概念体系自动构建
作者:哈工大SCIR 张景润
1.摘要
本文主要介绍开放域概念体系的自动构建。首先介绍概念体系自动构建的任务描述,然后介绍概念体系构建的通用步骤:is-a 关系对抽取、概念体系构建。最后介绍了在这些步骤中的一些常用方法。
2.任务介绍
大部分概念体系的构建可以划分为两个步骤,即基于模式或基于分布式方法的is-a关系对抽取以及利用is-a 关系对构建一个完整的概念体系。
3.常用方法
3.1 is-a 关系对抽取
(1)基于模式的is-a关系对抽取
最早且最具影响力的基于模式的关系对抽取方法始于Hearst(1992)[4]。在论文《Automatic acquisition of hyponyms from large text corpora》中,作者手动设计了一些词法模式(也可以叫做模板、规则或路径)来抽取is-a关系对。一个典型的模式形如"[C] such as [E]",其中[C]和[E]分别是上位词y和下位词x的名词占位符。基于这些手动设计的模式,系统可以自动化地抽取大量的is-a关系对,这个方法也因此被一些系统所采用,如Wu(2012)[5]等基于Hearst模式和大量的网页文本构建了Probase系统,该系统包含有265万的概念以及2076万的is-a关系对。
但是由于这些模式太过具体,无法覆盖所有的语言情形,因此召回率会比较低。而简单的基于模式的方法又容易因为惯用表达、解析错误和歧义而出错。一个健壮的系统可以利用多种不同的技巧来提高基于模式方法的准确率和召回率。提高召回率的方法有:模式泛化、迭代抽取以及上位词推断等,而提高准确率的方法主要有:置信度判断以及分类器判断等。
利用模式泛化来提高召回率。Ritter(2009)[6]等尝试将Hearst模式中的名词性短语[E]替换为一些名词短语的列表;而Luu(2014)[7]等则设计了更灵活的模式,在这些模式中的一些词是可互换的;也有一些论文提出可以尝试自动扩充模板,Snow(2004)[8]等利用两个词语的依赖路径来代表这个模式,这使得两个词语之间的词法和句法联系都可以被建模。Snow的这种方法要比简单的基于词法的模式匹配更能抵抗噪声,从而被许多系统采用。如在PATTY[9]系统中,通过使用单词词性、词类型(如音乐家等)以及通配符来对依赖路径的单词子集进行随机替换,最终再从中挑选模式。
利用迭代抽取来提高召回率。过于泛化的模式往往会因为语言的模糊性以及语义漂移问题而抽取出不正确的is-a关系对[10]。因此,与上述模式泛化方法相比,一个相反的想法是使用非常具体的模式。Kozareva(2008)等[11]采用“双锚定”模式(如“福特和*等汽车”)来获取某个特定上位词的下位词,并通过自举循环来扩展上位词和下位词,可以通过“双锚定”模式消除术语的模糊性。该方法使用每个模式作为查询,并将搜索引擎的结果作为网络语料库。
利用上位词推断来提高召回率。由于基于模式的方法要求is-a关系对必须在一个句子中共现,这就限制了抽取的召回率。Ritter(2009)[12]等提出一个想法,如果y是x的上位词,且x和x'十分相似,则y很有可能是x'的上位词。他们还训练一个HMM来学习一个比基于向量方法更好的相似度度量方法。此外,一些方法还通过考虑下位词的修饰词来生成额外的is-a关系对。例如我们可以很容易地推断出"grizzly bear"是一个"bear",因为其中心词为"bear"。这个思想在中文中也有类似的体现,比如"哈尔滨工业大学"的中心词"大学"就是其上位词。
利用置信度来提高准确率。在抽取到is-a关系对后,可以使用基于统计的方法来计算置信度分数并去除较低分数的关系对。如KonwItAll(2004)[13]系统利用搜索引擎来计算x与y的点互信息值;Probase系统则利用似然概率来抽取x最有可能的上位词y。
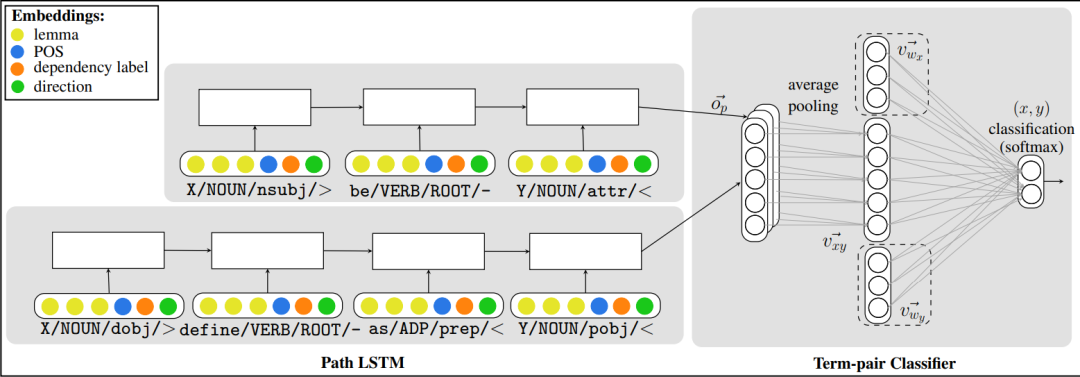
利用分类器来提高准确率。通过训练一个分类器f来判断is-a关系对的正确性,常用的模型选择有SVM、逻辑回归、神经网络模型等,其中f的特征大多可以分为词法、语法、统计信息以及外部资源几类。Shawartz(2016)[14]等指出,可以利用基于模式和基于分布式混合的方法来表示x和y,从而进行分类。作者的实验证明基于混合的方法可以极大提升分类器的性能。
