全球最大GPU“猛兽出笼”!挖矿显卡缺席黄仁勋的“星战”GTC ,英伟达重新定义图形与计算丨现场

长按识别二维码,收看2018《麻省理工科技评论》区块链商业峰会
从 PC 游戏绘图起家,然而在计算发光发热的 NVIDIA,在本次 GTC 2018 中,虽然提出了光线追踪技术的普及化愿景,但主角依然是在计算领域。

图丨黄仁勋登场(图片来源:DT君)
虽然 NVIDIA 一直以来都被认为是绘图架构公司,但由于 GPU 计算概念的兴起,NVIDIA 转身一变成为计算架构设计公司,更成为带动 AI 产业发展的重要推手。通过使用 GPU 的高度并行计算方式,大幅缩短 AI 应用所需要的模型训练时间,改善过去纯 CPU 架构服务器面临大量数据的并行计算的性能瓶颈,让训练的设备可以快速商业化、平民化,AI 产业也借此得以蓬勃发展。
虽然现在有不少号称可以取代 GPU 的 AI 芯片推出,但事实上,要把 NVIDIA 在过去 10 年累积起来的坚实 CUDA 生态打败,可说是难如登天,接近不可能完成的任务。

除了计算和自动驾驶领域,NVIDIA 原本自豪的绘图技术在过去两年却没有提出什么新架构,要知道早年 NVIDIA 可是曾经半年推一个新架构,把竞争对手打到非死即残。2017 年发表的 Volta 是针对计算优化,除了额外增加的 Tensor Core 外,架构及绘图性能表现与 Pascal 并无二致。甚至可以说,在 PC 绘图技术方面,过去两年基本上都还是以 Pascal 技术为核心。
所以 NVIDIA 在绘图技术方面已经遇到瓶颈了?那也未必,其实 NVIDIA 也在想如何憋出大招,比如说前阵子 NVIDIA 宣布实作 RTX 实时光线追踪 (Raytracing) 技术,不仅支持微软在今年 GDC(Game Developers Conference) 上宣布的 DirectX Raytracing(DXR) API,也预计要推出支持 RTX 的 Quadro 专业绘图卡。考虑到光线追踪所需要的计算量极为庞大,因此相关架构必须要在 Volta 以及下一代 GPU 上才能以硬件的方式来实现,而这正是利用 Tensor Core 所带来的庞大算力来达成光线追踪的计算。
虽然本次 GTC 大会并没有宣布新款绘图架构,但根据 DT 君得到的信息,NVIDIA 下一款消费性芯片将是图灵 (Turing) 架构,而类似 Pascal 和 Volta 之间的关联,安培 (Ampere) 将会以是图灵为基础的专业计算卡。而不论在消费卡或者是计算卡,Tensor Core 的持续引入使用也应会是不变的方向。
在 GTC 开场演讲中,黄仁勋正式发布英伟达新一代显卡 NVIDIA Quadro GV100。Quadro GV100 具有 32GB 内存,且可借助 NVIDIA NVLink 互联技术,通过并联两块 Quadro GPU 扩展至 64GB。

图丨黄仁勋正式发布英伟达新一代显卡 NVIDIA Quadro GV100
黄仁勋演讲内容:
重现照相质量的3D世界一直以来是3D图学的终极目标,真实世界中光线来自四面八方,为了要重现真实世界,就必须把各个光线的来源综合计算,复杂度极高,传统GPU可能一秒只能计算一格画面,但我们今天利用新技术,可以达到每秒60张画面,这是非常不可思议的突破。
我们过去利用了许多不同的图学技巧,不论是要降低计算负担,或者是加速执行,但仍然很难真实重现照片画质。
图丨黄仁勋演讲现场(图片来源:DT君)
但决定画面真实与否的最终条件,往往是画面中的小细节,比如说光线和物件之间的折射、散射、漫射、透射与反射等等,通过光线追踪技术,我们可以把真实世界的画面成像原理搬到3D图学当中,并且利用我们的GPU技术架构来完成。
要考虑到不同的物件会吸收光线、折射光线的程度不同,比如说玻璃、塑胶,甚至我们的皮肤,都会一定程度的吸收光线,因此我们利用了subsurface scattering来达到这样的效果,这在一般计算机图学中是非常难以达到的效果,但通过光线追踪技术,我们可以轻易的达到。
黄仁勋用一段星际大战影片来展示光线追踪的效果,其效果几乎和真实的电影画面毫无差异,用肉眼几乎看不出来是计算机计算的影片。尤其是在帝国士兵身上的铠甲效果,反射光源后,和周围环境进行多次折射和反射,以及光线的吸收,最终形成非常真实的画面,几乎和电影画面没有差别。
图丨黄仁勋用星际大战影片来展示光线追踪的效果(来源:DT君)
这样的画面是在DGX超级计算平台,通过2块Volta绘图卡达成。这是世界首次以实时呈现光线追踪的效果。
在电影产业中,其实相关与光线处理相关的图学技术都被使用,当你看到广告、影片中,很多凭空创造出来的产物,基本上都是利用GPU创造出来的,而GPU每年都创造了超过10亿张这些数字创作。通过GPU计算,我们让产生这些图像的成本和需要的时间降到最低,我们可以说,用越多GPU,你越省钱!
