UC伯克利 NIPS2018 Spotlight论文:依靠视觉想象力的多任务强化学习

来源:AI 科技评论
NIPS 2018 的录用论文近期已经陆续揭开面纱,强化学习毫不意外地仍然是其中一大热门的研究领域。来自加州大学伯克利分校人工智能实验室(BAIR)的研究人员分享了他们获得了 NIPS 2018 spotlight 的研究成果:Visual Reinforcement Learning with Imagined Goals。他们提出了一种只需要图片即可进行视觉监督的强化学习方法,使得机器人能够自主设定目标,并学习达到该目标。下面是 AI 科技评论对该博客的部分编译。

对于机器人,我们希望它能够在非结构化的复杂环境中实现任意目标,例如可以完成各种家务的私人机器人。想要实现这个目标,一个有效的方法是使用深度强化学习,这是一种强大的学习框架,机器人通过最大化奖励函数学到各种行动。然而,经典的强化学习方法通常使用人工设计的奖励函数训练机器人去完成任务。例如,通过每个盘子和器具在桌子上的当前位置和目标位置之间的距离设计奖励函数来训练机器人布置餐桌。这种方法需要人为每个任务单独设计奖励函数,还需要例如物体检测器之类的额外系统作为辅助,这会使得整个系统变得昂贵且脆弱。此外,如果想要机器能够执行各种琐碎的小任务,需要在每个新任务上重复强化学习的训练过程。
尽管在模拟环境中设计奖励函数并建立传感器系统(门角度测量传感器,物体检测传感器等)相当容易,但是到了现实生活中,这种方法并不实用,如最右图所示。
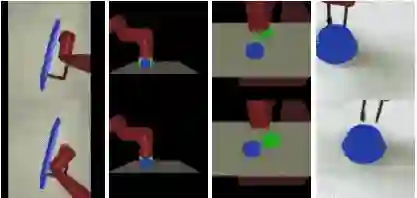
我们的算法只使用视觉就能够训练解决多种问题的智能体,而没有使用额外的设备。上面一行展示了目标图片,下面一行展示了该策略达到这些目标的过程
在下面的博客中,我们将讨论一个无人工监督的,可以同时学习多个不同任务的强化学习算法。对于能够在无人工干预的情况下学会技能的智能体(agent),它必须能够为自己设定目标(goal),与环境交互,并评估自己是否已经达到目标,并朝目标方向改善其行为。在我们的算法中这一切都是通过最原始的观测(图像)来实现的,并没有手动设计的额外装置(如物体检测器)。比如想要让机器人到达指定位置状态,只需给他一张目标状态的图像,机器人就可以学习到到达指定位置的方法。在算法中,我们引入了一个能够设定抽象目标,并向目标主动学习的系统。我们还展示了智能体如何通过这些自主学习技能来执行各种用户指定的目标(例如推动物体,抓取物体,开门等),而无需针对每个任务的额外训练。文章的最后展示了我们的方法足够有效,可以在现实世界的 Swayer 机器人中工作。机器人可以自主学习设定目标并实现目标,在仅有图像作为系统输入的前提下,将目标推到指定位置。
给定目标的强化学习
想要实现强化学习,首先要面对一个问题:我们应该如何表示世界的状态和想要达到的目标呢?在多任务情况下,枚举机器人可能需要注意的所有对象是不现实的:对象的数量和类型在不同情况下会有所不同,并且想准确检测出它们还需要专用的视觉处理方法。换一种思路,我们可以直接在机器人的传感器上操作,用机器人相机传感器捕捉到的图片表示当前真实世界的状态,将我们希望世界是什么样子的图片作为目标。想要为机器人制定新任务,用户只需提供一个目标图像即可,比如希望盘子下图样子的图片。在未来,这项工作可以扩展到更复杂的方式来指定目标,比如通过语言或者演示等来指定。
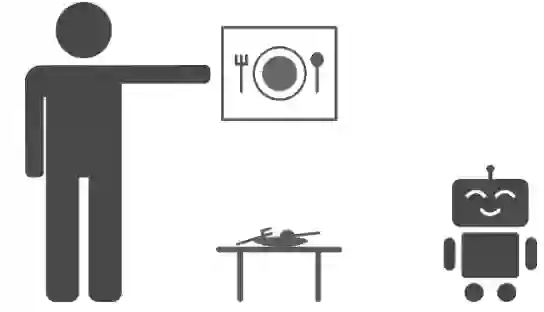
目标任务:将世界变成图像中的样子
强化学习的核心思路是训练机器人最大化奖励函数。对于给定目标的强化学习方法,奖励函数的一种选择是当前状态和目标状态之间距离的相反数,因此最大化奖励函数即等价于最小化当前状态到目标状态的距离。
我们可以训练一个策略来最大化奖励函数,这样学习一个给定目标的 Q 函数就可以达到目标状态。一个给定目标的 Q 函数 Q(s,a,g) 能够告诉我们,在给定状态 s 和目标 g 时,行动 a 的好坏。比如,一个 Q 函数可以告诉我们:「如果我拿着一个盘子(状态 s)并且想把盘子放在桌子上(目标 g),那么举手(行动 a)这个动作有多好?」一旦将此 Q 函数训练好,就可以通过执行下面的优化策略来提取给定目标的策略:
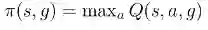
该公式可以简单的总结为:「根据 Q 函数选择最好的行动」。通过使用这个过程,我们能够得到最大化所有奖励函数之和的策略,即达到不同目标。
Q学习流行的一大原因是:它能够以离线策略的形式执行,即我们训练 Q 函数所需的所有信息仅为(状态,行动,下一步状态,目标,奖励)的采样:(s, a, s', g, r)。这些数据可以通过任何策略收集到,而且可以被多个任务重复利用。因此一个简单的给定目标的Q学习算法流程如下:
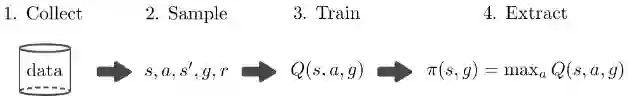
训练过程中的最大瓶颈在于收集数据。如果我们能够人工生成更多数据,我们就能够在理论上学习解决多种任务,甚至不需要与真实世界交互。然而不幸的是,想得到准确的真实世界模型相当困难,所以我们通常不得不依赖于采样以得到(状态-行动-下一状态)的数据:(s,a,s')。然而,如果我们能够修改奖励函数 r(s, g), 我们就可以反过头重新标注目标,并重新计算奖励,这样就使得我们能够在给定一个(s, a, s')元组的情况下,人工生成更多数据。所以我们可以将训练过程修改为如下:

这种目标重采样的方法的好处是,我们可以同时学习如何一次实现多个目标,而无需从环境中获取更多数据。总的来说,这种简单的修改可以大大加快学习速度。
要想实现上述方法,需要有两个主要假设:(1)知道奖励函数的形式。(2)知道目标的采样分布 p(g)。之前有研究者使用这种目标重标注策略的工作( Kaelbling '93 , Andrychowicz '17 , Pong '18,https://people.csail.mit.edu/lpk/papers/ijcai93.ps)是在真实的状态信息上操作(比如物体的笛卡尔位置),这就很容易手动设计目标分布p(g)和奖励函数。
然而,在目标状态是图像的基于视觉的任务上,这两个假设在实际中都不成立。首先,我们不清楚应该使用哪种奖励函数,因为与当前状态图像与目标状态图像之间的像素级距离可能在语义上没有任何意义。其次,因为我们的目标是图像,对于第二个假设,我们需要知道一个目标图像的分布 p(g),使得我们可以从中对目标图像进行采样。然而图像的分布相当复杂,手动设计目标图像的分布是一个相当困难的任务,图像生成仍然是一个活跃的研究领域。因此,为了解决这两个问题,在我们的算法中我们希望智能体能够自主想象出自己的目标,并学习如何实现这些目标。
使用想象的目标的强化学习
图像作为一种高维信息,直接进行处理相当困难。因此可以通过学习图像的表示,并使用这种表示来代替图像本身,以减轻给定目标图像的 Q 强化学习的挑战。关键问题是:这种表示应该满足哪些属性?为了计算语义上有意义的奖励,需要一种能够捕捉到图像变化隐变量的表示。此外,需要一种能够轻松生成新目标的方法。
我们通过首先训练一个生成隐变量的模型来实现这个目标,我门使用了一个变分自动编码机(variational autoencoder, VAE)。该生成模型将高维观察 X,如图像,转换到低维隐变量 z 中,反之亦然。训练该模型使得隐变量能够捕捉图像中变化的潜在变量,这与人类解释世界和目标的抽象表示类似。给定当前图像 x 和目标图像 xg,将它们分别转换为隐变量 z 和 zg。然后使用这些隐变量来表示强化学习算法的状态和目标。在这个低维隐空间上而不是直接在图像上学习Q函数和策略能够有效加快学习的速度。
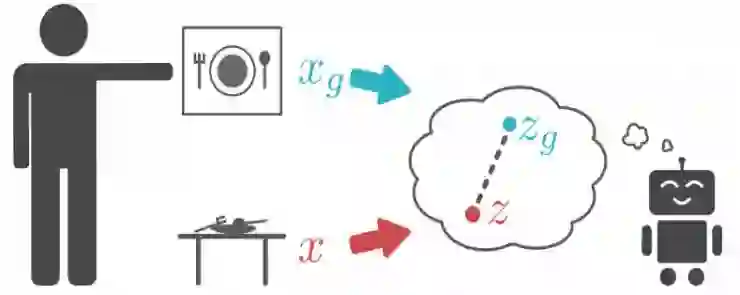
智能体将当前图像(x)和目标图像(xg)编码到隐空间,使用隐空间中的距离作为奖励函数。
使用图像和目标的隐变量表示也解决了另一个问题:如何计算奖励。使用隐空间中的距离来作为智能体的奖励,而不是使用像素级的距离。在完整论文中,我们展示了这种方法与最大化达到目标的概率的目的相符合,而且能够提供更有效的学习信号。
这种生成模型也很重要,因为它使得智能体能够更容易地在隐空间中生成目标。特别的是,我们的生成模型能够使在隐变量空间中的采样变得不重要:我们只是从VAE先验中采样隐变量。我们使用这种采样机制主要有两种原因:首先,它为智能体设置自己的目标提供了一种机制。智能体只是从生成模型中对隐变量的值进行采样,并尝试达到该隐目标。第二,该重采样机制也可以被用于上面提到的重新标记目标的过程中。因为生成模型经过训练,可以将真实图像编码到先验图像中,所以从隐变量先验中采样可以生成有意义的隐目标。
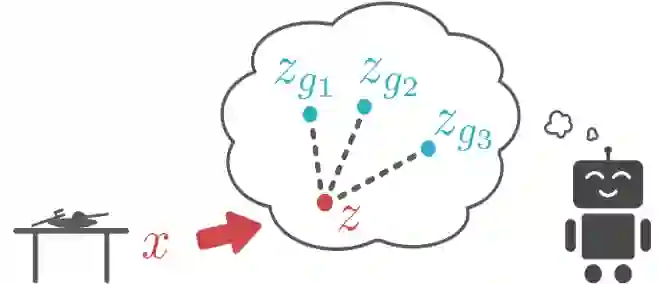
即使没有人提供目标,智能体也能够生成它自己的目标
总之,图像的隐变量能够(1)捕捉场景的潜在因素,(2)提供有意义的距离进行优化,(3)提供有效的目标采样机制,允许我们有效训练能够在像素上直接操作的给定目标的强化学习智能体。我们将这个整个方法称为具有想象目标的强化学习(reinforcement learning with imagined goals, RIG).
实验
我们进行了实验,以测试 RIG 是否具有足够的采样效率,能够在合理的时间内训练好真实世界的机器人策略。我们测试了机器人的两种能力:达到用户指定的位置,和将物体推到目标图像所示的位置。机器人首先将输入的目标图像映射到隐空间中,作为自己的目标来学习。我们可以使用解码器从隐空间映射回图片来可视化机器人想象中的目标。在下面的动图中,上面显示了解码出来的“想象”中的目标,而下面一行显示了实际策略执行的情况