相关模型代码已经开源,链接为https://github.com/vered1986/HypeNET
作者的混合模型结构如下图所示。
(2)基于分布式的is-a关系对抽取
关键词抽取。关键词可以通过词性标注或命名实体识别工具被识别出来,然后可以使用若干规则进行过滤。现有的一些关键词或关键短语的抽取模型可以直接用于识别这些is-a关系对中的关键词。对于一些特定领域的概念体系来说,在经过关键词抽取后,还需要进行领域过滤。这些过滤方法多采用一些统计值并通过设置阈值来进行过滤,如TF、TF-IDF等。
3.2 概念体系归纳构建
(1)增量学习
(2)聚类
(3)基于图的方法
(4)概念体系清洗
4.总结
参考资料
Wen Hua, Zhongyuan Wang, Haixun Wang, Kai Zheng, and Xiaofang Zhou. 2017. Understand short texts by harvesting and analyzing semantic knowledge. IEEE Trans. Knowl. Data Eng. 29(3):499–512.
[2]Yuchen Zhang, Amr Ahmed, Vanja Josifovski, and Alexander J. Smola. 2014. Taxonomy discovery for personalized recommendation. In Proceedings of the Seventh ACM International Conference on Web Search and Data Mining. pages 243–252.
[3]Shuo Yang, Lei Zou, Zhongyuan Wang, Jun Yan, and Ji-Rong Wen. 2017. Efficiently answering technical questions - A knowledge graph approach. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. pages 3111–3118.
[4]Marti A. Hearst. 1992. Automatic acquisition of hyponyms from large text corpora. In Proceedings of the 14th International Conference on Computational Linguistics. pages 539–545.
[5]Wentao Wu, Hongsong Li, Haixun Wang, and Kenny Qili Zhu. 2012. Probase: a probabilistic taxonomy for text understanding. In Proceedings of the ACM SIGMOD International Conference on Management of Data. pages 481–492.
[6]Alan Ritter, Stephen Soderland, and Oren Etzioni. 2009. What is this, anyway: Automatic hypernym discovery. In Learning by Reading and Learning to Read, Proceedings of the 2009 AAAI Spring Symposium. pages 88–93.
[7]Anh Tuan Luu, Jung-jae Kim, and See-Kiong Ng. 2014. Taxonomy construction using syntactic contextual evidence. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. pages 810–819.
