首次公开!深度学习在知识图谱构建中的应用
阿里妹导读:在智能化时代的今天,搜索引擎不仅能理解用户检索的信息、并总结出与搜索话题相关的内容,更在逐步构建一个与搜索结果相关的完整知识体系,让用户获得意想不到的发现。神马搜索的知识图谱与应用团队就在这条路上不断探索中。
昨天,我们介绍了基于DeepDive的关系抽取方法及其在知识图谱数据构建中应用(传送门:知识图谱数据构建的“硬骨头”,阿里工程师如何拿下?)。这个方法准确率高、交互好,在单一关系的抽取任务中体现了强大的能力。今天,我们将为大家继续分享,基于深度学习的关系抽取技术及其在神马知识图谱数据构建中的探索和实践,以及业务落地过程中遇到的一些挑战,期待与大家一起交流探讨。
深度学习模型介绍
DeepDive系统在数据处理阶段很大程度上依赖于NLP工具,如果NLP的过程中存在错误,这些错误将会在后续的标注和学习步骤中被不断传播放大,影响最终的关系抽取效果。为了避免这种传播和影响,近年来深度学习技术开始越来越多地在关系抽取任务中得到重视和应用。本章主要介绍一种远程监督标注与基于卷积神经网络的模型相结合的关系抽取方法以及该方法的一些改进技术。
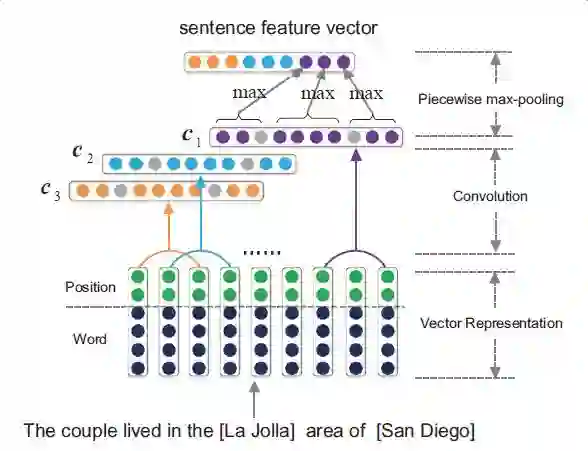
Piecewise Convolutional Neural Networks(PCNNs)模型
PCNNs模型由Zeng et al.于2015提出,主要针对两个问题提出解决方案:
针对远程监督的wrong label problem,该模型提出采用多示例学习的方式从训练集中抽取取置信度高的训练样例训练模型。
针对传统统计模型特征抽取过程中出现的错误和后续的错误传播问题,该模型提出用 piecewise 的卷积神经网络自动学习特征,从而避免了复杂的NLP过程。
下图是PCNNs的模型示意图:
转自:阿里技术
完整内容请点击“阅读原文
登录查看更多
相关内容
Arxiv
15+阅读 · 2020年3月26日
Arxiv
11+阅读 · 2019年6月13日





相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2020年3月26日
Arxiv
11+阅读 · 2019年6月13日