【NeurIPS 2021】实例依赖的偏标记学习

论文标题:
Instance-Dependent Partial Label Learning
论文链接:
https://www.zhuanzhi.ai/paper/70739bd32a8310f090296cf05f3ba5ae
代码链接:
https://github.com/palm-ml/valen
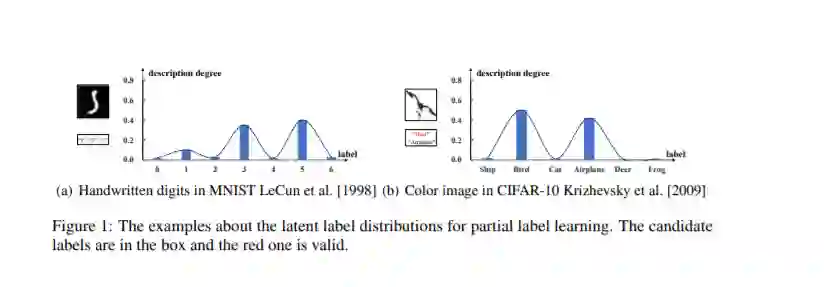
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“IDPL” 就可以获取《【NeurIPS 2021】实例依赖的偏标记学习》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月20日
Arxiv
2+阅读 · 2022年4月19日
Arxiv
15+阅读 · 2020年3月31日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
2+阅读 · 2022年4月19日
Arxiv
15+阅读 · 2020年3月31日