图丨The more GPU you buy,the more you save
如今,通过使用 Quadro GV100,我们可以在单一机架中取代传统庞大耗电的render farm,目前主要电影创作者都逐渐往这个方向前进,比如说 Pixar,就利用了这样的架构来产生他们的电影画面。
而考虑到世界上有多少电影工作室正在从事电影相关创作,我们可以考虑一下这个市场规模会有多大,牵涉到多大的金额,天文数字。
GPU推动了AI产业的发展,但AI产业也同时推动了GPU的进步,不只是GPU架构本身,还有相对应的开发环境与软件生态,考虑到目前AI生态越来越蓬勃发展,我们可以说现时是个最佳的时间点,是让产业改头换面,前进到AI的领域中。
图丨各种各样的AI Network正在涌现
而为了满足这些开发者的需求,超过800万个开发者下载了我们的CUDA工具,他们创造出来的计算效能超过370PETAFLOPS。
这些高性能计算很大程度都是要用来改变世界,包括研究疾病、医疗、气候变迁,甚至了解HIV的结构。
我们拿2013年的GPU架构和今年推出的最新产品相比,我们的GPU每隔五年就达到10倍的效能成长,传统半导体有摩尔定律,但是在CUDA GPU中,我们创造了不同的定律,不只是硬件本身,我们也针对算法不断的改善,总和以上的努力,我们才能达到这样的成就。
传统服务器的庞大、耗电,通过我们的GPU有了根本性的改变,我们可以说,你们在计算领域用了越多的GPU,其实就是越省钱!
在医疗图像方面,很多疾病是越早侦测就越有机会治愈,但如何侦测疾病,视觉化的身体扫描技术,包括超音波、断层扫描等,如果能够利用3D技术重建扫描结果,我们可以看到更真实的结果,而不是能依靠不明显的阴影来判断病征。
图丨英伟达在医疗上的合作伙伴
通过远端与医疗图像设备连线,这些设备产生的图形实时反馈到我们的CUDA服务器中,并实时产生这些清晰的动态图像,通过深度学习,我们可以轻易判读这些扫描的结果,并还原到我们肉眼可以简单判读的3D立体型态。通过把这些服务器虚拟化,利用AI来后处理这些医学图像,我们可以创造出更容易判读,且更不容易误判的医疗图像。
深度学习可以说重新塑造了我们现在的AI应用,从过去厚重、庞大、笨拙的印象,变呈现在轻巧、快速、聪明的结果。从芯片设计者,到互联架构,到软件设计者,再到OEM厂商等,不论你在供应链中的哪个环节,我们都可以全力支持。
客户想要达成不同的计算目标,不论是购买成品,或者是自行架设,我们都能满足客户的需求。
近十年从机器学习到深度学习,从最早的模型,衍生出无数种不同的神经网络、模型,随着应用的增加,也越来越复杂。
当然,为了要应付这些复杂的神经网络计算,现有的小型GPU其实很难以负担,但我们从不同的方向去思考,如果把个别的GPU通过高效能的互联结构结合起来,形成一个巨大的GPU,这个GPU上面可以创造出过去不可能达成的计算成果。
图丨用NVSwitch互聯16個GPU的DXG2 server
我们通过NVSwitch达成了这个目的,通过这个互联架构,我们在DXG-2 server中互联了16颗GPU,形成一个庞大的GPU架构,通过最新的NVLink,技术,GPU和GPU之间可以用比PCIE快20倍的效率互相沟通。这个互联结构不是网络状结构,而是速度更快的交换器结构,通过这样的互联设计,我们在单一结构中实现了2PETAFLOP的惊人效能。而且只需要2000W的功耗。其功耗性能比可说远远超出目前的超级计算机。
