大数据主流平台框架
一次性付费进群,长期免费索取教程,没有付费教程。
教程列表见微信公众号底部菜单
进微信群回复公众号:微信群;QQ群:460500587

微信公众号:计算机与网络安全
ID:Computer-network
虽然大数据的出现大幅提升了人们对数据的认知,但事实上人类在数据收集、整理和分析上已经有着悠久的历史。从人工统计分析到计算机,再到今天的分布式计算平台,数据处理速度飞速提高的背后是整体架构的不断演进。当今,大数据计算平台最流行的莫过于Hadoop、Spark和Storm这三种,虽然Hadoop是主流,然而Spark和Storm这两个后起之秀也正以迅猛之势快速发展。让我们一起看看这三个平台及其相互间的关系。
1、Hadoop
Hadoop是Apache软件基金会下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop采用Java语言开发,具有良好的跨平台性,并且可部署在廉价的计算机集群中,在业内应用非常广泛,是大数据的代名词,也是分布式计算架构的鼻祖。几乎所有主流厂商都围绕Hadoop进行开发和提供服务,如谷歌、百度、思科、华为、阿里巴巴、微软都支持Hadoop。它将一个大型的任务切割成多个部分给多台计算机,让每台计算机处理其中的一部分。这种运行在分布式计算存储的架构所带来的好处不言而喻。
● 在硬盘存储层面,Hadoop的数据处理工作借助HDFS,将架构下每一台计算机中的硬盘资源汇聚起来,无论是存储计算还是调用,都可以视为一块硬盘使用,就像计算机中的C盘、D盘。
● 在资源管理层面,Hadoop使用集群管理和调度软件YARN,相当于计算机的Windows操作系统,进行资源的调度管理。
● 在计算处理层面,Hadoop利用MapReduce计算框架进行计算编程,将复杂的、运行在大规模集群上的并行计算过程高度抽象成两个函数——Map和Reduce。
经过多年的发展,Hadoop生态系统不断完善和成熟,除了核心的HDFS、YARN和MapReduce之外,还包括ZooKeeper、HBase、Hive、Pig、Mathout、Flume、Sqoop、Ambari等功能组件。如图1所示。
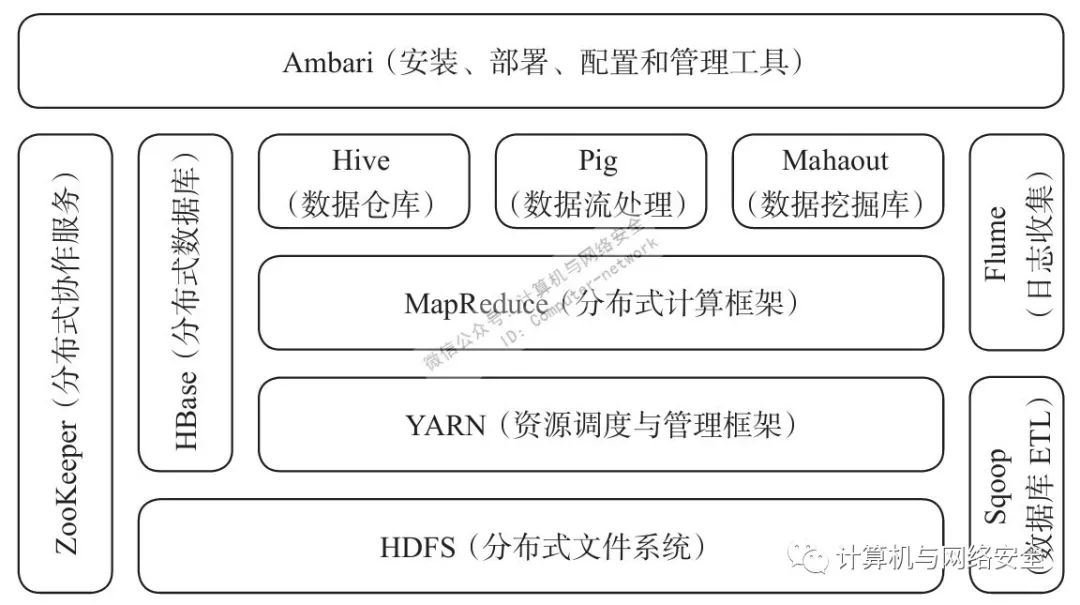
图1 Hadoop生态系统
作为一种对大量数据进行分布式处理的软件框架,Hadoop具有以下几方面特点:
● 高可靠性。采用冗余数据存储方式,即使某副本发生故障,其他的仍能正常提供服务。
● 高效性。采用分布式存储和分布式处理两大核心技术,能高效处理PB级数据。
● 成本低。采用廉价计算机集群,成本低,普通用户很容易搭建。
● 可扩展性。可高效稳定运行在廉价的计算机集群上,扩展到数以千计的计算机节点上。
● 支持多种编程语言。虽然是Java开发的,但也可使用其他语言编写,比如C和C++。
这种架构大幅提升了计算存储性能,降低计算平台的硬件投入成本。然而,任何事物都不是完美的。Hadoop的缺点在于,由于计算过程放在硬盘上,受制于硬件条件限制,数据的吞吐和处理速度明显不如使用内存快,尤其是在使用Hadoop进行迭代计算时,非常耗资源,且在开发过程中需要编写不少相对底层的代码,不够高效。
2、Spark
为了解决处理速度和实时性问题,出现了Spark和Storm平台框架。我们先来看一下Spark。Spark也是Apache软件基金会下的开源项目,用Scala语言编写的,用于对大规模数据的快速处理,它与Hadoop相比最大的优点就是“快”,当初设计目标也是如此。为了使程序运行更快,Spark提供了内存计算,减少了迭代计算时的I/O开销。Spark不但具备Hadoop MapReduce的优点,而且解决了其存在的缺陷,逐渐成为当今大数据领域最热门的大数据计算平台。
作为大数据框架的后起之秀,Spark具有更加高效和快速的计算能力,其特点主要有:
● 速度快。采用先进的有向无环图执行引擎,以支持循环数据流与内存计算,基于内存的执行速度比Hadoop MapReduce快上百倍,基于磁盘的执行速度也较之快十倍。
● 通用性。提供体系化的技术栈,包括SQL查询、流式计算、机器学习和图算法等组件,这些组件可无缝整合在同一应用中,足以应对复杂计算。
● 易用性。支持Scala、Java、Python和R等编程语言,API设计简洁,用户上手快,且支持交互式编程。
