seqgan
莫驚蟄 from : https://www.zhihu.com/question/52602529/answer/155743699
直接把GAN应用到生成序列,有两方面的问题:
1. GAN最开始是设计用于生成连续数据,但是自然语言处理中我们要用来生成离散tokens的序列。因为生成器(Generator,简称G)需要利用从判别器(Discriminator,简称D)得到的梯度进行训练,而G和D都需要完全可微,碰到有离散变量的时候就会有问题,只用BP不能为G提供训练的梯度。在GAN中我们通过对G的参数进行微小的改变,令其生成的数据更加“逼真”。若生成的数据是基于离散的tokens,D给出的信息很多时候都没有意义,因为和图像不同。图像是连续的,微小的改变可以在像素点上面反应出来,但是你对tokens做微小的改变,在对应的dictionary space里面可能根本就没有相应的tokens.
2.GAN只可以对已经生成的完整序列进行打分,而对一部分生成的序列,如何判断它现在生成的一部分的质量和之后生成整个序列的质量也是一个问题。
近几篇重要的工作:
1. 为了解决这两个问题,比较早的工作是上交的这篇发表在AAAI 2017的文章:SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient, 16年9月就放上了Arxiv上面了,而且也公布了源代码。
利用了强化学习的东西来解决以上问题。如图,针对第一个问题,首先是将D的输出作为Reward,然后用Policy Gradient Method来训练G。针对第二个问题,通过蒙特卡罗搜索,针对部分生成的序列,用一个Roll-Out Policy(也是一个LSTM)来Sampling完整的序列,再交给D打分,最后对得到的Reward求平均值。
https://github.com/suragnair/seqGAN
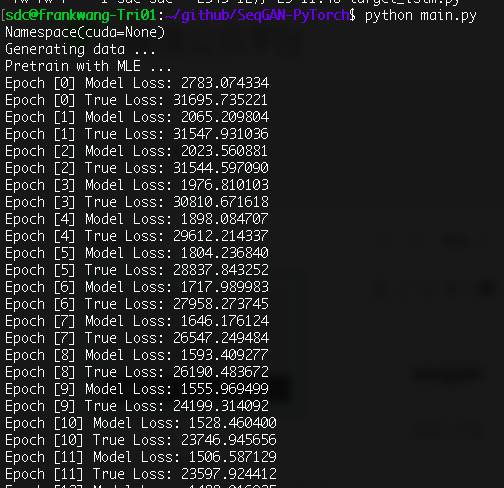
https://github.com/ZiJianZhao/SeqGAN-PyTorch
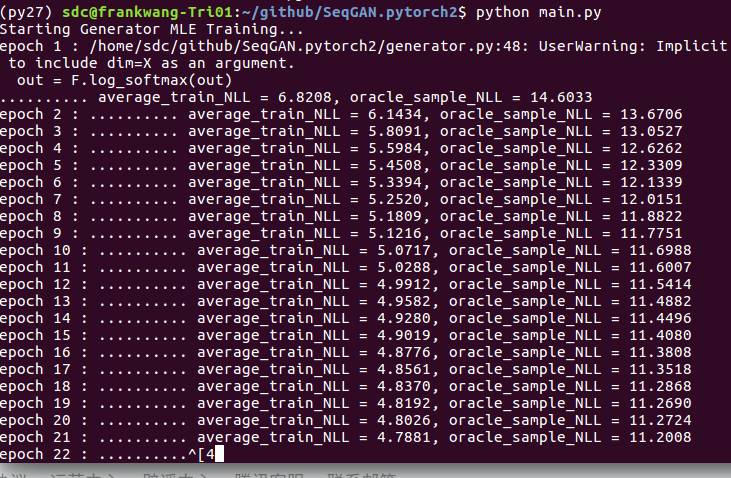
掌握了seqgan就来面试吧