图丨黄仁勋和世界上最大的GPU合影
现在新的AI芯片把云计算、深度学习看得太简单,要考虑的因素太多,包括延迟、学习速率以及准确度等等,并不是在机架中塞进几个ASIC芯片就能够轻易解决的工作。我们要把尽可能快速的产生模型,尽可能让模型更小,尽可能确保正确的结果输出,背后的最大功臣就是开发工具。继去年针对推理大幅进化的TensorRT3之后,我们现在推出了最新的TensorRT 4,支持更多主流框架,也更能把不同的神经网络部署到云服务器当中。这个版本我们又更加强化了推理性能。
通过TensorRT、NCCL和cuDNN,以及面向机器人的全新Isaac软件开发套件,基于GPU的计算生态也更加完整。此外,通过与领先云服务提供商的密切合作,各大主流深度学习框架都在持续优化,以充分利用NVIDIA的GPU计算平台。
NVIDIA新推出的DGX-2系统通过借鉴NVIDIA为所有层级的计算堆栈开发的各种业界领先的技术优势,实现了每秒2千万亿次浮点运算的里程碑式突破。
图丨黄仁勋演讲
DGX-2是首款采用NVSwitch的系统,其中采用的16个GPU均共享统一的内存空间。这让开发者获得了相应的深度学习训练能力,以处理最大规模的数据集和最复杂的深度学习模型。








DGX-2能够在不到两天的时间内完成对FAIRSeq的训练,FAIRSeq是一种采用最新技术的神经网络机器翻译模型,其性能相较于去年9月份推出的基于Volta架构的DGX-1提高了10倍。
我们在此也要宣布推出DRIVE Constellation计算平台。该平台基于两个不同的服务器,第一台服务器运行DRIVE Sim软件来模拟自动驾驶汽车的传感器,例如摄像头、LiDAR和雷达,第二台则包括英伟达强大的Drive Pegasus自驾车AI计算机,运行完整的自驾车软件堆栈和处理过程,就像驾驶汽车的传感器一样。
通过虚拟仿真,人们可以通过测试数十亿英里的自定义场景和罕见的场景案例来增强算法的稳健性,最终所花的时间和成本只是在真实物理道路上需要的一小部分。

AI 生态突飞猛进,GPU 是背后最大推手
2017 年可说是各类型 AI 产业从概念、技术到应用落地的关键年,2018 年我们能看到不只是既有的产业纷纷引入 AI 的概念,新的产业也都纷纷因应而生。
然而 AI 所需要的庞大数据处理以及模型建立过程需要极为强大的计算能量才有办法应付,而业界直到数年前都还只能依靠纯粹的 CPU 架构所建立的数据中心以及超算平台来进行 AI 模型的训练,不仅成本昂贵,训练过程也旷日废时,成本效益太低,若没有过去几年 NVIDIA 在 GPGPU 技术与 CUDA 环境生态的耕耘,我们就看不到现在 AI 产业的蓬勃发展。
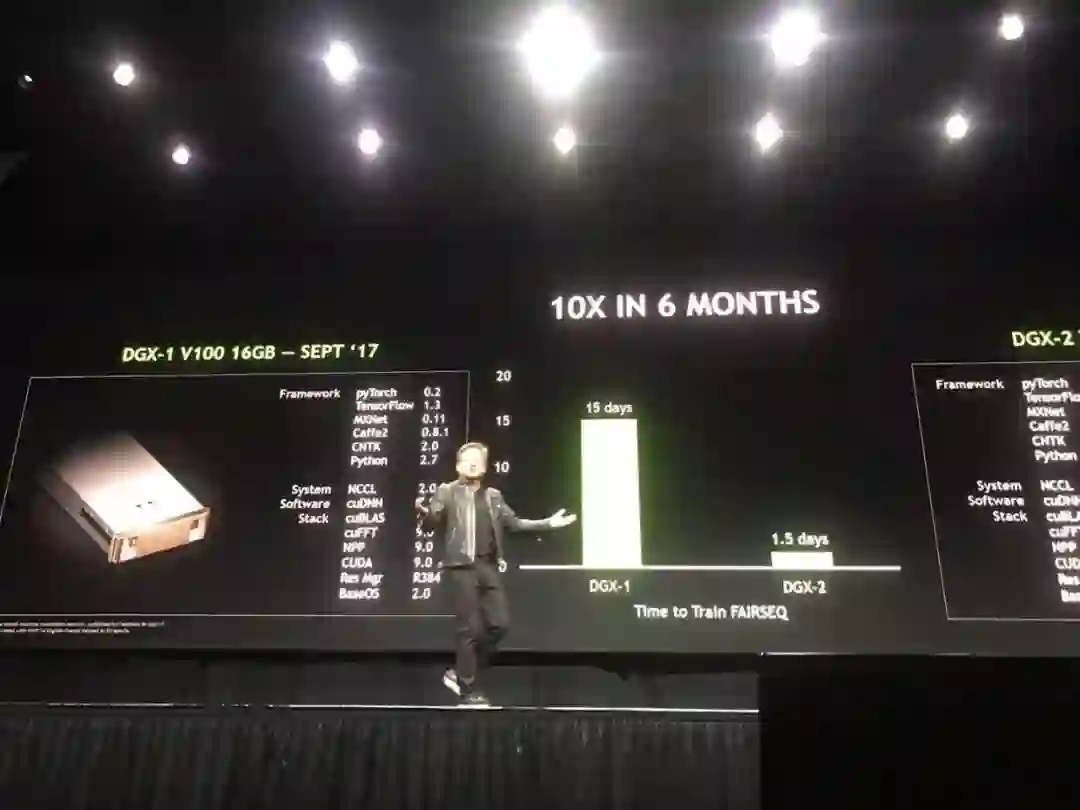
图丨DGX-2在训练FAIRSEQ方面的性能,要比去年推出的DGX-2快了10倍
而不论未来是否会有新的架构取代 GPU 成为 AI 计算的核心,我们都不能忘记 GPU 在这波 AI 崛起的潮流中所扮演的关键性角色。
