【万字长文】注意力机制可解释大论述
2020年了,你还在用注意力作可解释吗?
本文是《The elephant in the interpretability room: Why use attention as explanation when we have saliency methods?》文章的延伸解读和思考,内容转载请联系作者 @Riroaki 。
原文链接:https://zhuanlan.zhihu.com/p/287126616?utm_source=wechat_timeline&utm_medium=social&utm_oi=738537901201063936
本文主要基于2020 EMNLP Workshop上的一篇综述文章,介绍了NLP可解释领域的重大争议——注意力机制是否能作为解释?而什么方法才是真正符合解释逻辑的?
原论文链接:https://arxiv.org/abs/2010.05607
The elephant in the interpretability room: Why use attention as explanation when we have saliency methods?
本文目录
0. 引言:问题描述
1.注意力方法:是否构成可解释?
-
关于注意力的辩论 -
注意力分析的问题是否合理 -
注意力方法与因果解释 -
改进注意力以更好地作出解释
2. 显著性方法
-
基于梯度的方法(gradient-based methods) -
基于传播的方法(propagation-based methods) -
基于遮挡的方法(occlusion-based methods)
3. 注意力vs显著性
4. 注意力一无是处?非也
-
注意力研究依然重要 -
注意力可以为其他解释提供参考
5. 显著性就是终极的解释方法了吗?
-
在显著性之外 -
显著性方法的局限性
6. 结论
0. 引言
注意力机制(attention mechanism)在NLP的许多领域都可以提高性能,其中包括机器翻译,自然语言生成和自然语言推论等。此外它还可以提供一个窗口,了解模型的运行方式。例如,对于机器翻译,Bahdanau等人(2015)可视化目标token要使用的源token,将翻译的单词进行对齐。
在可解释领域,注意力机制落入模型的运行方式是否构成解释成为关注焦点。尽管许多以可解释的AI为主题发表的论文都因未定义解释而受到批评(Lipton,2018; Miller,2019),但最早的关键研究引起了人们对作为解释的关注(Jain和Wallace,2019; Serrano和Smith,2019);Wiegreffe和Pinter,2019)确实表示,他们对关注权重是否忠实代表每个输入token对模型预测的责任很感兴趣。
也就是说,狭义的解释意味着存在着最重要的预测输入标记(arg max),准确地总结了模型的推理过程(Jacovi和Goldberg,2020b)。
有趣的是,上述工作中对解释的隐含定义恰好与设计的**输入显著性方法(saliency methods)**相吻合。此外,该解释的用户通常默认为模型的开发者,对他们而言忠诚度(faithfulness)至关重要。
Faithfulness和plausibility相对应,前者指解释方法是否始终如一地能够反映模型表现,后者指直觉上是否合理(似然性)。关于这两者的讨论可见2020年ACL论文《Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness?》
因此,标题中的“房间里的大象”即:如果使用注意力作为解释的目标是忠实地为输入token分配重要性权重,那么为什么要使用注意力机制而不是为实现该目的而设计的众多现有输入显著性方法?

房中大象:用来隐喻某件虽然明显却被集体视而不见、不做讨论的事情或者风险,抑或是一种不敢反抗争辩某些明显的问题的集体迷思。
1. 注意力方法:是否构成解释?
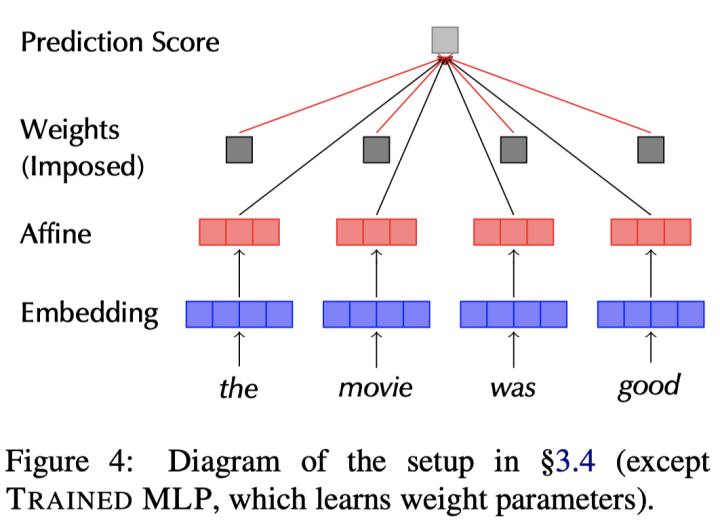
首先,介绍一下在如下关于注意力方法是否构成可解释的争论中,讨论的基本模型:Bi-LSTM+tanh Attention文本分类模型(如下图):
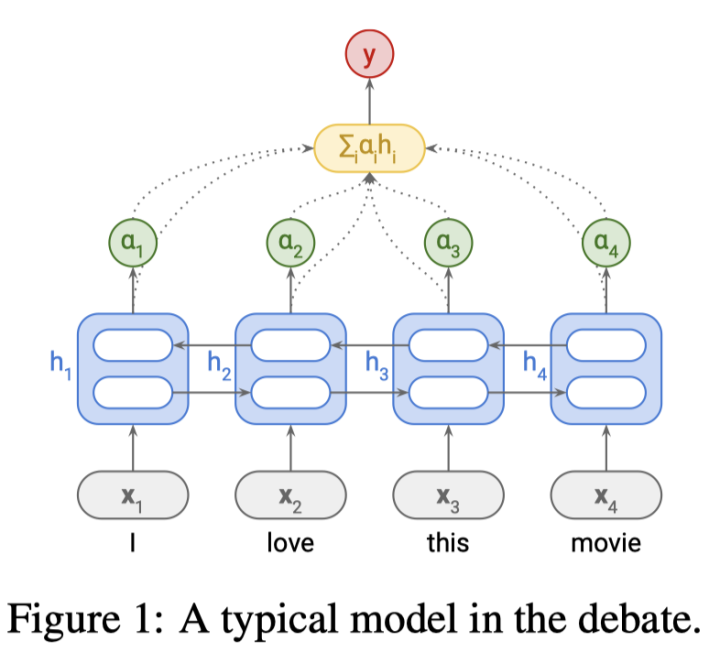
这一模型只有一个注意力层,通常这一机制基于MLP结构:
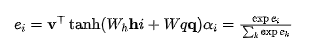
其中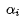
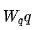
1.1 注意力之辩:是(不是)解释?
