拜托!这才是分布式系统CAP的正确打开方式!



前言
纠结了很久要不要写这一篇,作为分布式系统的核心理论简单说说容易,聊透却很难,转念一想,如果不写这篇,算什么想通透大数据呢!并且这本身就违背了我写作的初衷;加之正好前几天和同事以ZooKeeper的用户行为反推了CAP理论,回过头来细琢磨了下,还蛮有意思的!闲话少絮,我们进入正题!
本文宗旨:深入浅出!聊透!

“纸面”上的CAP
相信很多同学都听过CAP这个理论,为了避免我们认知不同,我们先来统一下知识起点。
CAP理论在1999年一经提出就成为了分布式系统领域的顶级教义。并表明分布式服务中,存在三要素:一致性、可用性、分区容错性。而“CAP”就是Consistency/Availability/Partition Tolerance三个单词缩写。
一致性:分布式系统中,一份数据一般会存在多个副本,要求多副本数据对于数据的更新与单份数据相同,即强一致性。
可用性:在任意的时刻,对分布式系统来说要保证在限定延时内正常响应客户端的读写请求,并且不会报错。(提前纠正一个误区,这里的可用性并不是咱们通常理解的服务的SLA可用性,即3个9、4个9之类的定义。实际上指的是是数据访问的可达性。)
分区容错性:在分布式服务中,节点之间网络通信异常导致(丢包、延迟、中断等)的网络分区现象是必然存在的,要保证出现网络分区现象时,分布式系统不受影响。
-
原论述表明CAP是不可以兼得的,一个系统需要放宽一点才能满足其他两点,因此此时对于分布式系统来说其实就三个选项CP、AP、CA三种,但是不能同时满足CAP。但是由于网络问题是不可避免的现象,所以预想的分布式系统都会往AP和CP上去权衡靠拢。如下所示:
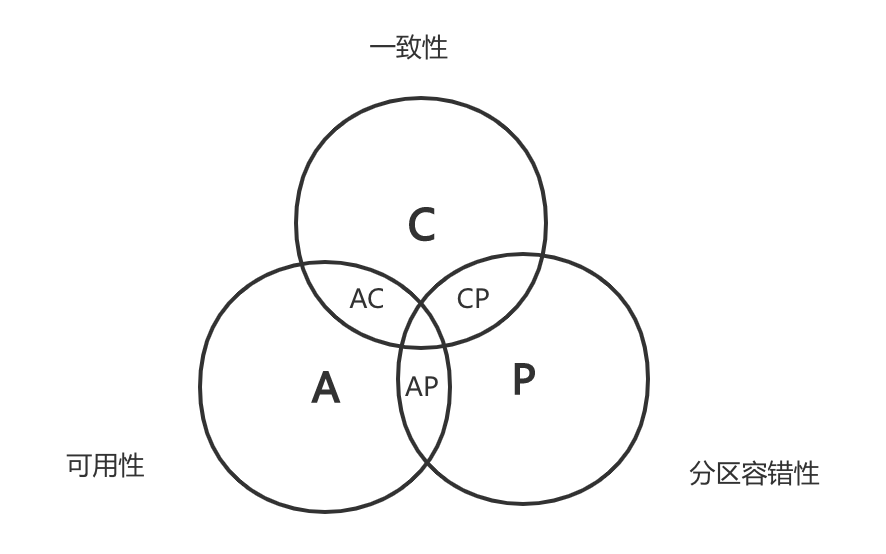
尝试沙盘推演分布式系统的CA、AP、CP选型
1. 先说说CA选型
实际上CA选型对于我们来说并不陌生,Oracle和MySQL数据库就是最好的例子,他们拥有强一致性和可用性,虽然Oracle RAC看似是分布式,但是依然选择节点本身的共享存储或者逻辑ASM存储;MySQL主从实际上可以理解成多个单点MySQL,通过Binlog数据同步逐渐将数据同步到所有单点上,写主读从,因此依旧是是单点的CA系统,舍弃了P。我们暂时不讨论数据库事务。这里我们主要还是聊聊正儿八经的分布式系统。
2. 为什么CP系统不能满足A?