当然,面对各家架构的挑战,NVIDIA 自然也是准备好压箱宝应对,比如说原本 GPU 的大量并行计算结构对训练有极大的优势,但是推理计算性能表现极差,后来通过 Tensor Core 的集成得以有效的解决;而配合 Tensor Core 推出的 Volta 架构,主要改善的部分在于 CPU、GPU 与 GPU 之间的互联能力以及带宽,借此输出更高的计算能力,甚至可和专注于机器学习的 Google TPU 架构相提并论。
NVIDIA 虽无全新架构,但通过细节的强化仍将稳居 AI 霸权地位
本次 GTC 2018 大会中,其实 NVIDIA 要传达的概念是:虽然 AI 产业中新架构不少,但我们要坚持做好自己分内的工作,并一次次的突破,对我们而言,最大的挑战是自我突破,而不是外来的市场阻碍。
也因此,虽然严格上来说并没有真正意义上的新架构推出,基本上都是既有架构的强化,或者是开发生态的完备,但通过这样的改进,其带给市场的应用感受以及性能突破,都是 NVIDIA 都是要向市场传达的信号:对手还有太多不到位的地方,难以挑战我们在市场上的霸权。

图丨英伟达的AI平台
黄仁勋在也再次强调:“深度学习的迅猛进步暗示着未来还将发生什么,许多这些进步都依赖于 NVIDIA 的深度学习平台,它将很快成为世界的标准。我们正以超越摩尔定律的惊人速度大幅提高我们平台的性能,由此带来的重大突破将改变医疗、交通、科研以及其他无数领域”。NVIDIA 不只要主导计算领域市场,甚至要带领半导体产业持续前进。
Tensor Core 与平台生态进一步优化,在不改变大架构的前提之下性能巨幅成长
除了 DGX-2,NVIDIA 也同样在 GTC 2018 中,更加强调 Tensor Core 带来的高效能推理能力,通过新版 TensorRT 开发环境整合了 TensorFlow 框架,并且扩增了可转移深度学习模型框架 ONNX 的支持,借此建构超大规模的数据中心。而通过革命性的 NVswitch 互联技术,DGX-2 可以在不到两天的时间内训练出最先进的神经机器翻译模型 FAIRSeg,其性能比使用 Volta 的 DGX-1 提高 10 倍。
开发者可在基于 NVIDIA 的 GPU 深度学习加速设计,支持包含 Caffe 2、Chainer、CNTK、MXNet 以及 Pytorch 等先进的深度学习框架。虽然终端和边缘计算等着重于推理的本地 AI 计算越来越普及,但是云端低延迟的推理需求仍然持续成长,配备 Tensor Core 的 NVIDIA GPU 加速设计不仅可以满足这方面的应用,一方面也是为了避免如 FPGA 以及其他基于 NPU 或 TPU 等强调推理性能表现的云端加速设计有可乘之机,威胁其市场地位。
图丨通过kubernetes,可以快速的扩展GPU云服务器的规模,性能可以依比例增加,中间的损耗极小
NVswitch 这个最新的互联技术是 NVIDIA 这些新产品效能得以提升的关键,此技术的频宽比最好的 PCLeswitch 要高了不少,研究人员能够建立更多的 GPU 彼此相互连接的系统,帮助突破此前的系统限制,运行更大量的数据,同样为处理复杂的数据打开了大门,包括神经网络并行训练的建模。
