群众的眼睛是雪亮的吗?当真相掌握在少数人手中

►图片来源:Pixaby.com
撰文 | 孙梦逸
责编 | 陈晓雪
● ● ●
一百多年前,现代统计学奠基人之一,弗朗西斯·高尔顿(Francis Galton)爵士,在Nature上发表了一篇标题为“群众之声”(Vox populi)的短文。短文的故事非常简单:在英国普利茅斯市的一个家畜展览会上,人们竞猜一头肥牛被宰杀后的重量,猜的最准的人将会获得一定的奖励。唯一被允许的猜测手段是目测。可以想见,大家猜测的结果会十分粗糙。结果的确如此:大多数人的猜测和正确的重量相差都在几十磅左右。让人惊讶的是,群体的中值离正确的答案只差了9磅,远比大多数人的表现为佳。自那之后,“群智”的理念就流传开来:群体做出的决策,往往能够比个体的决策更为精确。“群众的眼睛是雪亮的”,即使群众中的每一个个体视力可能都不怎么好。
网络时代让收集群众意见更为容易,群体在公共决策方面可能发挥的作用也让人们寄予厚望。
群智的理论基础,大致来说是每一个人对特定的问题有相互独立的判断或信息,因此,尽管每一个个体都会出错,但是大家错的方向会不一样,错处相互抵消。这种情况下,公认的选项,或是权衡各方意见得出的折中的方案,最有可能是最合适的方案。
但是,通过群智得到最合适的方案,仰赖于解决问题所需要的信息和思考模型在人群中的分布相对独立,或是问题非常简单,大多数人都能通过常识做出正确判断。实际上,群智并不是在任何情况下都会获得好的效果。对于很多公共议题,以上的假设都不一定成立。
其中一类群智可能很容易栽跟头的问题,是当解决问题的关键信息并不为大众所知的时候。举一个简单的例子:假设你是一个对美国地理丝毫不了解的人,面对这样一个问题:费城是宾夕法尼亚的首府吗?为了解决这个问题,你求助于大众,希望借助群众的力量解决问题。于是你发放了一个问卷,问卷上有是和否两个选项。稍有常识的人都会知道,费城是宾夕法尼亚的一个重要的大城市,而按照常理,首府应该是比较重要的城市吧。于是大多数人都会选择是。不幸的是,宾夕法尼亚的首府是名不见经传的哈里斯堡,不是费城。
这个例子并非信口开河:麻省理工学院和普林斯顿大学的科学家们就亲自做了这样一个问卷调查。如图一a所示,确实大多数的人都选择了错误的答案:
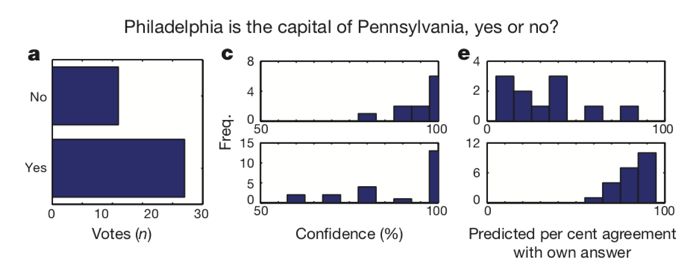
►图一(来源:参考文献[3])
这样的问题并不鲜见,而且很多问题并非无关痛痒:一个很熟悉的例子,就是转基因作物是否应该大规模应用。决策所需要的信息包括转基因的利与弊,这样的信息往往存在于需要一定阅读门槛的学术文献中,并不能够为平常大众轻易接触到。因此,如何在此类情况下做出正确合理的决策就尤为重要。
人们曾就这些问题提出过许多解决手段,其中一种是在问卷调查的同时,询问人们对自己答案的信心,根据其自信程度给予其答案相应的权重。其基本的思路是,能够做出正确判断的人通常对自己的答案更为自信。这个思路在一定程度上确实能够增加调查的准确度。
然而,这一方法大部分情况下并不十分有效,原因是人们往往对自己的判断过于自信。这一现象也可以在图一c中看到:人们就算错也错得非常自信。做出这个问卷调查的科学家,John McCoy, Drazen Prelec和Sebastian Seung另辟蹊径,想了一个独特的解决办法。这里顺带插一句,Sebastian Seung 教授算是著名网红,是科普书《连接组》(Connectome)的作者,主攻方向是计算神经科学。
几位科学家在问卷调查之外,问了一个简单的问题:请问你觉得人群中有多少人的答案和你的的答案一样?如图一e所示,对这一问题的答案,两组人给出了截然不同的结论:在给出错误答案的人群中,人们倾向于觉得大家和自己的答案是一致的,而给出正确答案的人群中,人们倾向于认为大多数人和自己的答案并不一致。
这底下的道理,说穿了并不难理解:知道费城不是宾夕法尼亚首府的人,大概率是知道哈里斯堡才是宾夕法尼亚首府的,而且他们很可能也知道这个信息不为大众所知。因此,他们会做出大多数人和自己选择并不一致的推断。而选择错误的人则不会做出类似的推断——他们依据的是大众都知道的信息,因此他们会预计大多数人和自己的答案会一致。根据这种预测的不对称性,几位科学家设计了两种方案来从调查结果推断最有可能的正确答案:
第一种方案是评估答案的“意外流行程度”(surprisingly popular)。其理论依据是,得出错误答案的人,很有可能会低估正确答案的流行程度:毕竟他们并不知道得出正确答案所需要的稀少信息,很有可能会假设大多数(甚至所有)人和自己的答案是一样的。而得出正确答案的人,也不大可能高估正确答案的流行程度:毕竟他们很可能会知道大多数人会猜错。那么综合所有人的预测,人群总体应该会低估正确答案的流行程度。把人群的预测答案分布和真实的答案分布做比较,比预测的答案更流行的答案,就更有可能是正确的答案。
