Apache Kylin最新的Streaming OLAP实现

本文来自作者在GitChat(ID:GitChat_Club)上的精彩分享,CSDN独家合作发布。
Apache Kylin是第一个来自中国的Apache顶级开源项目,连续两年获得了InfoWorld最佳开源大数据工具奖,2016年更是与Google TensorFlow一起获得该奖。 Apache Kylin的社区也非常活跃,目前Kylin被用于eBay、Expedia、网易、美团、百度、唯品会、京东、搜狐、OPPO等知名公司,在全球范围有200多家公司正式使用,而且都应用得非常大。
Kylin解决的是什么?
Kylin所带来的,是大数据场景下快速分析的能力。举一个例子,今日头条看新闻的时候,前面会有一些推送,需要用到一些转换,把数据拿下来之后做分析。单个应用的数据量有多大?3万亿条。Kylin里面3万亿条的数据,任何搜索查询的速度只需要1秒。这就是我们的能力。
现状:Hadoop的生产力未得到充分释放。
绝大多数平台公司的平台结构,在以前没有Hadoop的时候都会把数据放到数据仓库中,用数据库进行分析。十年前最大的数据仓库是沃尔玛,大概是3个P,eBay的数据仓库是10P左右,但Hadoop超过200P。当时没有在大数据平台上提供数据仓库的能力。因此在2013年我们评估了七八种商业的和开源的技术方案之后,最后决定自己做。 