● 运行模式多样。Spark可运行在独立的集群模式中,或运行在Hadoop中,也可运行在Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
我们知道大数据计算模式主要有四种,除了图计算这种特殊类型,其他三种足以应付大部分应用场景,因为实际应用中大数据处理主要就是这三种:复杂的批量数据处理、基于历史数据的交互式查询和基于实时数据流的数据处理。Hadoop MapReduce主要用于批处理计算,Hive和Impala用于交互式查询,Storm主要用于流式数据处理。以上都只能针对某一种应用,但如果同时存在三种应用需求,Spark就比较合适了。因为Spark的设计理念就是“一个软件栈满足不同应用场景”,它有一套完整的生态系统,既能提供内存计算框架,也可支持多种类型计算(能同时支持批处理、流式计算和交互式查询),提供一站式大数据解决方案。此外,Spark还能很好地与Hadoop生态系统兼容,Hadoop应用程序可以非常容易地迁移到Spark平台上。
除了数据存储需借助Hadoop的HDFS或Amazon S3之外,其主要功能组件包括Spark Core(基本通用功能,可进行复杂的批处理计算)、Spark SQL(支持基于历史数据的交互式查询计算)、Spark Streaming(支持实时流式计算)、MLlib(提供常用机器学习算法,支持基于历史数据的数据挖掘)和GraphX(支持图计算)等,如图2所示。

图2 Spark生态系统
尽管Spark有很多优点,但它并不能完全替代Hadoop,而是主要替代MapReduce计算模型。在实际应用中,Spark常与Hadoop结合使用,它可以借助YARN来实现资源调度管理,借助HDFS实现分布式存储。此外,比起Hadoop可以用大量廉价计算机集群进行分布式存储计算(成本低),Spark对硬件要求较高,成本也相对高一些。
3、Storm
另一个著名的开源大数据计算框架Storm主要用于实时的流式数据处理,它与Spark最大的区别在于“实时性”的差异:Spark是“准实时”的,它先收集一段时间的数据再进行统一处理,好比看网页统计票数,每隔一段时间刷新一次;而Storm则是“完全实时”的,来一条数据就立刻处理一条,源源不断地流入。但Storm的缺点在于,无论是离线批处理、高延迟批处理,还是交互式查询,它都不如Spark框架。不同的机制决定了二者所适用的场景不同,比如炒股,股价的变化不是按秒计算的,因此适合采用计算延迟度为秒级的Spark框架;而在高频交易中,高频获利与否往往就在1ms之间,就比较适合采用实时计算延迟度的Storm框架。
虽然Storm是Twitter开发的一个开源分布式实时计算系统,但是它已成为Apache的孵化项目,发展势头也很迅猛。Storm对于实时计算的意义类似于Hadoop对于批处理的意义,可以简单、高效、可靠地处理流式数据并支持多种编程语言,它能与多种数据库系统进行整合,从而开发出更强大的实时计算系统。
作为一个实时处理流式数据的计算框架,Storm的特点如下:
● 整合性。Storm可方便地与消息队列系统(如Kafka)和数据库系统进行整合。
● 可扩展性。Storm的并行特性使其可以运行在分布式集群中。
● 简易的API。Storm的API在使用上既简单又方便。
● 可靠的消息处理。Storm保证每个消息都能完整处理。
● 容错性。Storm可以自动进行故障节点的重启,以及节点故障时任务的重新分配。
● 支持多种编程语言。Storm支持使用各种编程语言来定义任务。
就像目前云计算市场中风头最劲的混合云一样,越来越多的组织和个人采用混合式大数据平台架构,因为每种架构都有其自身的优缺点。比如Hadoop,其数据处理速度和难易度都远不如Spark和Storm,但是由于硬盘断电后其数据可以长期保存,因此在处理需要长期存储的数据时还需要借助于它。不过由于Hadoop具有非常好的兼容性,因此也非常容易同Spark和Storm相结合使用,从而满足不同组织和个人的差异化需求。考虑到网络安全态势所应用的场景,即大部分是复杂批量数据处理(日志事件)和基于历史数据的交互式查询以及数据挖掘,对准实时流式数据处理也会有一部分需求(如会话流的检测分析),建议其大数据平台采用Hadoop和Spark相结合的建设模式。
微信公众号:计算机与网络安全
ID:Computer-network
【推荐书籍】