NVswitch 延伸了 NVlink(NVIDIA 的一种高性能 GPU 互联技术)取得的创新,NVswitch 让开发者们能够建立更先进的系统,用以基于 NVlink 的 GPU 更灵活的进行拓扑连接。通过 NVswitch,系统中的 16 个 GPU 将使用统一的存储空间,开发者可以用深度学习的力量去处理最大的数据集以及建立最复杂的深度学习模型。
当然,有了良好的硬件环境,软件生态也必须兼顾,NVIDIA 大方的把深度学习和 HPC 软件堆栈更新免费提供给其开发者社区。该社区目前共有超过 820,000 名注册用户,而一年前约为 48 万。其更新包括新版本 CUDA, tensorRT,Nccl 和 cuDNN,以及用于机器人的 Issac 软件开发套件。此外,通过与领先的云服务提供者的紧密合作,每个主要的深度学习框架都在不断优化,以充分利用 NVIDIA 的 GPU 计算平台。
Volta 架构绘图能力和 Pascal 没有差别,但 Tensor Core 可能成为图形计算主角
从 2017 年推出至今,Volta 架构已经成为 NVIDIA 计算平台中的核心,然而该架构基本上只是针对算力输出优化的 Pascal,目的是要应对来自机器学习领域中各家新架构的挑战。在绘图能力方面,依照实测数据显示,Volta 的 CUDA 单元在绘图性能方面与 Pascal 几乎一模一样,而且就算是 12nm 工艺,也无法压制 5120 个 CUDA 计算单元的热情。
Volta 与 Pascal 除带宽与互联技术的优化外,最大的差别在于 Tensor Core 的有无。前面也提到,NVIDIA 支持了微软最新提出的光线追踪技术,该技术本身需要大量的矩阵数学计算,而 Tensor Core 本身是一种矩阵乘累加的计算单元,刚好光线追踪算法本身即需要庞大的矩阵计算量。当然,NVIDIA 还未公布其光线追踪的实作方式,但是在年初 EmTech 中专访 Bill Dally 时,就曾透露未来 Tensor Core 将会使用到游戏环境中。

图丨“Yes, this is one GPU”
而支持微软的光线追踪技术标准便可能是 Tensor Core 进入绘图领域的首个技术应用,且不只是游戏绘图,专业绘图也当然同样兼顾。
目前的 GPU 绘图技术基本上都是基于光栅化 (Rasterization) 计算方式,也就是把 3D 虚拟空间里面的所有物件剔除所有视角不可见的部分 (包含被前方物体遮住的后方物体),这种删除不可见部分的技术称为 Z-buffer Culling,通过此技术,可以将立体的虚拟世界压缩到平面上,也就是我们肉眼所看到的游戏画面,然后再依照这个平面来进行打光、贴图、渲染等成像步骤。
光栅化技术好处是非常节省计算能量以及存储空间,但缺点是成像的画面因为缺乏物体与光线的实时互动以及光影和 3D 材质的交互影响作用,看起来比较不真实。但以光线追踪的方式来形成 3D 图像,不仅在光线的过渡将更为自然,未来图形的材质呈现能力也会更逼近真实世界。
虽然与游戏相关的光线追踪技术仅止于前阵子在 GDC 上宣布要支持微软在今年 GDC(Game Developers Conference) 上所宣布的 DirectX Raytracing(DXR) API,但 NVIDIA 自己的 DXR 技术则是会搬到专业绘图上,也就是 Quadro 平台中,其在 GTC 2018 上推出的 Quadro GV100 上,结合 GPU 本身就具备的 AI 与物理现象模拟能力,帮助专业 3D 制图企业与游戏开发商,用更快速的方法来打造更真实的虚拟世界。