我们希望把数据仓库的能力在Hadoop之上构建起来,这也就诞生了Kylin。我们在Hadoop之上提供Kylin的数据仓库,最开始做的是一个预先计算的立方体(cube)技术,通过这样的技术扩展到目前支持全部的数据集市、未来可以支持更多的数据仓库的能力。 具体能够提供哪些东西呢?
超高性能:不管数据有多大,十亿、百亿、万亿保证性能在秒级返回,满足传统数据分析应用的时效性要求。最近正在给保险公司做压力测试。
高并发:往往大数据的系统,甚至是数据仓库的系统,即使性能优化得再好,并发也是一个痛,这是由分布式系统决定的缺陷。你有一千台机器,一条SQL下去的时候很快,但是一千人、一万人,乃至十万人同时上线压上去的时候,你的数据不可能永远均匀地存储,200左右的并发一定会打爆。对于此类高并发的问题,我们通过构建一层数据集市层来解决。
标准SQL:用过Hadoop Hive的知道,Hive这个东西挺好,但是你不能给业务人员去用,他们喜欢的是标准的SQL,这也是Kylin非常重要的一个特性。
Apache Kylin的架构
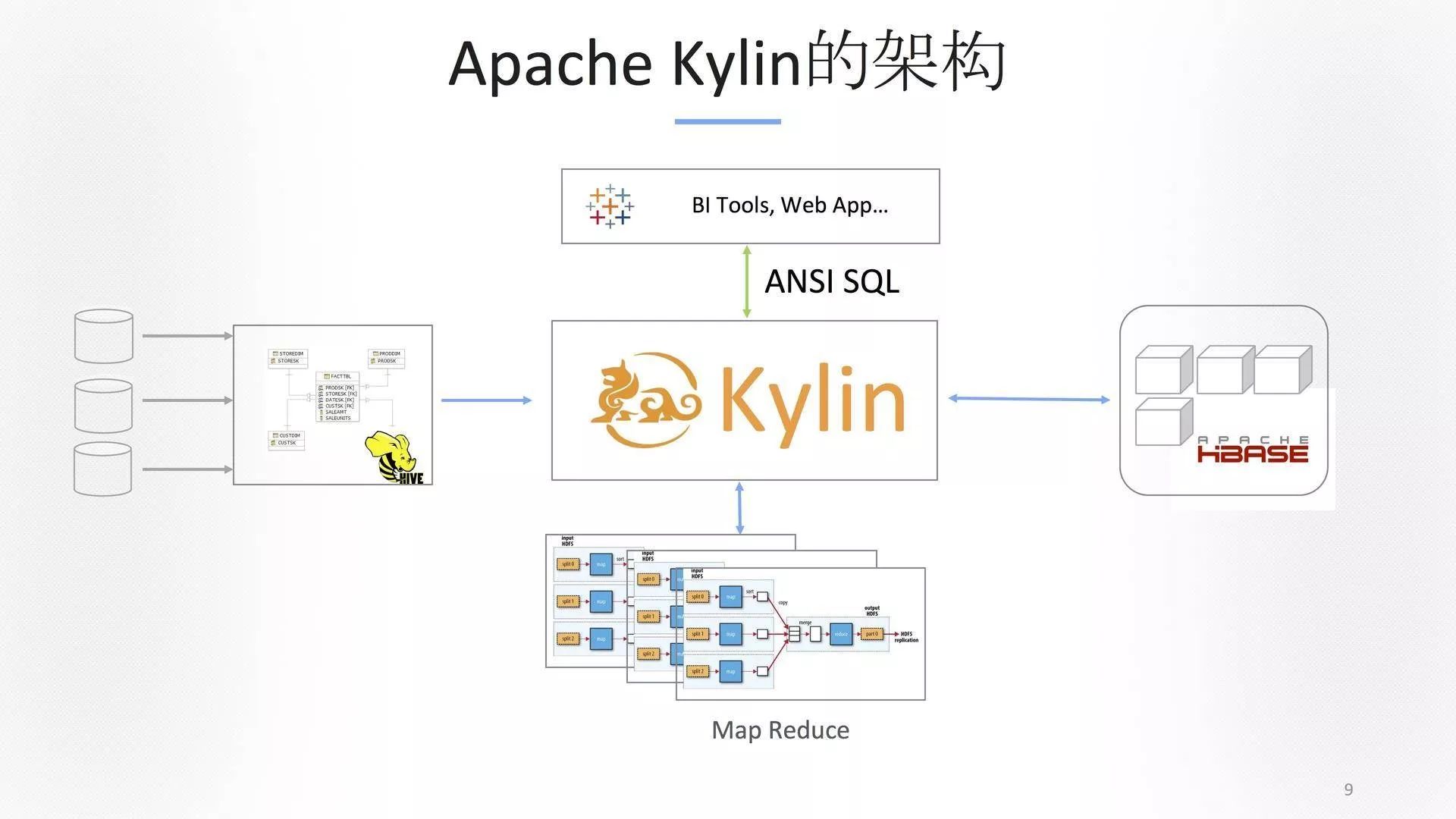
我们会要求把数据放在Hadoop上,用Hive呈现出来。在Kylin里面定义整个元数据,在一个企业里面不是工程师去做,而应该是BI人员或者分析师去做。工程师喜欢底层技术,但是BI及分析人员并不关心底层实现。