[8]Rion Snow, Daniel Jurafsky, and Andrew Y. Ng. 2004. Learning syntactic patterns for automatic hypernym discovery. In Proceedings of the 17th Annual Conference on Neural Information Processing Systems. pages 1297–1304.
[9]Ndapandula Nakashole, Gerhard Weikum, and Fabian M. Suchanek. 2012. PATTY: A taxonomy of relational patterns with semantic types. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Pages 1135–1145.
[10]Andrew Carlson, Justin Betteridge, Richard C. Wang, Estevam R. Hruschka Jr. and Tom M. Mitchell. 2010. Coupled semi-supervised learning for information extraction. In Proceedings of the Third International Conference on Web Search and Web Data Mining. pages 101–110.
[11]Zornitsa Kozareva, Ellen Riloff, and Eduard H. Hovy. 2008. Semantic class learning from the web with hyponym pattern linkage graphs. In Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics. pages 1048–1056.
[12]Alan Ritter, Stephen Soderland, and Oren Etzioni. 2009. What is this, anyway: Automatic hypernym discovery. In Learning by Reading and Learning to Read, Proceedings of the 2009 AAAI Spring Symposium. pages 88–93.
[13]Oren Etzioni, Michael J. Cafarella, Doug Downey, Stanley Kok, Ana-Maria Popescu, Tal Shaked, Stephen Soderland, Daniel S. Weld, and Alexander Yates. 2004. Web-scale information extraction in knowitall: (preliminary results). In Proceedings of the 13th international conference on World Wide Web. pages 100–110.
[14]Dekang Lin. 1998. An information-theoretic definition of similarity. In Proceedings of the Fifteenth International Conference on Machine Learning. Pages 296–304.
[15]Julie Weeds, David J. Weir, and Diana McCarthy. 2004. Characterising measures of lexical distributional similarity. In Proceedings of the 20th International Conference on Computational Linguistics.
[16]Enrico Santus, Alessandro Lenci, Qin Lu, and Sabine Schulte im Walde. 2014. Chasing hypernyms in vector spaces with entropy. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics. pages 38–42.
[17]Stephen Roller, Katrin Erk, and Gemma Boleda. 2014. Inclusive yet selective: Supervised distributional hypernymy detection. In Proceedings of the 25th International Conference on Computational Linguistics. pages 1025–1036.
[18]Ruiji Fu, Jiang Guo, Bing Qin, Wanxiang Che, Haifeng Wang, and Ting Liu. 2014. Learning semantic hierarchies via word embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. pages 1199–1209.
[19]Wei Shen, Jianyong Wang, Ping Luo, and Min Wang. 2012. A graph-based approach for ontology population with named entities. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management. pages 345–354.
[20]Zornitsa Kozareva and Eduard H. Hovy. 2010. A semi-supervised method to learn and construct taxonomies using the web. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. pages 1110–1118.
[21]Daniele Alfarone and Jesse Davis. 2015. Unsupervised learning of an IS-A taxonomy from a limited domain-specific corpus. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence. pages 1434–1441.
[22]Luis Espinosa Anke, Horacio Saggion, Francesco Ronzano, and Roberto Navigli. 2016b. Extasem! extending, taxonomizing and semantifying domain terminologies. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. pages 2594–2600.
[23]Paola Velardi, Stefano Faralli, and Roberto Navigli. 2013. Ontolearn reloaded: A graph-based algorithm for taxonomy induction. Computational Linguistics 39(3):665–707.
[24]Jiaqing Liang, Yanghua Xiao, Yi Zhang, Seung-won Hwang, and Haixun Wang. 2017a. Graph-based wrong isa relation detection in a large-scale lexical taxonomy. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. pages 1178–1184.
[25]Chengyu Wang, Xiaofeng He, and Aoying Zhou. 2017. A Short Survey on Taxonomy Learning from Text Corpora: Issues, Resources and Recent Advances.In EMNLP.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“AM20” 可以获取《LinkedIN最新《注意力模型》综述论文大全,20页pdf》专知下载链接索引