NVIDIA 在 GTC 上推出的全新世代 Quadro GV100 支持了以下特性:
支持多样化的 API 实作—
开发者可以通过 NVIDIA OptiX 软件来轻松使用 RTX 光线追踪技术,同时也支持微软的 DXR API,未来 Vulkan 以及其他开放 API 也会陆续支持,让存取 NVIDIA GPU 的硬件计算能力更多样化。
真实光线、反射、折射等视觉表现,以及物理特性支持—
GV100 以及 NVIDIA RTX 光线追踪技术可以用非常直觉的方式来达到电影等级的光影特效呈现能力。
AI 辅助的图像渲染能力—
OptiX 软件可以利用 AI 功能,帮助开发者快速实现图像去噪功能,同时可利用各种交互接口协助开发者流畅的进行设计。
高度弹性的可调整规模性能输出表现—
制图所需要的双精度计算能力,可搭配 NVLink 技术将显存扩展到 64GB 以上,可更好的进行大型复杂模型以及图像的渲染成形。
可和 VR 接口进行高度合作、互动的设计与创意流程—
Quadro GV100 支持在 VR 环境内实时预览先前创造出来的模型或虚拟世界,并且可实时进行互动与调整,而虚拟世界中的物体也都能符合相对应的物理原则。
长久耕耘游戏与 AI 生态的 NVIDIA 自然也了解生态支持的重要,因此推动像 DXR 光线追踪这样的新技术,自然也需要和业界共同耕耘、发展。
目前此技术已经得到主要的游戏开发商、图像设计软件商的大力支持,预计在不久的将来就可看到非常广泛的支持应用出现。
AMD 及微软 DirectX 12 的失败拖累产业发展,但 2018 年游戏绘图技术将有机会迎来革新
NVIDIA 以 GPU 计算的概念为 AI 产业开了一扇门,而 AI 产业的蓬勃发展也为 NVIDIA 的事业带来丰厚的回报。然而 AI 议题让」计算」在过去两年压下了」绘图」,也因此,虽然其 GPU 产品不论是在数据中心、汽车产品,甚或是挖矿应用,可说占据所有人的目光,但是在绘图技术方面,这两年却几乎没有太大成长。

图丨同样训练Alexnet,五年前同样的数据量需要6天,现在的架构只需要18分钟,快了500倍
以 NVIDIA 为例,Pacal 架构发表至今已近两年,但仍居市场主流不退,不论在游戏绘图,或者是专业制图方面,都还是主力产品,这对过去曾经半年推出一款全心架构的 NVIDIA 而言,几乎可以说是一种极为怠惰的行为了。
不过这也不全是 NVIDIA 的问题,微软早在 2015 年发表其最新一代的绘图 API 库 DirectX 12,引入了高度平行化的绘图计算能力,可大幅降低绘制命令开销(draw call overhead),强化渲染效率,且其计算弹性也更高。但由于仅有 Windows 10 操作系统支持 DirectX 12,旧有的 Windows 7 无法升级支持,且 DirectX 12 游戏开发需要更高深的编程技巧,而想要挑战技术极限的游戏开发者却仅九牛一毛,也因此,时至今日,真正采用 DirectX 12 开发的原生游戏仍屈指可数。
