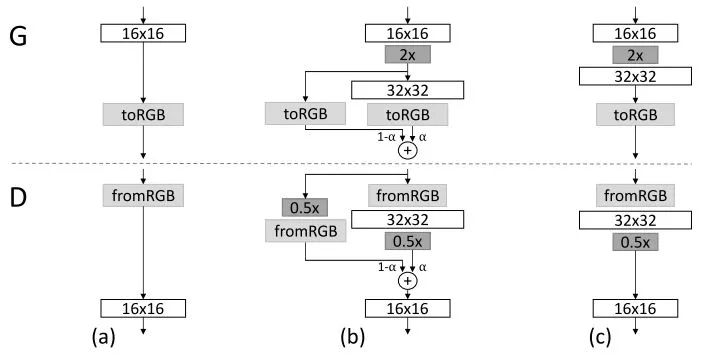
它不是直接添加新图层,而是添加在由α控制的线性步骤上。
一开始,当α=0时,没有任何变化。所有的输出值来自之前的低分辨率(16x16)图层。然后,随着α的增加,新层(32x32)将开始通过反向传播调整其权重。最后,α将等于1,我们可以完全跳过32x32层。判别网络也是如此,不过却是让图片缩小。
3.一旦转换完成,继续训练生成网络和判别网络。如果当前生成图像分辨率不足,则再进行第2步。
也许有人会想,这种生成高分辨率的上采样和串联在StackGANs和新的StackGANs++中不就已经实现了吗?是也不是。首先,StackGAN是文本到图像的Conditional GANs,它们使用文本描述作为附加输入。而ProGANs不使用任何类型的条件信息。不过有趣的是,虽然Stack GANs和ProGANs都使用了更高分辨率的图像,但StackGAN需要对每个上采样进行独立训练。而在ProGANs中只需要训练一个GAN就可以了。在这次培训期间,更多的上采样层被逐步添加到图像中。所以,ProGANs与StackGANs的理念相似,但更加优雅,无需额外的条件信息。
结果。作为这种渐进式训练的结果,ProGANs生成的图像质量更高,在1024x1024图像上训练的时间减少了5.4倍,因为ProGAN无需同时学习大规模以及小规模表征。在ProGAN中,首先学习小规模,即低分辨率层的收敛,然后模型可以专注于大规模化结构,即新的高分辨率层的收敛。
适合使用ProGANs的情况:
你想用最先进的模型,同时又有大量时间训练……“我们在单个NVIDIA Tesla P100 GPU上训练了20天……”
如果你想看到比真实图片更逼真的样本……
Honorable mention:Cycle GANs
截至目前,Cycle GANs是最先进的图像转换技术。
文章地址:https://arxiv.org/pdf/1703.10593.pdf
代码地址:https://github.com/junyanz/CycleGAN
这些GANs不需要为了在两个域之间学习配对数据集,这是很好的,因为这种数据很难获得。然而,Cycle GANs仍然需要用来自两个不同域X和Y的数据来训练。为了控制从一个域到另一个域的翻译,他们使用所谓的“cycle consistent loss”。这意味着如果你将一匹马A转换成另一匹斑马A,那么当你从斑马变回马时,还是原来的A的样子。

从一个域到另一个域的映射不同于流行的神经风格转移。后者将一个图像的内容与另一个图像内容相结合,而Cycle GANs学习从一个域到另一个域的高级映射。因此,Cycle GANs更加通用,也可以用于各种映射,如将草图转换为真实的物体。
结语
回顾本文,GANs的发展主要有两点:WGANs-GP和BEGANs。虽然研究方向不同,但它们都有相似的优点。接着,基于WGANs-GP的ProGANs能够生成逼真的高分辨率图像。同时CycleGAN能够让我们了解GANs从数据库中提取有价值的信息的能力,以及如何将这些信息转移到另一个不相关的数据分布中。
原文地址:http://guimperarnau.com/blog/2017/11/Fantastic-GANs-and-where-to-find-them-II
本文系论智编译,转载请联系本公众号获得授权。