为了评估这一方案的有效性,几位科学家进行了四类问卷调查:第一类是上文提到的首府问题;第二类是细节问答:问题的范围涵盖了历史、人文、科学地理等;第三类问题是考验医生对皮肤癌的诊断;最后一类问题是对艺术作品进行估价。如图二所示(图中绿色条形柱代表新设计的“意外流行程度”方法),新设计的“意外流行程度”方案的表现是现存所有常用的统计手段中最好的。
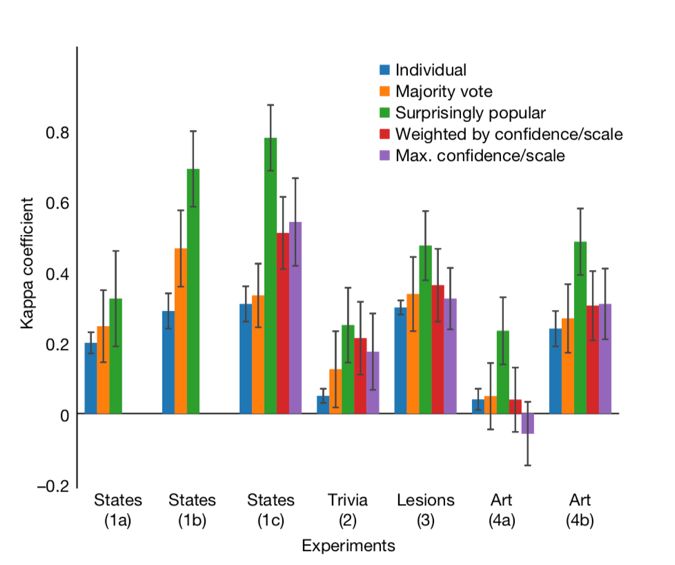
►图二(来源:参考文献[3])
四类问题涵盖范围广阔,也从一定程度上证明了这种新方法的适用广泛性。
另外一种方案较为复杂,叫做“最不惊讶”(Least surprised by the truth)原则。大致意思是计算给出不同答案的人群中,对正确答案感到意外的程度。最不吃惊的人,给出的答案更有可能是正确答案。道理说起来好像很好理解:知道正确答案的人当然不会对正确答案感到惊讶。问题是做群体意见征集的时候,正确答案往往并不预先知道(毕竟预先知道还做啥群体意见征集),因此,所谓最不惊讶程度是需要根据贝叶斯原理从当前的答案分布和预测分布往回倒推的,并不十分简单,这里不做具体介绍,有兴趣的可参看文末附带的参考文献[4]。这一研究现在仍在进行中,适用范围和有效度皆有待验证。
这一研究对当今社会的公共决策有着重要的启示。可以预计,如何设计合理的算法通过群众调查作出合理的决策,很长一段时间内都是社会科学值得认真思考的问题。值得注意的是,以上的统计方法虽然新颖独到,依旧依赖于对信息在人群中的分布结构有特定的假设,因此,并非所有问题都能够适用。事实上,当今大部分群智算法都依赖于信息和思考模式在人群的某种特定的分布,并不存在一劳永逸的普适算法。因此,对解决各类社会议题可能需要的信息分布的研究,也许才是以后研究的重点。
另外需要强调的一点是,以上的算法针对的问题往往是价值中立的,只是对事实的判断。而现今的民主决策,往往面对的问题在价值上并不中立(没有绝对正确的答案,需要做的是对各方利益的平衡)。对于这类问题,以上的算法也将不再适用。但是,这并不意味着科学在这类价值判断的问题就无法插足:经济机制设计的大家,诺贝尔奖得主Eric Maskin就在Scientific American上发过一篇小文,对民主投票的设计有精彩的阐述,大家若有兴趣可以参看(参考文献[5])。
大家可以看到,原来科学的触角比我们想象的要广泛得多。一些我们平常认为无法在科学的框架上加以讨论的社会人文的问题,其实是有可能从科学的角度进行分析的。在这个价值碰撞激烈,民粹问题横行的世界,更需科学家们采用科学的视角帮助解决各类复杂的议题。毕竟每一位科学家,都同时是一个社会人。

参考文献:
[1] Galton, Francis. "Vox populi (The wisdom of crowds)." Nature 75.7 (1907):450-451.
[2] Page, Scott E. The difference: How the power of diversity creates better groups, firms, schools, and societies. Princeton University Press, 2008.
[3] Prelec, Dražen, H. Sebastian Seung, and John McCoy. "A solution to thesingle-question crowd wisdom problem." Nature 541.7638 (2017): 532.
[4] Prelec,Drazen, H. Sebastian Seung, and John McCoy. Finding truth even if the crowd is wrong. Working paper, MIT, 2013.
[5] Dasgupta,Partha, and Eric Maskin. "The fairest vote of all." Scientific American 290.3 (2004): 92-97.

孙梦逸
密歇根大学演化生态系博士生,主攻演化系统生物学,闲时喜欢阅读。
制版编辑: 斯嘉丽|
本页刊发内容未经书面许可禁止转载及使用
公众号、报刊等转载请联系授权
copyright@zhishifenzi.com
欢迎转发至朋友圈
▼点击查看相关文章

▼▼▼点击“阅读原文”,发现悦读2018。