DirectX 12 的高弹性是以更高的开发成本为代价,要想充分利用 DirectX 12,开发者们需要对自己现有的引擎进行大幅重建和优化,但换回的成果却是相当有限。举例来说:DirectX 12 本身就拥有强大的多 GPU 支援能力,理论上可允许游戏利用 NVIDIA+AMD 的双显卡配置组合,虽然看起来很炫,但实际上不会有人这样用。
以 DirectX 11 的 SLI 或者 Crossfire 双显示卡配置文件为例,都是由 NVIDIA 和 AMD 提供的,但 DirectX 12 需要开发者自己完成全部开发工作。然而最后又有多少玩家能真正受益呢? 所以现在大多数开发者放弃 DirectX 12 可以说是毫无意外。

图丨英伟达为GPU云创造了一个框架库,包含了市场上所有主流的计算框架,并且已经被应用到不同的云服务厂商当中
NIXXES 公司 CEO Jurjen Katsman 曾说过,DirectX 12 将为 4K 超高画质的顶配硬件玩家带来终极体验,DirectX 12 能够解决 CPU 的瓶颈限制,同时带来 GPU 的 10% 效能提升。然而现在看来,DirectX 12 由于开发环节的门槛极高,让它带来的优势显得没有说服力。
而因为 API 开发难度高,游戏厂商不愿意冒险支持,绘图芯片厂也就少了改革架构来配合 API 发展的动力,NVIDIA 也乐得分心发展 GPU 在计算方面的潜力,无心插柳柳成荫,不仅开创了 AI 计算霸业,也把 NVIDIA 的营收与股价推往另一波高峰。
另外,传统绘图技术竞争对手中,不止 AMD 积弱不振,英特尔的内显亦是毫无进步,因此推动 NVIDIA 改朝换代的压力极小,不过 2018 年,AMD 即将推出的新一代 GPU 架构可望有较大的进展,而英特尔与 AMD 的合作又恐会侵蚀 NB 产品的独显市场,因此 NVIDIA 今年将把事业发展重心从计算稍微往绘图偏移,即便幅度可能不会很大,但也足以带给业界惊喜了。更重要的是,AMD 今年积极重返 PC 游戏绘图市场,若 NVIDIA 没有事先预防,那么 AMD 可能会重演 2017 年 Zen 架构处理器的成功气势,一举夺回市占。
深度学习与游戏开发的碰撞
NVIDIA 首席科学家暨研究部门资深副总裁 Bill Dally 曾在专访中对 DT 君表示:深度学习和图形学之间有很大的协同作用,我们的发现是,通过深度学习,我们可以使图形更好。然后进行视频研究,开发图像抗锯齿和去噪的新算法,并提供图像的时间稳定性,这些都是基于深度学习。因此,通过拥有深厚的学习推理能力,芯片现在实际上在图形表现方面会比没有 TensorCore 更好。
但其实不仅在计算机图学方面可以好好的利用深度学习来进行更有效率的渲染工作,即便是游戏关卡本身的设计,甚至 NPC(Non-Player Character) 角色的行动定义,都可以通过深度学习或者是 AI 的自动管理来达成。想象一下,如果游戏中的 NPC、动物、生态、产业等,配备了支持各种应用模型的 AI 思考模块,那么我们在游戏过程中可以对非玩家角色以及环境之间会形成更像真实世界与真人的互动,而这些 AI 模块可以充分和游戏剧情演进以及预先设定的人物性格紧密相连,并带给玩家更加沈浸的游戏体验。