机器人设定它自己的目标(上图),练习达到这个目标(下图)
通过设定自己的目标,机器人可以自主的训练达到不同的位置而无需人为参与。只有当人想要机器人执行特定任务时,才需要人类参与。此时,给予机器人目标图像。因为机器人已经通过练习,能够实现很多种目标,可以看到它在没有经过额外训练的情况下,即能实现这个目标。

人类给一个目标图像(上图),机器人达到这个目标(下图)
下面展示了使用 RIG 训练了将物体推到指定区域的策略:

左:Sawyer机器人初始化。右:人类给出一个目标图片(上图),机器人达到该目标(下图)
直接从图像训练强化学习的策略可以轻松地在不同的任务中切换,如使机器人到达某个位置变成推动某个物体。只需改变一下物体重新拍一下照片即可。最后,尽管直接根据像素进行工作,这些实验并没有花费很长时间。到达指定位置,只需一小时的训练时间,而推动物体到某位置需要 4.5 小时。许多真实世界的机器人强化学习需要真实的机器人状态信息如物体的位置。然而,这通常需要更多的机器,购买并设置额外的传感器或者训练物体检测系统。相比这下,本方法只需 RGB 相机就可以直接从图像中进行工作。
对于更多结果,包括各部分对性能的提升以及与基准方法的对比,大家可以阅读原始论文:https://arxiv.org/abs/1807.04742
未来发展方向
我们已经证明,可以直接从图像训练真实世界的机器人策略,同时可以以高效的方式实现各种任务。这个项目有很多令人兴奋的后续发展。可能有一些任务无法用目标图像表示,但是可以用其他模态的信息来表示(如语言和演示)。此外,我们虽然提供了一种机制来对自主探索的目标进行采样,但我们能否以更有理论指导的方式选择这些目标来进行更好的探索?结合内部动机的思路能够使得我们的模型更积极的选择能够更快达到目标的策略。
未来的另外一个方向是训练更好的生成模型,使其能够理解动态信息。将环境的动态信息编码能够使隐空间更适合于强化学习,从而加快学习速度。最后,有些机器人任务的状态难以用传感器捕捉到,例如操纵可变性对象或者处理数量可变的对象的场景。进一步拓展 RIG 使得它能够解决这些任务将是令人兴奋的。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”





