热烈祝贺南京某高校DGX-1深度学习超级计算机集群顺利交付
项目背景
随着人工智能(AI)特别是深度学习(Deep Learning)近年来的飞速发展,在多个领域的成功应用,已经成为当前学术界和各行业最炙手可热的研究应用方向。不仅广泛应用于搜索引擎、电子商务、社交网络等互联网服务,并且在计算视觉、自然语言处理、金融、生物医药等行业AI的研究与应用也呈现爆发式增长。同时由于深度学习(Deep Learning)需要处理的海量数据非常庞大,GPU(CUDA、OPENACC、OPENCL)计算在人工智能/深度学习领域展现出相比传统CPU计算巨大的优势,极大的提高了计算能力,降低时间成本,已经成为深度学习计算的首选解决方案。
为满足AI与数据科学的需求,NVIDIA DGX-1通过开箱即用的解决方案来加快实施您的AI计划,如此一来,您可以在几小时而非数月内获得见解。借助DGX-1,再加上集成式NVIDIA深度学习软件堆栈和DGX-1云管理服务,您只需插入并开启电源,即可开始工作。现在,您只需短短一天时间即可开始深度学习训练,而不必花费数月来集成和配置软硬件以及进行错误排查。
NVIDIA DGX-1可消除不断优化深度学习软件的负担,而且提供经优化的即用型软件堆栈,可让您节省数十万美元。它可使用当今最热门的深度学习框架、NVIDIA DIGITS深度学习训练应用程序、第三方加速解决方案、NVIDIA 深度学习SDK、CUDA工具包、快速多GPU集群NCCL、NVIDIA Docker以及NVIDIA驱动程序。
NVIDIA DGX-1介绍
硬件结构:


软件堆栈:
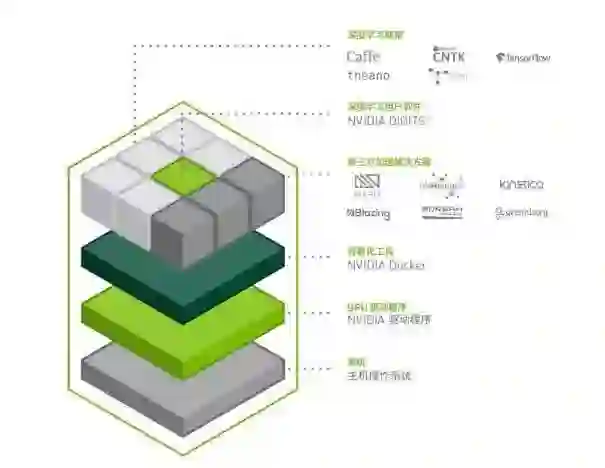
该软件架构具有很多优势:
• 每个深度学习框架都位于单独的docker容器内,所以每个框架都能使用不同版本的库,比如 libc、 cuDNN 等,并且不会相互影响。
• 为提高性能或修复问题,深度学习框架经过多次改进,现在 DGX Container Registry 中已有新版本容器。
• 系统易于维护,且由于应用程序并非直接安装于操作系统上,所以操作系统镜像非常干净。
• 可无缝提供安全更新、驱动程序更新及操作系统补丁。
这些深度学习框架和 CUDA Toolkit 都包含经定制调整的库,可以在 DGX-1 上提供较高的多 GPU 性能。
DGX-1 适用的深度学习框架
NVIDIA Caffe
Caffe7 深度学习框架在设计时已将灵活性、速度和模块化考虑在内。该框架最初是由伯克利视觉和学习中心 (BVLC) 及社区贡献者共同开发。 NVIDIA Caffe是由 NVIDIA 维护的 BVLC Caffe 分支版本,专门针对 NVIDIA GPU(尤其是多 GPU 配置)进行调整。NVIDIA Caffe 包括多精度支持以及其他 NVIDIA 增强功能,并且提供专门针对 NVIDIA DGX-1 调整的性能。 以下总结列出了 NVIDIA Caffe 的优化和变更内容。
• 采用最新版的 cuDNN
• 集成支持 NVLink 的最新版 NCCL,可提升多 GPU 扩展性。使用数据并行 SGD 时,支持 NVLink 的 NCCL 可将 ResNet-50 训练性能提升 2 倍
• 采用并行解析器以提升 I/O 性能
• 微调性能
• 支持 16 位浮点 (FP16 ) 计算和存储,可降低一半的内存和存储要求
• 自动选择最佳卷积算法
b. Microsoft Cognitive Toolkit
Microsoft Cognitive Toolkit8 (CNTK) 是统一的深度学习工具包,让用户可轻松实现并合并前馈深度神经网络 (DNN)、卷积神经网络 (CNN) 和递归神经网络 (RNN) 等热门模型类型。CNTK 跨多个 GPU 和服务器进行自动微分和并行化,以执行随机梯度下降 (SGD) 学习。CNTK 可称之为 Python 或 C++ 应用程序库,或是作为使用 BrainScript 模型描述语言的独立执行工具。 NVIDIA 已和 Microsoft 紧密合作,加快 Cognitive Toolkit 在 DGX-1 和 Azure N 系列虚拟机等 GPU 系统中的运行速度。双方的合作为初创公司和大型企业等提供了极大的易用性和可扩展性,这是因为单个框架可用于 DGX-1 内部部署的首批训练模型,之后可再将这些模型部署到 Microsoft Azure 云 9 。 以下总结列出了 DGX-1 CNTK 的优化和变更内容。
• 采用最新版的 cuDNN