而本次 GTC 上有不少议题围绕着深度学习与游戏开发之间的关系,我们都知道,过去几年来,游戏在场景设计、人物互动等越做越复杂,规模也越来越庞大,如果以传统的游戏开发方式来做游戏,那每个互动的场景以及角色应对都必须通过人力编排,这些工作内容包含了台词、行动或者是其他互动,如果像主流的 3A 大作,光是在这些与剧情相关的安排方面就必须花费非常庞大的人力成本。
知名的游戏大厂 UBI 近来也在其游戏开发环境中引入了 AI 辅助功能,虽然初步功能仅止于除错方面,但未来这类工具将对整体游戏产业的发展产生更深远的影响,游戏开发流程亦将可有效缩短,并借此大幅降低开发成本。
为免 AMD 咸鱼翻身,NVIDIA 踩线祭出合作伙伴计划确保市场
2018 年 3 月 1 日,Nvidia 发起了一项名为 GeForce 合作伙伴(GeForce Partner Program ,GPP)的计划。NVIDIA 称此计划是为了保证企业与玩家之间足够的透明,对于参与其中的制造商和代工厂,可以获得得 Nvidia 的资源支援,游戏捆绑优惠,销售回扣,包括全管道的 PR 推广、提早尝鲜新技术的机会、得到 Nvidia 工程师的支援参与游戏产品调试等。另外 GGP 计划可以随时加入和退出,没有强制措施。
然而有板卡厂商对 DT 君表示,毕竟 NVIDIA 也是经过大风大浪的厂商,即便踩线,也会相当程度的自保,比如说在合约条款中就不会提到排挤对手的字样描述,也不会写明若违反规则将受到怎样的处罚。然而即便条文中没有写明,但根据过去做过同样限制,具有市场独占地位的厂商的作法,基本上都带有相当大的强制性质,如果不配合,几乎都会受到减少供货,甚至断货的惩罚。

也因此,根据其所知,目前主要的板卡厂商几乎都已经加入该计划,而配合的产品品牌,比如说华硕的 ROG 系列,微星的 Gaming 系列,以及技嘉的 Gaming 系列,基本上就不会出现 NVIDIA 的竞争对手,也就是 AMD 的产品。
不过 NVIDIA 还是保留了一点空间给对手,只要不是挂厂商与 NVIDIA 合作的产品品牌,就不在此限制的范围。
以 NVIDIA 在 PC 独立绘图芯片市场将近 7 成的市占地位,此举可以说踩在垄断的边缘模糊地带,是相当危险的举动,过去英特尔就曾因为类似的举动而被贸易组织裁罚,面临高额罚金不说,同时也判赔 AMD 不少金额。
但为明知风险何仍坚持祭出这个作法,DT 君认为,以过去 NVIDIA 和 AMD 的知己知彼程度,显然 NVIDIA 已经预期 AMD 今年稍晚即将推出的新产品可能造成一定的威胁,而 NVIDIA 过去分心计算市场,在绘图领域没有太多着墨,也给了 AMD 一定的存活空间,为维持市场优势,避免 AMD 推出真正杀手级产品来个咸鱼翻身,先行通过市场操作,不让对手乘虚而入,另外也将尽快补上新架构,避免给对手可乘之机。
当然,这些市场策略看起来并不是那么光明正大,但回顾半导体产业历史,当一家企业的产品在市场上具有绝对优势时,要确保其市场地位,除了本身技术要持续革新以外,在市场营销策略上多多少少都会采用排他的作法,其实过去英特尔干过类似的事情,arm 亦曾采取类似的策略,NVIDIA 在 GPU 绘图市场虽有接近垄断的地位,但其实其宝座并不特别稳固,毕竟 AMD 虽然营销策略一向失败,但其绘图技术公认不下于 NVIDIA,只要产品规划得当,对 NVIDIA 仍是相当大的威胁。
-End-