所以,我们提供了一个非常好的界面,你可以在上面构建,当你把所有的工作做完之后,Kylin会生成MapReduce 或者Spark任务,你不需要写一行代码。Kylin会跟集群交互做计算,过程中你也不需要登录去看,我们都通过界面去给到你,这带来的好处是效率。大数据人才找不到,原因不是被BAT抢了就是被华为抢了。我们提供的工具是降低使用门槛,让分析师自己去做大数据分析,让上层分析师、业务用户通过自己喜欢的BI工具或者自己写个程序,进行访问。在访问的过程中,它不会去运行任何Hive,也不会运行Map Reduce。
V1.5核心组件解耦:
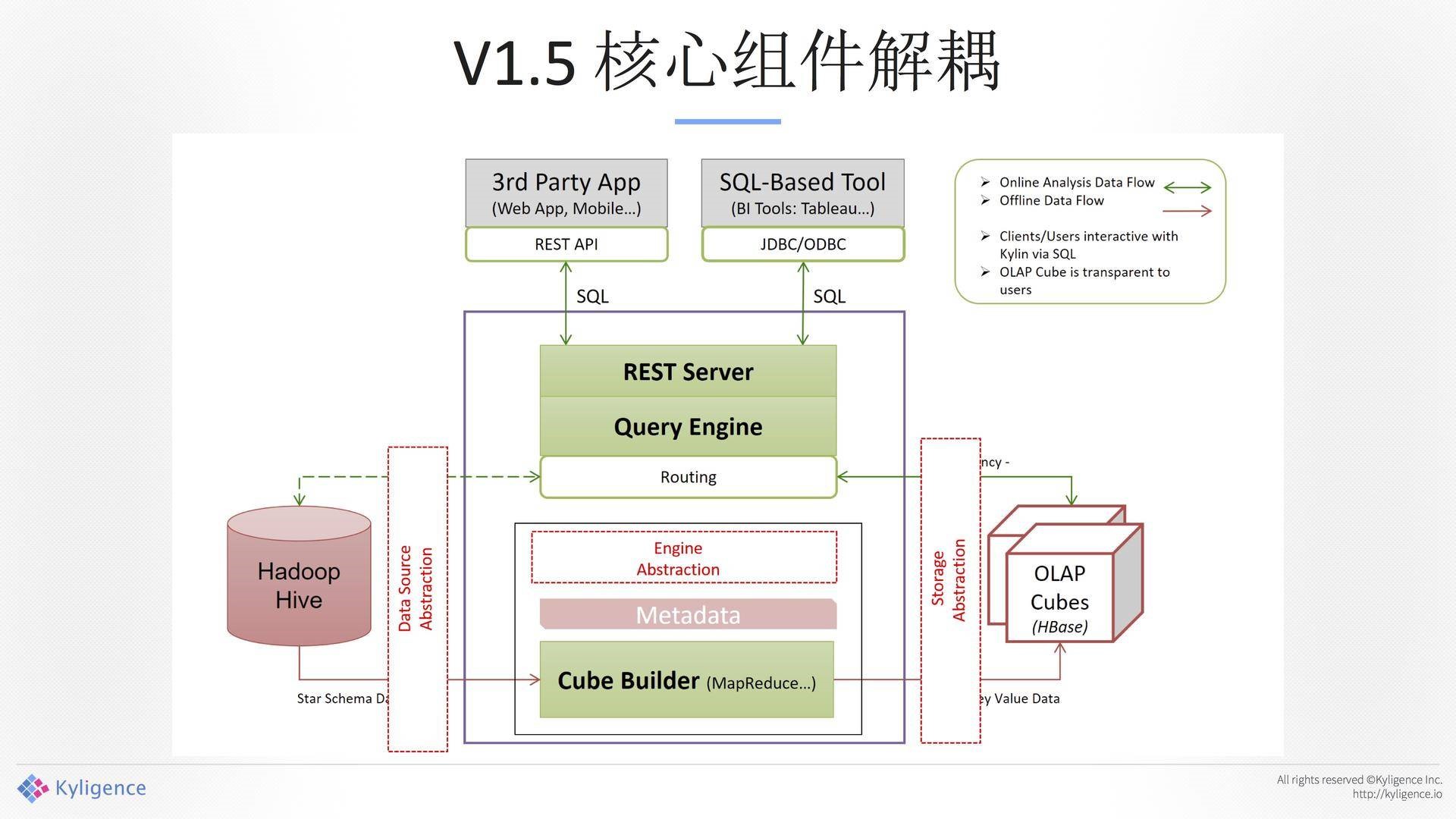
我们是预计算的一个系统,带来的好处是数据可以跑批,我们解决的是第一个问题。第二个问题,批量的计算量太大了,越来越多的需求是要做实时、做近实时、做流式。在数据生产的点出来的时候,把那个时间点缩到最短,这是我们当时工作的目的。 我们第一件事情是把输入、输出和计算引擎全部解耦掉,我们花很大的力气做了一个架构的重构,在新的组件中叫可插拔的架构。今天Kylin无论是输入、输出都可以被插拔,可以换,非常方便。