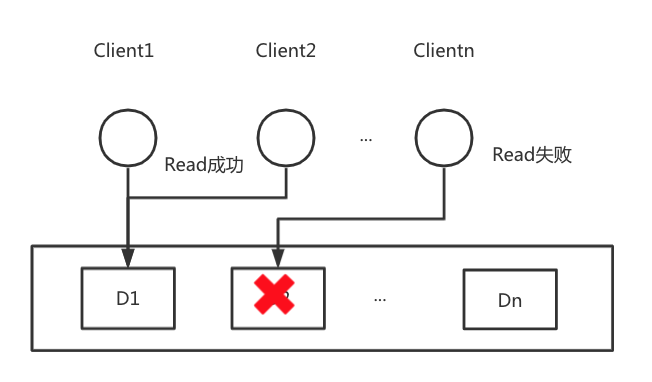
CP系统意味着是数据是单副本,分布在多个节点上,如下图所示,D1-Dn代表着分布式系统的多个节点,当不同的Client访问节点上的数据时,由于不涉及副本数据的同步,每个节点都是最新的数据,数据必然是强一致性的。此时是满足C、P要素。但是此时如果发生网络分区问题,那么数据就必然丢失不可访问了,此时可用性A受到了影响。
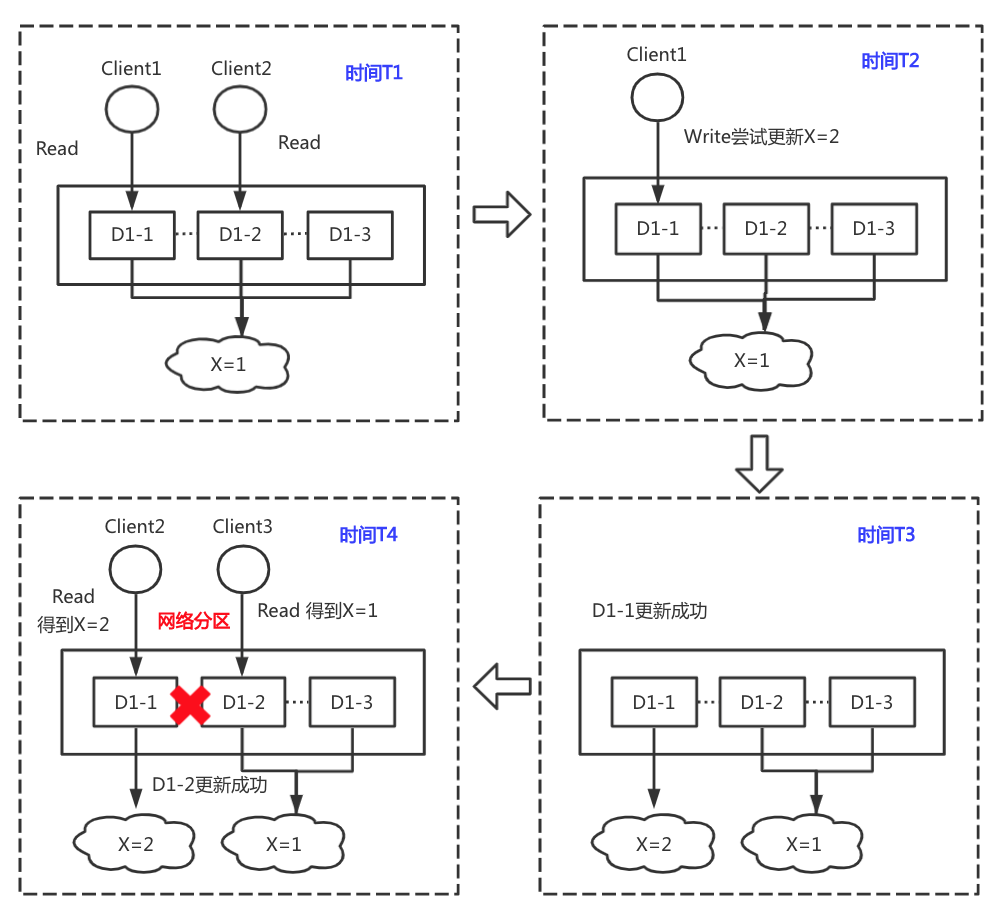
AP系统意味着数据是有多副本的,即使出现网络分区问题,也不会丢失数据导致不可用,但是会存在数据一致性问题。如下图所示,数据D1有3个副本,D1-1、D1-2、D1-3,并且分布在不同节点上。在T1时刻,正常情况下每个客户端读到的数据都是X=1,在T2时刻,Client1尝试将数据更新为X=2,接下来T3时刻请求到达分布式系统后端,将D1-1副本数据更新成功,但是在T4时刻数据副本D1-1和D1-2副本之间出现网络分区问题,D1-2并未被置成X=2,此时Client2和Client3读一份数据就出现了不同的返回值,虽然数据可达,但是由此带来了数据一致性问题。
 AP选型
AP选型
如果看到这里并且理解了,那么恭喜你,证明你对分布式确实有一定的理解了。我们再接再厉,继续往下看,相信你对CAP的理解会上一个层次。

在CAP中“迷失”
在上一节中我们解析了“纸面”上的CAP,按照其推论,分布式系统的世界看似很完美,绝大多数架构师也将CAP奉为第一原则,在设计系统之初就选择倾向于CP或者AP。即为了保证强一致性牺牲可用性或者为了可用性而降低一致性。