• 集成支持 NVLink 的最新版 NCCL,可提升多 GPU 扩展性。使用数据并行 SGD 时,支持 NVLink 的 NCCL 可将 ResNet-50 训练性能提升 2 倍 • 改进图像阅读器管道,允许 AlexNet [Krizhevsky et al.2012] 以超过 12,000 张图片/秒的速度进行训练
• 为多 GPU 训练的每块 GPU 可减少高达 2 GB 的 GPU 内存用度
• 扩大卷积支持
c. MXNet
MXNet10 是专为提高效率和灵活性而设计的深度学习框架,让您可以混合符号编程和命令编程,以最大限度提升效率和生产力。MXNet 的核心是动态依赖调度程序,可自动即时并行处理符号式操作和命令式操作。在调度程序之上增加图形优化层可加快符号执行速度并提高内存效率。MXNet 轻量便携,并且可扩展至多个 GPU 和多台机器上。
以下总结列出了 DGX-1 MXNet 的优化和变更内容。
• 采用最新版的 cuDNN
• 改进输入管道,便于处理图像
• 优化嵌入层 CUDA 内核
• 优化张量传播和简化 CUDA 内核
d. TensorFlow
TensorFlow11 是使用数据流图表进行数值计算的开源软件库。图像中的节点代表数学运算,而图像边缘则代表节点间流动的多维数据阵列(张量)。您可通过此灵活的架构,将计算部署到桌面、服务器或移动设备中的一个或多个 CPU 或 GPU,而无需重写代码。 TensorFlow 最初由 Google Brain 团队(隶属于 Google 机器智能研究组织)的研究人员和工程师 开发,旨在进行机器学习和深度神经网络研究。该系统具有极佳的通用性,也适用于其他各种领域。 以下总结列出了 DGX-1 TensorFlow 的优化和变更内容。
• 采用最新版的 cuDNN
• 以 libjpeg-turbo 替换 libjpeg
• 集成支持 NVLink 的最新版 NCCL,可提升多 GPU 扩展性。使用数据并行 SGD 时,支持 NVLink 的 NCCL 可将 ResNet-50 训练
e. Theano
Theano12 是一个 Python 库,能让您有效定义、优化和评估涉及多维阵列的数学表达式。自 2007 年起,Theano 便一直为大规模计算密集型科学调查提供支持。 以下总结列出了 DGX-1 Theano 的优化和变更内容:
• 采用最新版的 cuDNN
• 运行时代码生成:更快速地评估表达式
• 广泛的单元测试和自我验证:检测与诊断多种类型的错误
f. Torch
Torch13 是一种科学计算框架,可为深度学习算法提供广泛支持。由于简单且快速的脚本语言 Lua 以 及底层 C/CUDA 实现,Torch 易于使用且效率很高。Torch 提供热门的神经网络和优化库,不但容易使用,而且还提供超大灵活性,以构建复杂的神经网络拓扑。 以下总结列出了 DGX-1 Torch 的优化和变更内容。
• 采用最新版的 cuDNN
• 集成最新版、采用 NVLink 支持的 NCCL,以提升多 GPU 扩展性。使用数据并行 SGD 时, 支持 NVLink 的 NCCL 可将 ResNet-50 训练性能提升 2 倍
• 缓冲待 NCCL 通信的参数,以降低延迟用度
• 针对递归网络(RNN、GRU、LSTM)的 cuDNN 绑定(包括持久性版本),可大幅提升小批量训练的性能
• 扩大卷积支持
• 支持向 cuDNN 例程的 16 和 32 位浮点(FP16 和 FP32)数据输入
• 支持对 FP16 张量的操作(使用 FP32 算法)
g. DIGITS
NVIDIA 深度学习 GPU 训练系统 (DIGITS)14 将深度学习的强大功能交由工程师和数据科学家掌控。 DIGITS 可用于快速训练高度准确的深度神经网络 (DNN),以执行图像分类、分割以及物体检测等任务。DIGITS 可简化常见的深度学习任务,例如管理数据、在多 GPU 系统上设计和训练神经网络、 使用高级可视化技术实时监控性能,以及从结果浏览器中选择性能更好的模型用于部署。DIGITS 采用完全交互式的设计,因此数据科学家可以专注于设计和训练网络,而不必进行编程和调试。 以下总结列出了 DGX-1 DIGITS 的优化和变更内容。
• DIGITS 运行于针对 DGX-1 进行优化的 Caffe 和 Torch 框架之上
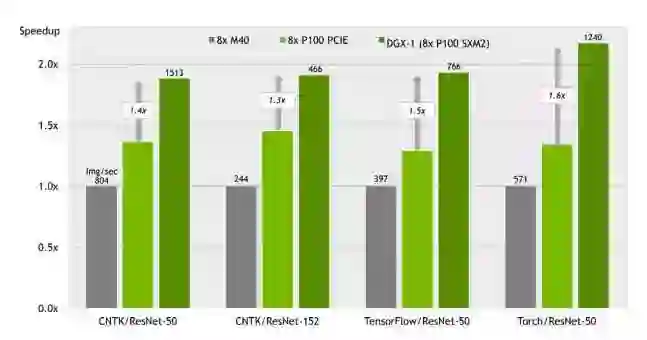
结果:为实现最高深度学习性能而打造的 DGX-1
性能对照表:
交付现场实拍图 (负责项目实施的我司高级工程师李工)