eBay网站SEO的流量,整个搜索引擎过来的流量,被eBay的tracking 系统抓下来,以前是一两天分析师才能看到报表,我们把它降到5分钟左右,这是我离开eBay之前做得最大的项目。怎么做的呢?Kafka两个集群过来,我们自己写了一整套的程序去跑。当然,这里带来的问题是要写很多的手工配置,如下图是1.5版本。
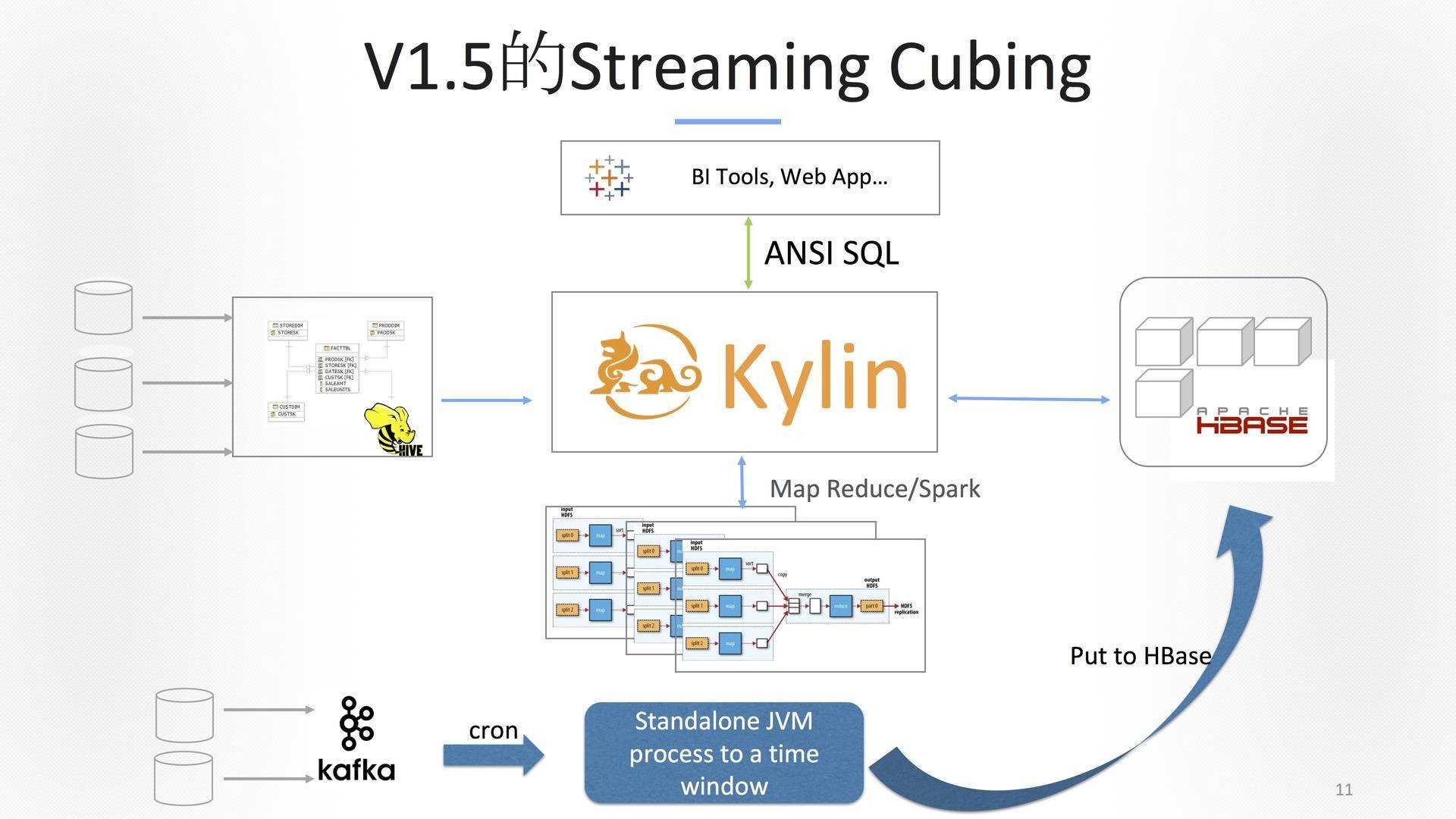
在2016年11月的时候改了很多东西。最开始是怎么处理的?可以看到,数据流进来的时候,这是一段一段的,我们会切一段,把一段数据拿过来做聚合。给我一个时间窗,把数据拿出来做一个聚合,扔给Cube。如下图所示。
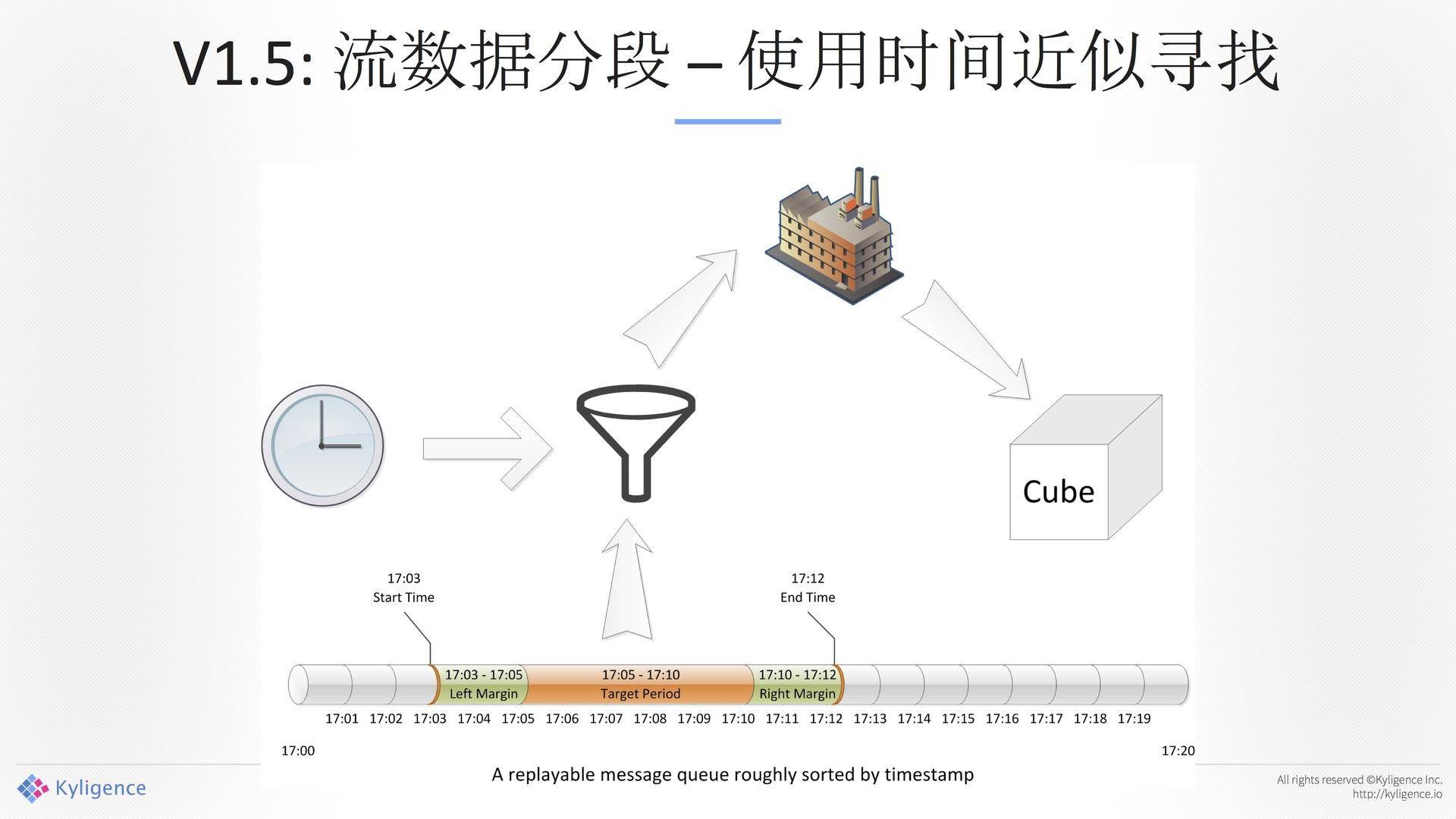
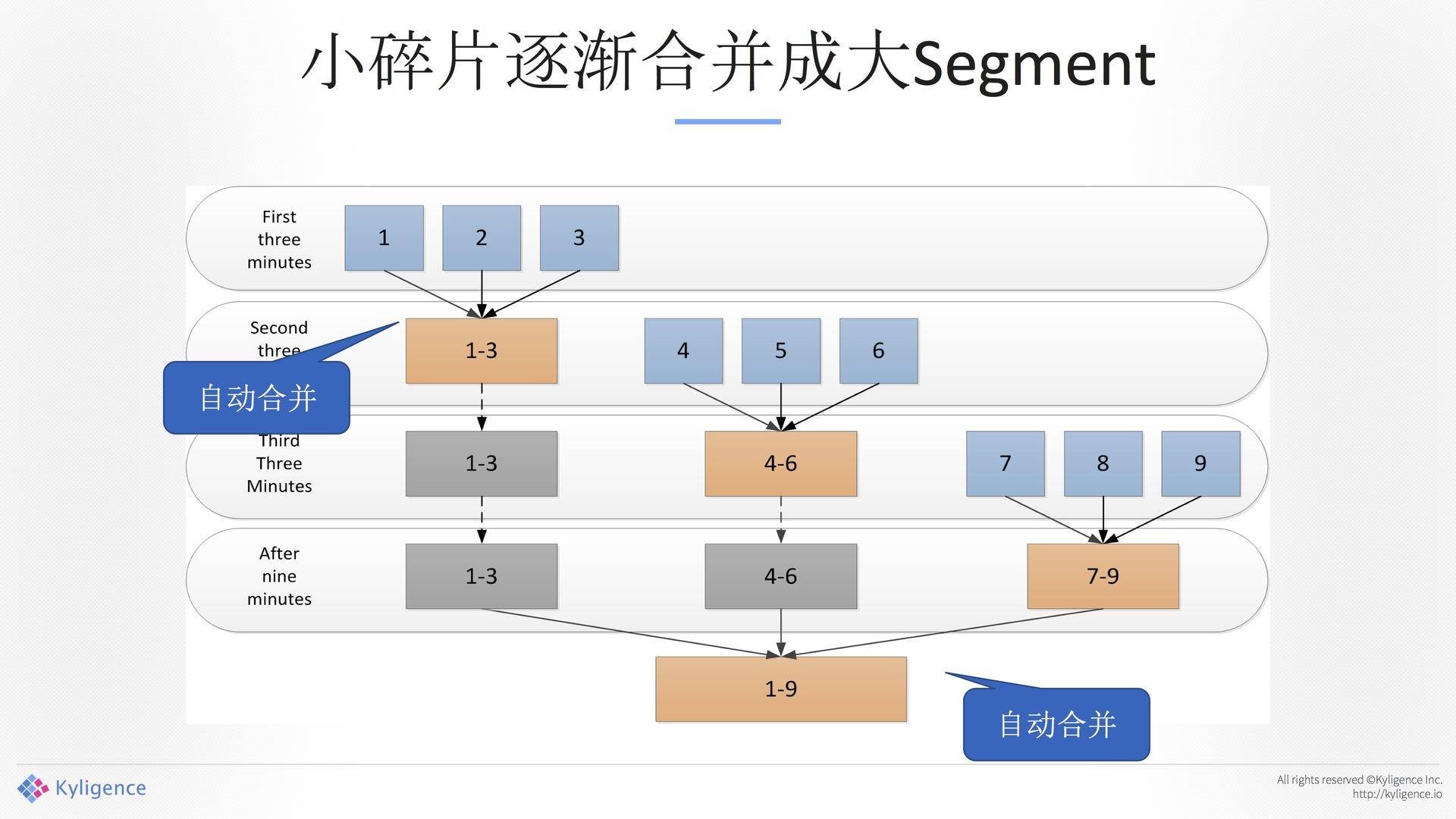
带来另外一个问题,因为这是可以被配置的,从毫秒级原始的流,我们去聚合的时候,5分钟、10分钟、1小时,如果里面小的太多的话,到最后碎片是很大的,一天下来24小时,那得多大的碎片?如果放三天就了不得。我们做自动合并,前面3分钟,前面的数据过来了不管你,我们会自动地三分钟合并一下,再到下面的三分钟合并四分分钟,合并一小时等等。通过这种方式减少碎片,这种情况下碎片不会超过上限。如下图所示。
收获和缺陷:
收获很明显,我们解决了从无到有的问题。但在当时,也存在着一些缺陷。
构建不能自动伸缩。当时我们是两个数据中心,两个集群,eBay的流量非常厉害,再加一个东西的时候,很多需要改配置或者重启,这个很难办。