可是仔细一想,上一节所讲述的分布式世界真的这么完美吗?细细想来,误区太多了!
误区一 "三选二"的先入为主
尽管网络问题在我们日常运营分布式系统中经常发生,但是相比正常时间,网络分区依然是小概率事件,因此并不应该在设计之处就放弃C或者A,在正常情况下分布式系统一定是要同时兼顾CAP。
误区二 CAP的定义极端
在上面的CAP理论中,分布式系统在网络分区的既定现实下一定会保证P,而在A、C中选取其一,但事实上A、C的选择并不是非黑即白的。因此上面的CAP理论过于粗旷笼统。
设计具体分布式服务时,实际上需要区分多个子模块,如计算模块/调度模块/存储模块等,在遭遇网络分区时,会实行将部分子模块降级等策略,从而细粒度取舍A和C,而不是直接影响整个服务、所有数据。
误区三 CAP的标准模糊
CAP理论中只为C、A、P定义概念,但是却不定义标准,C、A、P3个要素都是定义在时间这个维度的基础上,一切都是基于时间视图,多长时间的数据算不违反一致性呢?多久的访问时间算影响数据访问的可用性呢?或者再较真一点,多久时间的网络问题算作网络分区呢?一切的本质都是时间。因此在理论基础上需要将CAP定性细分。
针对网络分区可以按照一定通信周期,分敛成单机网络分区、机器组网络分区(比如HDFS的机架感知实际上就是针对的就是后者);
针对一致性可以分成若干种一致性程度(后面的文章会讲到);
针对数据访问效率来说,按照P95/P99读写进行数据访问性能的进行区分也不失为一种手段。
误区四 CAP理论是否要带Client玩?