近似二分查找会丢失数据,基本上是二分查找,硬切的。
构建任务难以监控。这种维护成本是非常高的。
错误恢复困难。
整体运维成本高。
插拔架构下的完美实现:
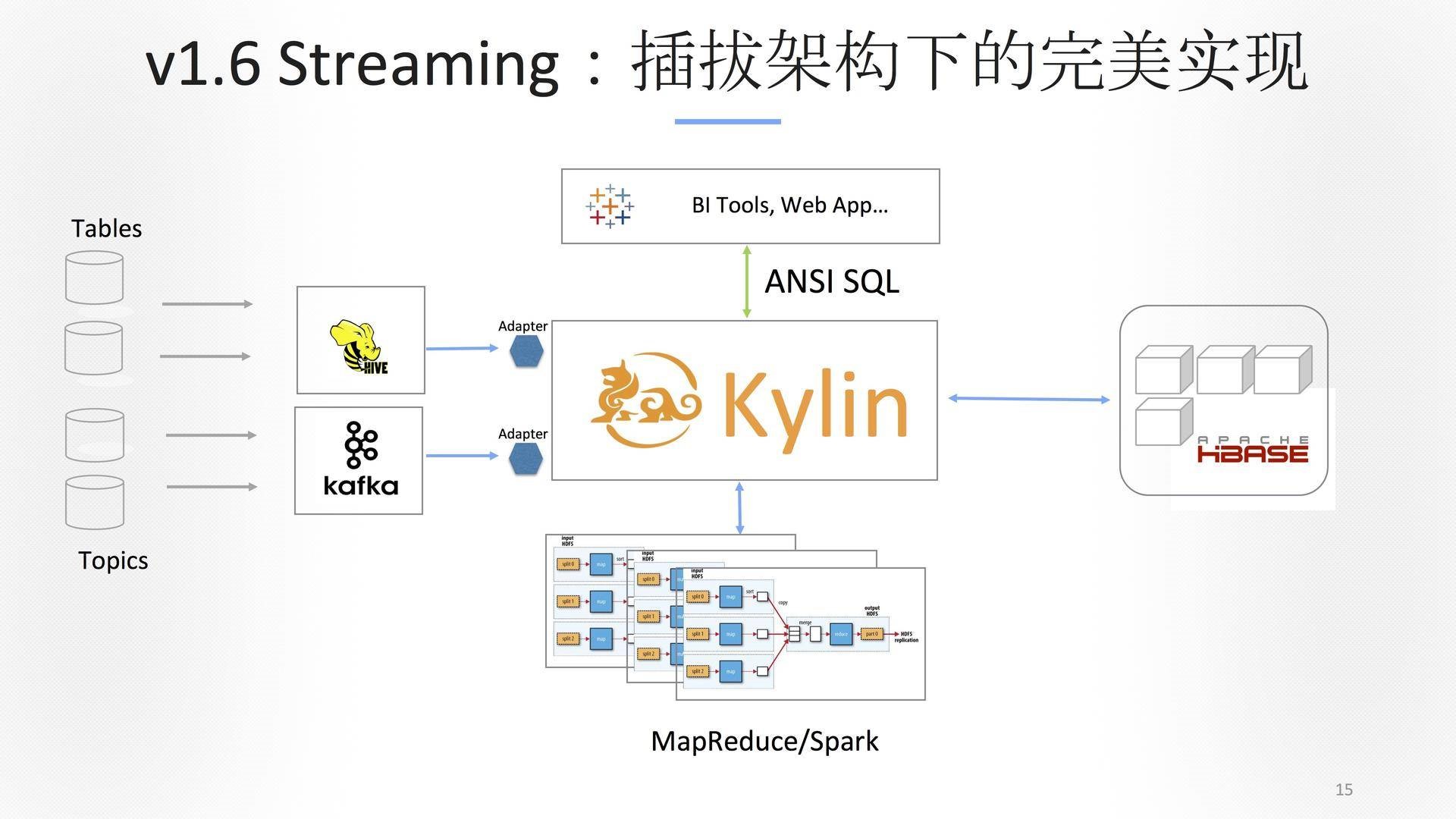
基于之前已经把它变成了可插拔架构了,我们再次更改了一下,加了一些应用,希望利用成熟的Kylin的后台体系。换一个角度看,如果把Kafka变成像Hive一样一个table的话,这件事情就解掉了。这里带来一个非常有意思的假设,在OLAP里面实时性的延迟其实要求没有那么高,这是非常重要的。
如果你想把Kylin这个实时的东西拿去做实时监控和监控告警并不一定合适,因为那个是毫秒级别的,它是机器处理的。Kylin是给人用的,人去看一个报表或者查一个东西的时候,对于延迟的容忍性比较高。Kafka,其实可以等一等,带来几个好处:
数据处理的时候,OLAP不会太大,Hold个几分钟,把数据一大批地往后扔,对于CPU、内存影响非常小。
这样的方式,整个架构变得非常简单,维护容易。
Cube Segment 按offset切分:

对于Hive数据源,分区时间做segment的offset,保证了向前的兼容。对于Kafka数据源,各个Partition的offset之合,作为segment的offset。牺牲了存储,带来上层应用的一致性。
带来的好处:完全可伸缩
大部分代码重用既有构建引擎,易于维护。
几千条到几亿条数据,一次均可轻松构建。
可随时暂停/恢复,可任意更改构建频率。中国会有双11,业务流进来的数据是不一致的,它有高峰,也有低谷,通过这种方式就可以有很好的方式去更改。
其他的改进:
自动寻找开始和结束的offset
支持嵌套式JSON消息
支持自定义时间格式
允许多segment并行构建/合并
通过Rest API触发
Kylin Streaming 先决条件
Kafka版本不能太低,0.10或以上。
Kafka消息为JSON格式,必须有一个timestamp字段。
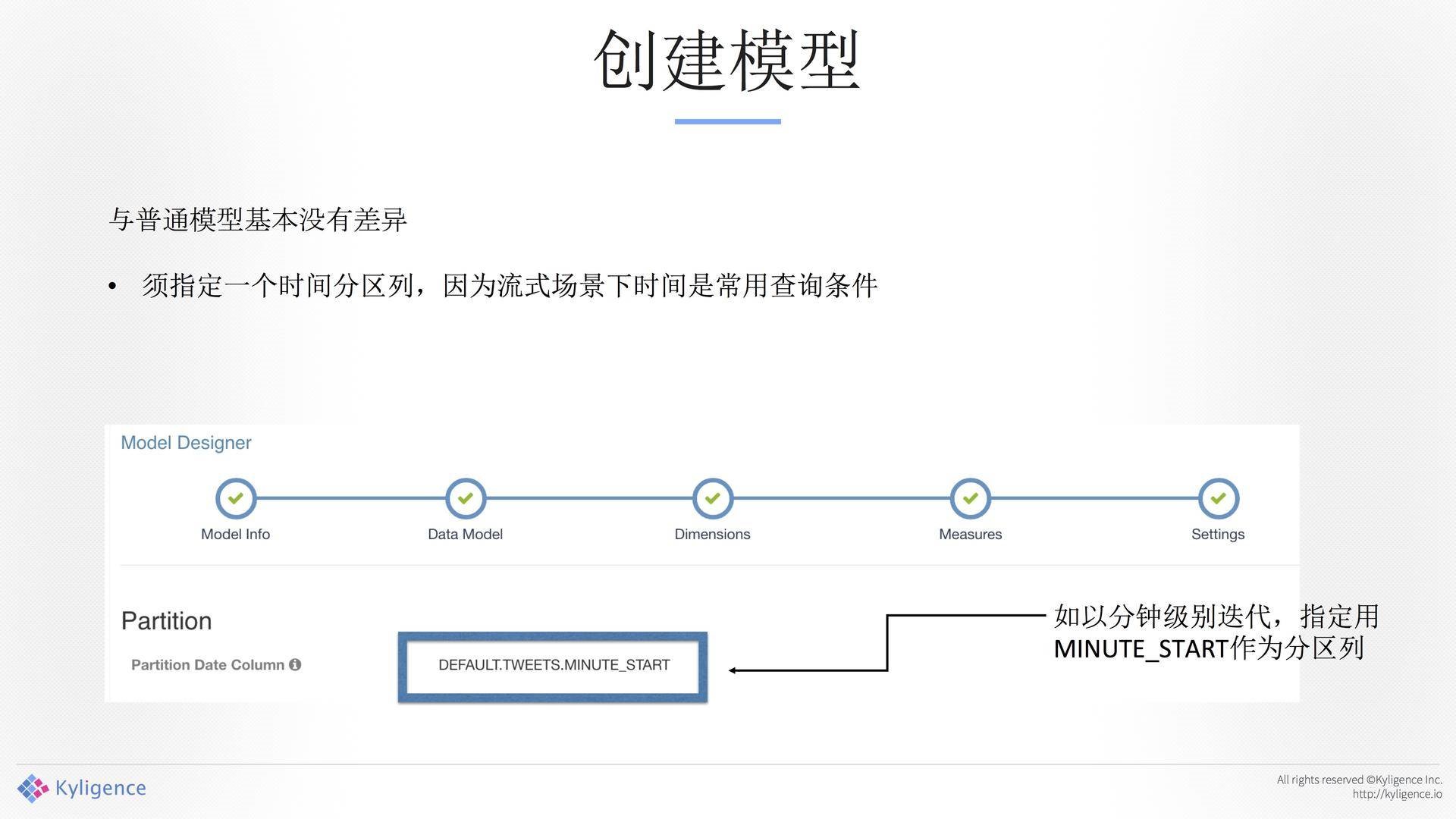
模型仅支持一张表。
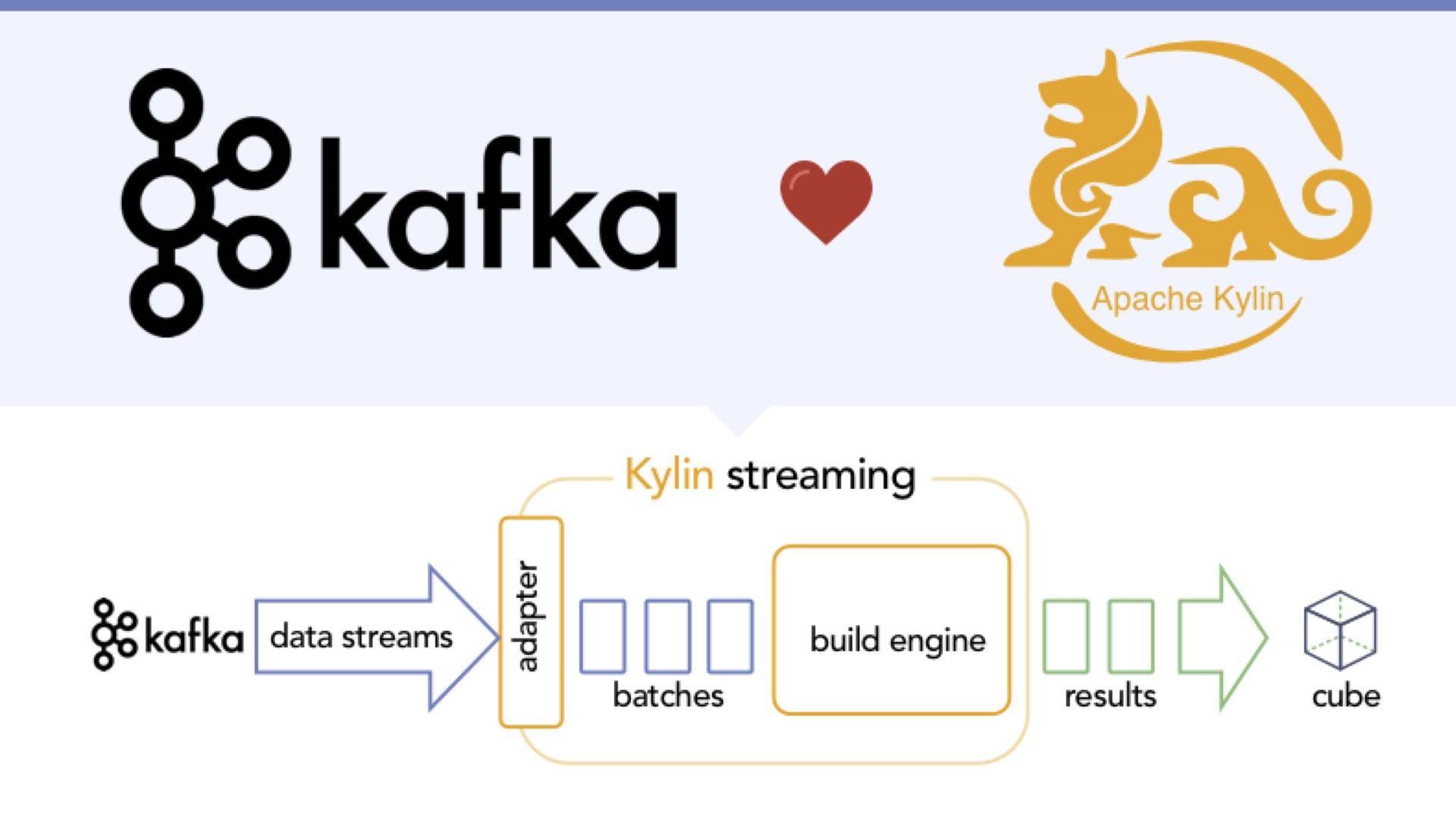
Kafka Streming进来之后,通过插拔把数据收回来,Kafka做了一个缓冲,如图9所示。好处是所有的东西和现有的架构是一模一样的。在eBay做的Kafka设计的是7天的数据,后来跑了大概30天的数据,基本上也没有问题。
使用Kylin分析Twitter消息
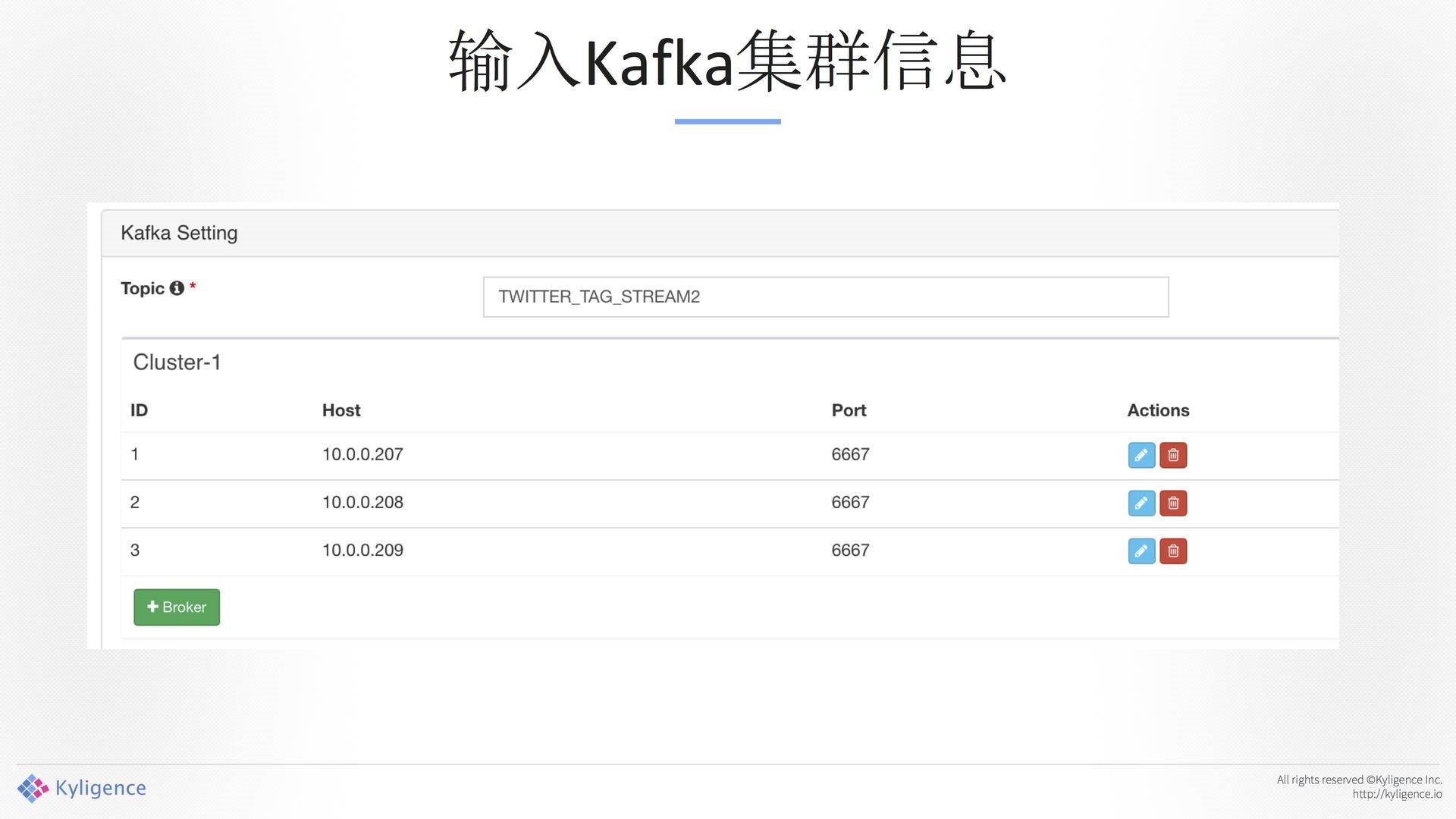
Demo环境:AWS 5台VM的Hadoop集群,Kafka 3个Broker。