CAP理论中并没有明确系统边界范围,一个分布式系统不包括Client那算什么分布式系统的呢?这里我们就来唠唠CAP理论为什么不包括Client。因为如果算上client的话,分布式集群将更为复杂。
假设网络分区发生在Cient和分布式服务中间,那么A肯定就无法达到了。
分布式服务一致性的效果就不是这么明显了,因为读请求都到不了分布式系统。
如果Client和分布式服务中间发生网络分区,此时分布式服务无论再怎么努力其实都是无用的。

CAP的正确打开方式
上面提到了,由于传统CAP理论的存在一些误区点,其将很多同学带入错误的方向上,这里开始我们聊一聊CAP的正确打开方式。
CAP的目标状
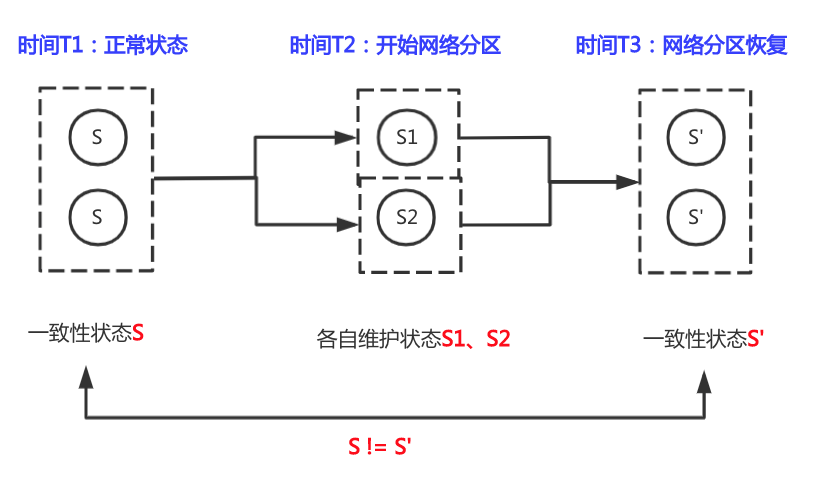
如上图所示:在未发生网络分区的T1时刻,这时的分布式系统是同时满足CAP三要素的,各份数据一致性状态是S,当到了T2时刻,发生了网络分区情况,此时各个节点,会记录各个节点的状态S1、S2,当T3时刻网络分区恢复时,需要将S1、S2状态进行相应处理,这里的部分实际上是很多分布式服务的重点:比如可以通过log end offset(Kafka)或者transaction id(Zookeeper)在分区发生后进行leader比对选举,然后再进行数据同步。
精细化CAP理论
CAP为我们打开了一扇大门,但是过于宽泛无法适合所有场景,比如不适合数据库事务,而强一致性C也会使得服务应用场景受限,因此理论需要细分领域,根据不同场景进行分类。
1.ACID原则
原子性(Atomicity)在事务中一个事务要么成功,要么失败。不允许一个事务成功一半失败一半。原子性就像我中午午休经常会去超市买水果,要么就买选苹果+结完账才算购买成功;苹果没选好或者选好了没结账 都不算购买成功。
一致性(Consistency)在事务的开始和结束时,需要满足一致性约束条件。什么是一致性约束,咱们依旧拿去超市买苹果举例,超市只剩下20个苹果了,我买了一个,对应的超市就应该减去一个苹果。另外注意ACID中的一致性,是逻辑的一致性,而不是CAP中数据的一致性。
独立性(Isolation)如果有多个事务同时发生,互相之间不能被影响,并且不知道对方的存在。咱们还去买苹果,我挑了苹果去结账,有个大妈也挑了苹果也去结账。这时我们之间是互不影响的,相互独立的。我没带钱买苹果失败也不影响大妈买苹果成功。当然如果结完账大妈看小伙子我长得帅,硬给我塞几个苹果,我也没办法😄
持久性(Durability)当事务运行成功的时候,对整个系统来说,这个更新就是永久的。我们依旧去去买苹果,买完苹果结账之后,如果苹果是好的,我想退款,超市是不会给我退的,对于超市来说这个账单永久的,除非我买到了坏苹果并且退款成功。