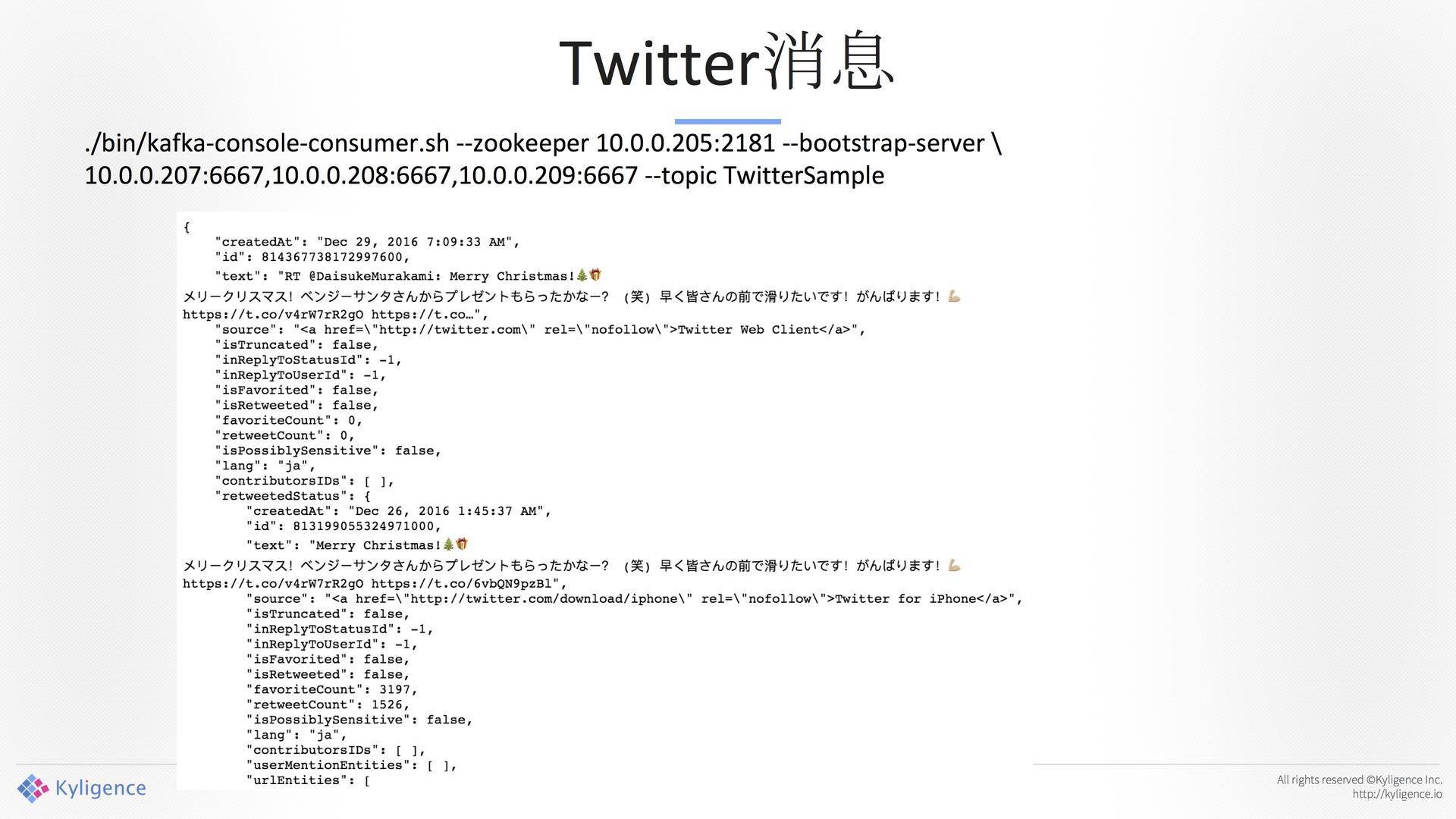
Twitter消息,这是原始数据,如下图所示。原始数据没有办法直接去分析,因为把它给分析师的时候,分析师会跳起来的,分析师只懂SQL。
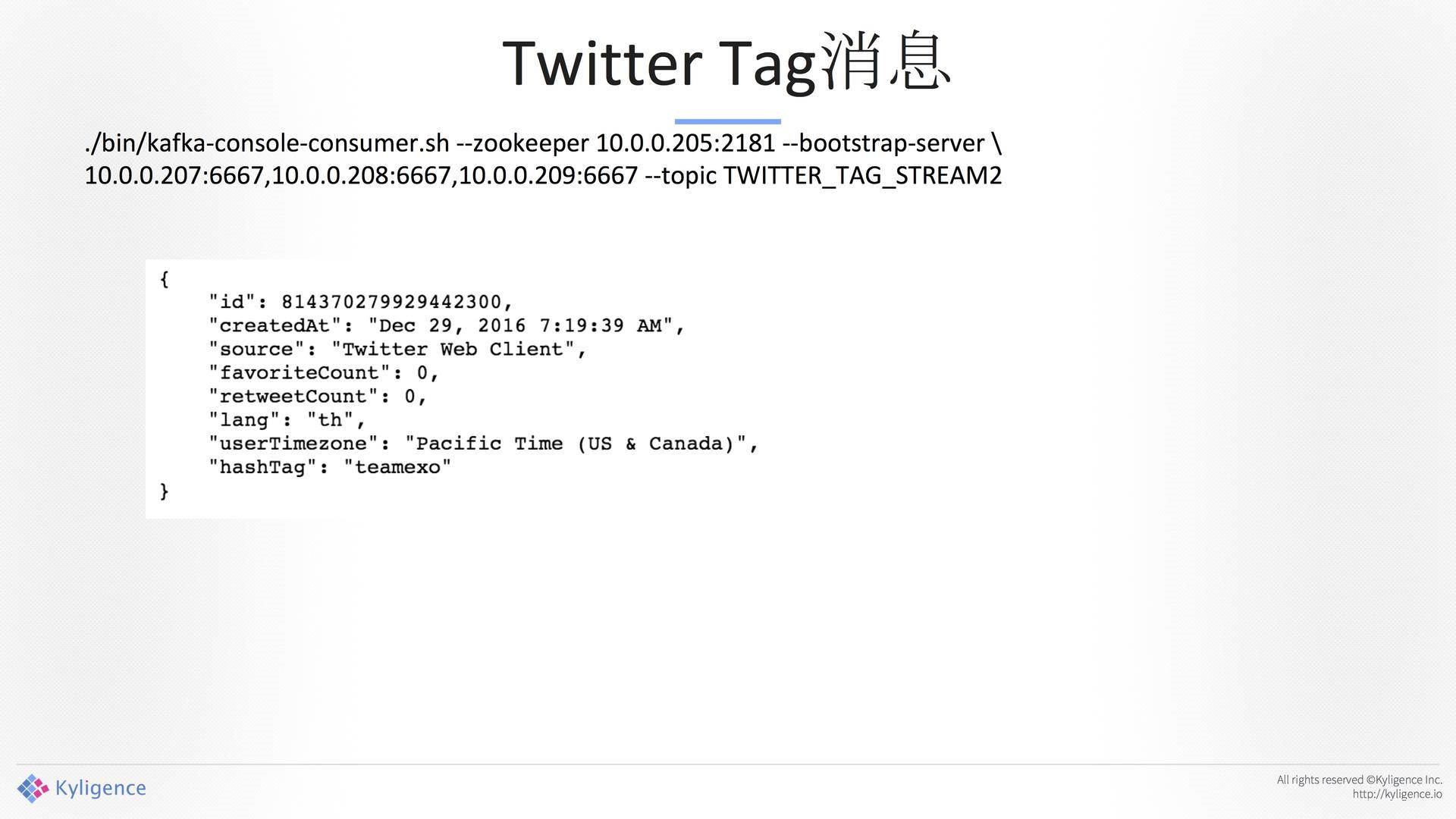
Twitter的Tag消息,如下图所示。总统大选上有很多Tag,Tag上有很多数字。
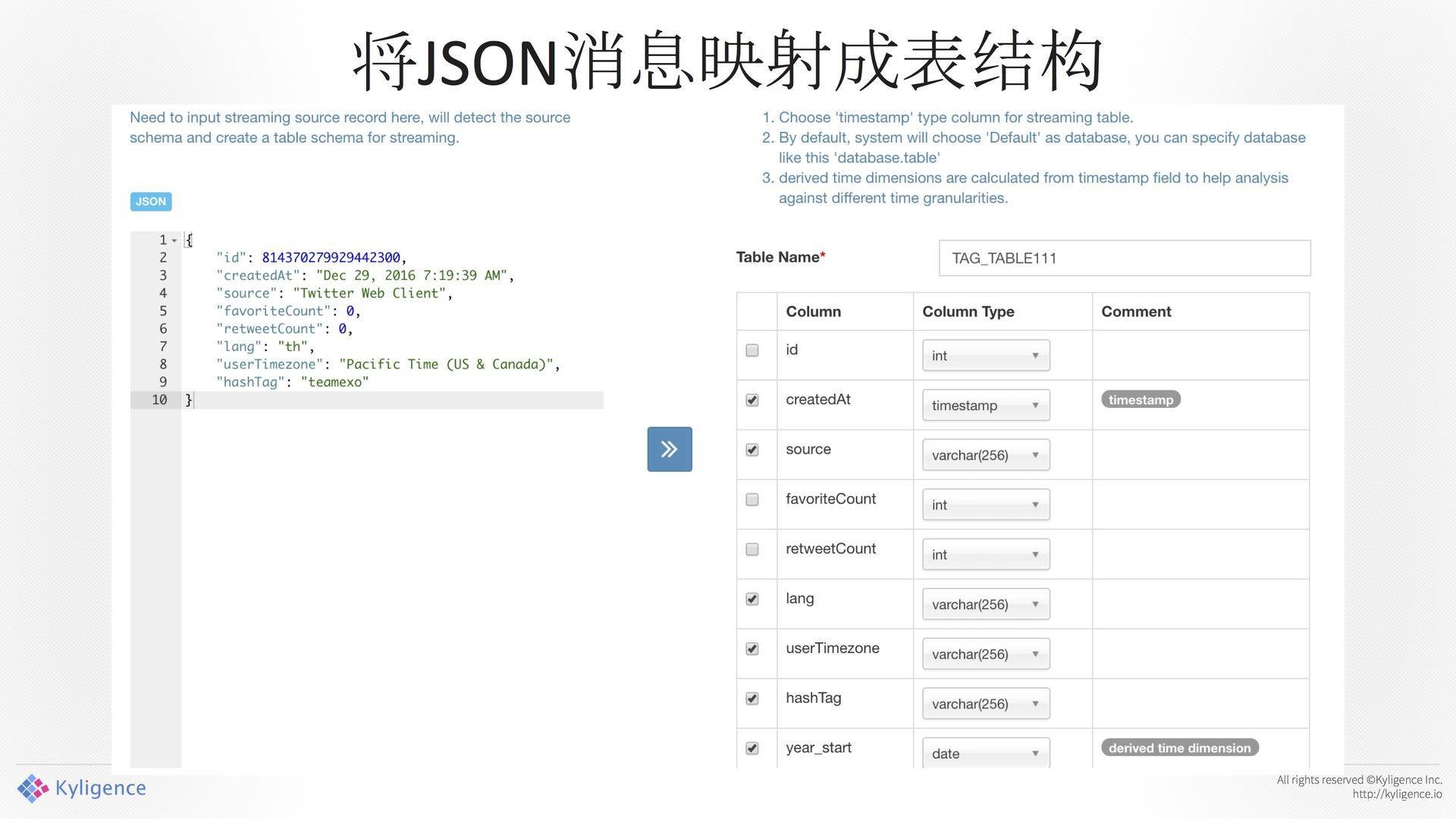
将JSON消息映射成表结构
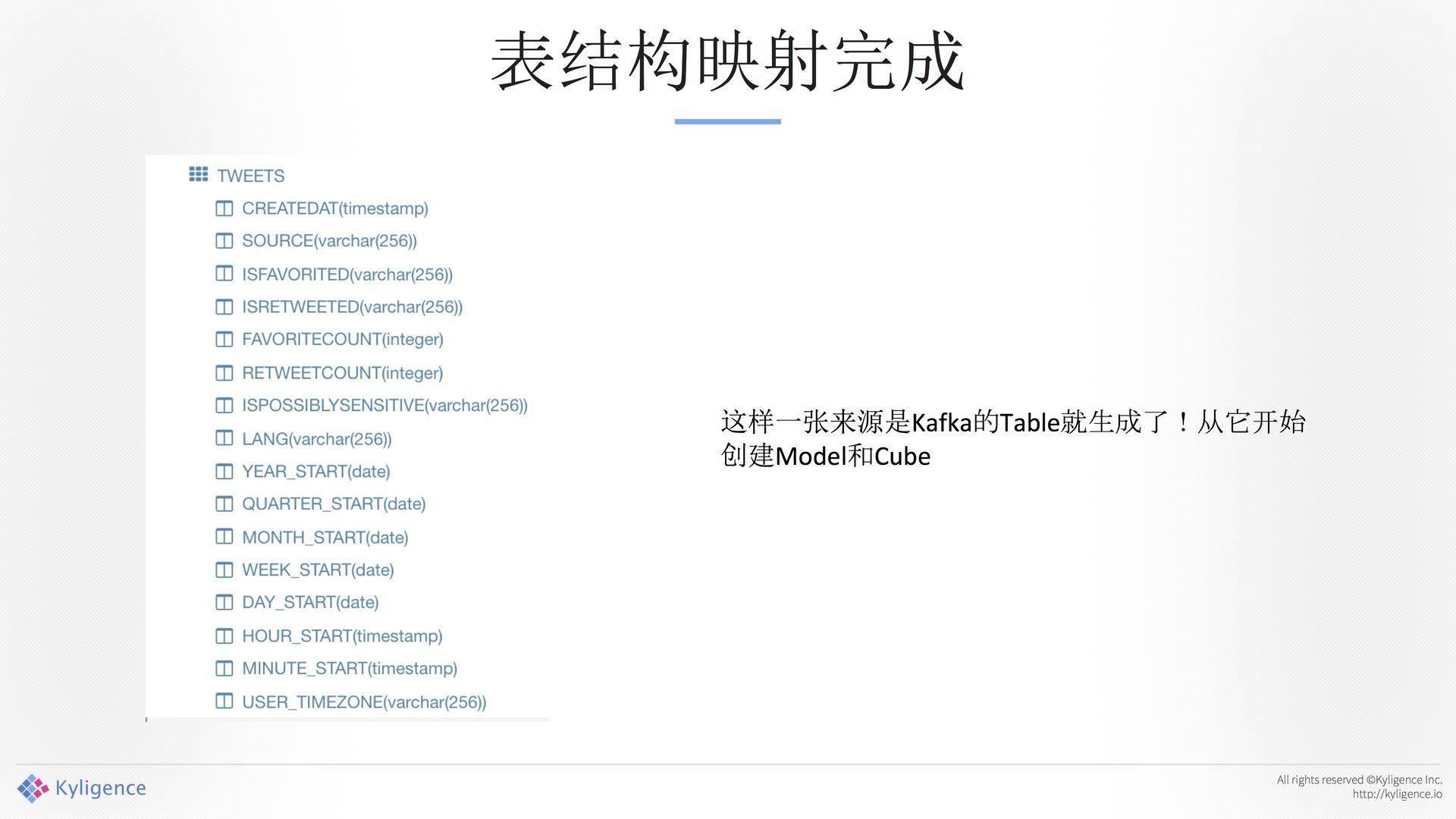
通过图形化界面把它抽象成一张表,如图12所示。前面是JSON的东西,我们通过图像界面把它抽象成一张表,在这里模拟了一个Table。重要的一点是需要去指定Column Type,也就是说,Kafka过来的那个东西是不带类型的,你在转换的过程中先指定它,后面会用到这个转换,否则一些数字、日期会出问题。
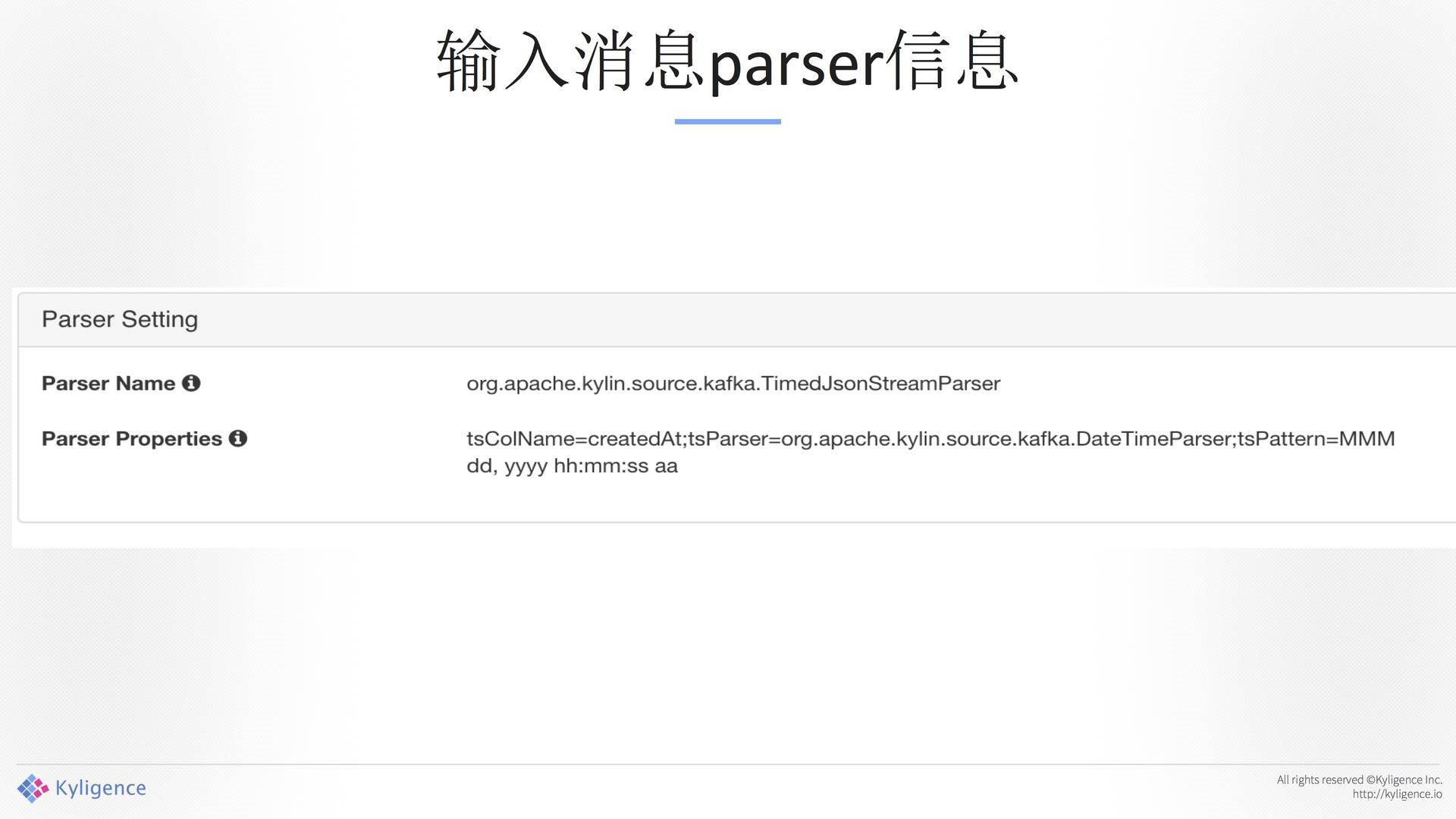
另外一个很重要的东西是解析器,这个解析其是通用的,你可以拿到这个东西去做解析。表结构影射完成。这就是分析师看到的结果,你看到的就是一个Table。构建Cube完之后,数据从Kafka中读出来,基于HDFS上的消息进行,与Hive雷同。





Dashboard,如下图所示。