以上就是数据库系统里的ACID原则,主要针对数据库事务,分布式事务我们后续的文章会讲到。
2.BASE原则(这里就不用买苹果举例了,因为找不到同一个苹果的多个副本。😄 )
基本可用(Basically Available)系统大多数时间是可用的,允许偶尔的失败。相比CAP的可用性来说,BASE中的基本可用,是允许分布式服务在请求响应时间上有损失的,原来10ms返回,现在100ms也不算做异常。
软状态(Soft State)允许分布式系统中的数据存在一个中间状态,这就意味允许系统在多个不同节点的数据副本存在数据延时。比如Kafka 的partition多个replica之间并不是一直同步的。相比CAP强一致性这种硬状态来说,BASE中的S是允许同一数据的多副本之间存在延时的软状态。
最终一致性(Eventual Consistency)上面说到允许分布式系统存在中间的软状态,但是总得有个时间期限。否则就没法玩儿了。在这个时间周期过后,必须保证所有副本保持数据一致性。从而达到数据的最终一致性。
3.CAP和BASE、ACID的关系
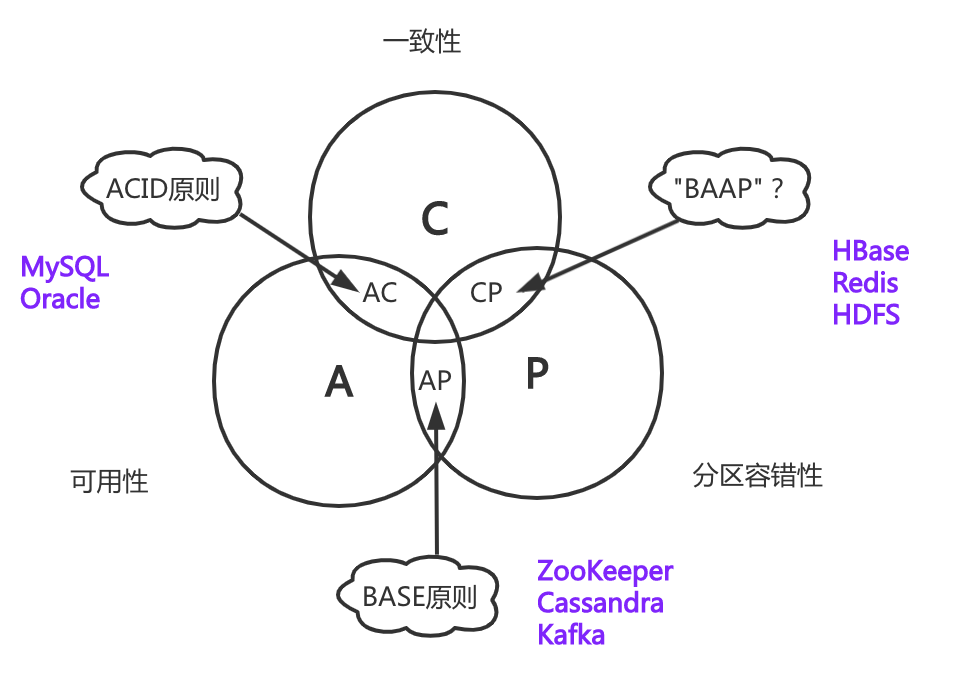
如上图所示,BASE和ACID实际上是CAP在不同选型的细分理论,CA的选型对应ACID原则,主要针对数据库系统Oracle、MySQL等,AP选型对应BASE原则,比如Cassandra、Zookeeper、HDFS,而CP选型很遗憾目前还没有一个原则能对应上。但是不妨碍咱们造一个,比如“BACP”,即基本可用、强一致性、分区容错性,其对应的系统如HBase、Redis。
虽然CAP想在任意时刻都满足比较难,但是还是不妨碍有巅峰产品问世,比如谷歌的Spanner虽然是CP系统,但是由于可用性非常之高,让用户一直以为他是CAP的产品,其依赖谷歌自建广域网,让我了解到基建的发达也是解决分布式系统网络分区问题的另一个方向;Tidb作为国内的开源代表,也是CP系统,虽然他距离Spanner还有差距,但是他公司的名字PingCAP让我觉得,赶超只是时间问题。此外还有OceanBase也非常不错,这块了解的较少,以后有机会了解下。
至此CAP就解析完了,如果你能看到这里,我必须手动点赞!祝咱们在大数据的路上越走越远!相信坚持总会有所收获!!!


更多精彩推荐
☞ 有史以来最伟大的计算机天才?这位富士通程序员厉害了! ☞ 10 行 Python 代码自动清理电脑重复文件,解放双手! ☞ 据说,程序员已成为女生年度最喜欢男友职业Top3? ☞ 鸿蒙加海思,麒麟加龙芯,组合拳能否渡劫“生态”危机 ☞ 阿里工程师用 8 张图告诉你如何存储、管理泛内容数据 ☞ 科普 | Eth2 验证者如何生成和保护取款密钥 ![]()
点分享 ![]()
点点赞 ![]()
点在看