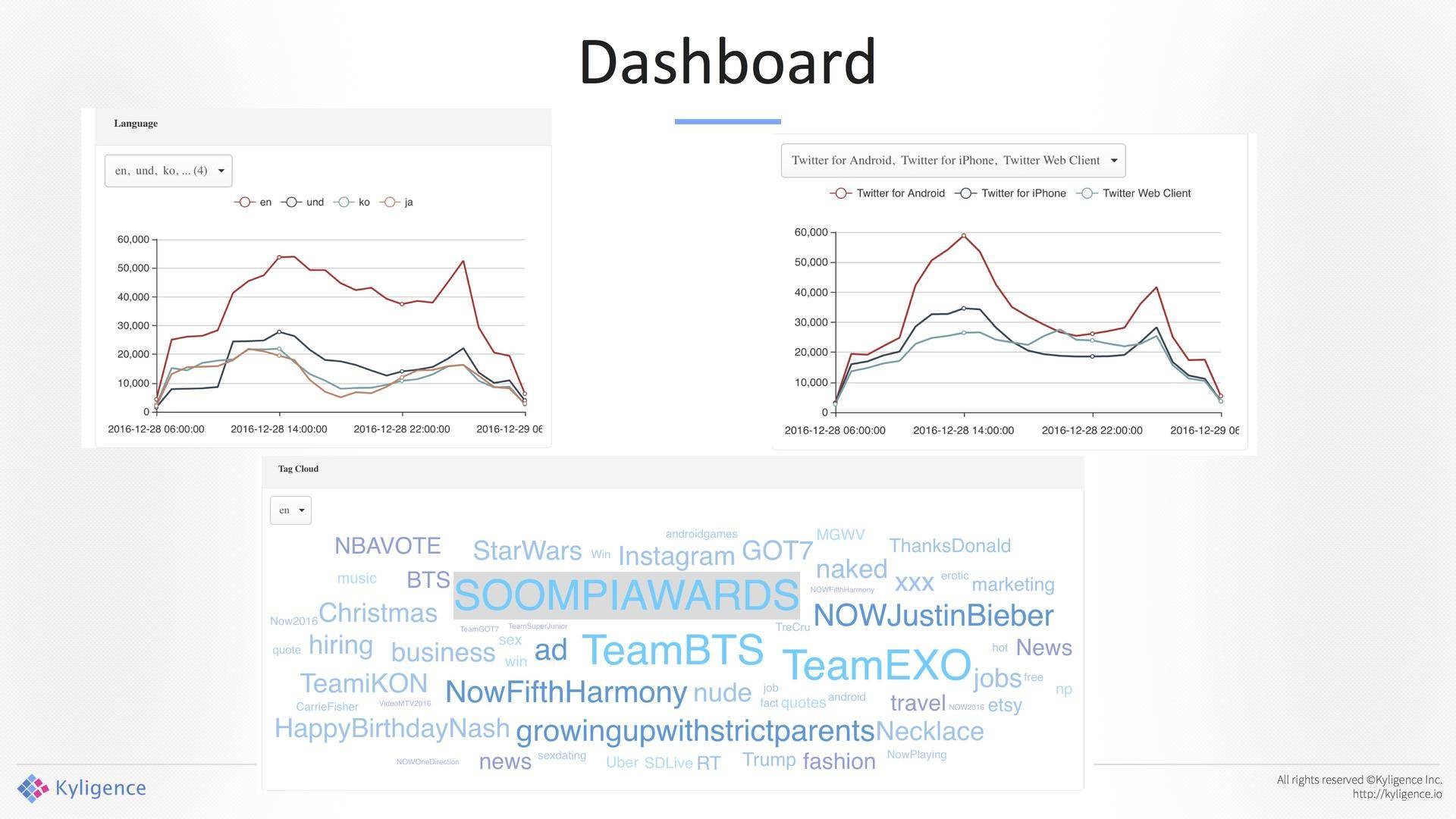
你可以看到这条线,带来的好处是可以把一个批处理的整个框架变成了一个Streming的框架,现在跑在线上大概是5分钟一次,图中的间隔是5分钟,但我们之前做了压力测试,调到了2、3分钟。
左右两张图中都是通过标准的SQL访问的后台,分析师发现用它之后有能力用SQL分析。这个架构还不够不完美,数据还是有两条线,一个数据模型我们可以同时支持批处理和实时处理,但是问题是这两条线是两条路径,未来我们有一个想法数据直接去Memory中去,后台可以直接去读。我们希望降到秒级,对相应的要求比较高,今天还是有很大的挑战。
未来工作
优化Map Reduce引擎,提升构建速度。
尝试持续构建引擎,Spark Streaming/Flink等。明年我们会考虑这方面的应用,希望通过 这些方式更快地处理流的这方面问题。
补充实时节点。
声明:"Apache and Apache Kylin are either registered trademarks or trademarks of The Apache Software Foundation in the US and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks."
阅读原文查看交流实录。