反方辩手:注意力不能做解释!
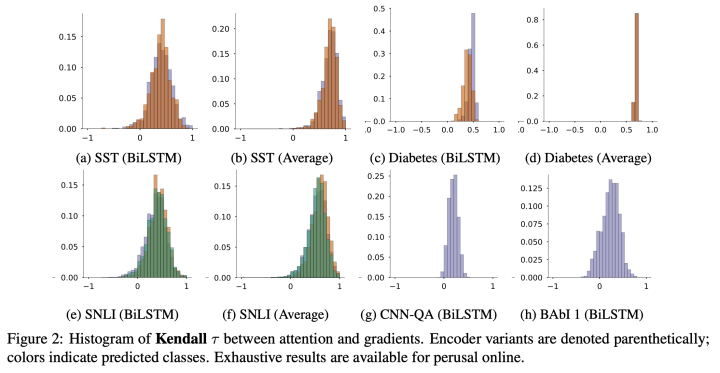
Jain和Wallace(2019)的论文《Attention is not Explanation》将注意力权重的分布和基于特征的显著性度量分布进行比较,并且做了将句子输入进行扰动然后对注意力权重做对抗性搜索,得出结论:
-
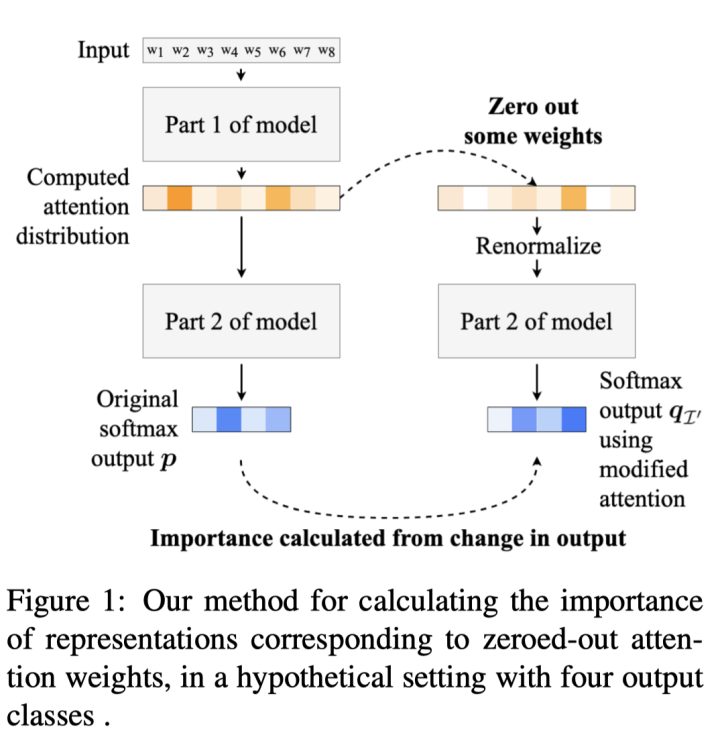
通过修改注意力权重(修改方法:intermediate representation erasure,如下图) ,它们经常没有识别出那些对模型预测最重要的表示; -
基于梯度的注意力排序往往比注意力权重更能反映文本对预测的的重要程度。
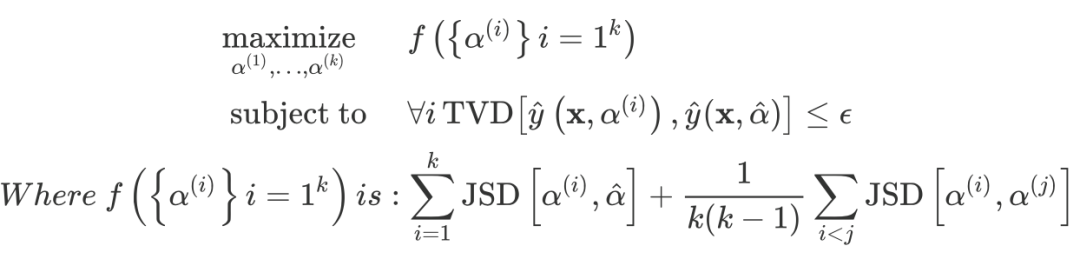
Serrano和Smith(2019)在论文《Is Attention Interpretable?》中写道:
正方辩手:注意力可以是解释!
-
Wiegreffe和Pinter(2019)在论文《Attention is not not Explanation》(看标题就知道是在怼谁哈哈)声称注意力可以是(might be)解释: -
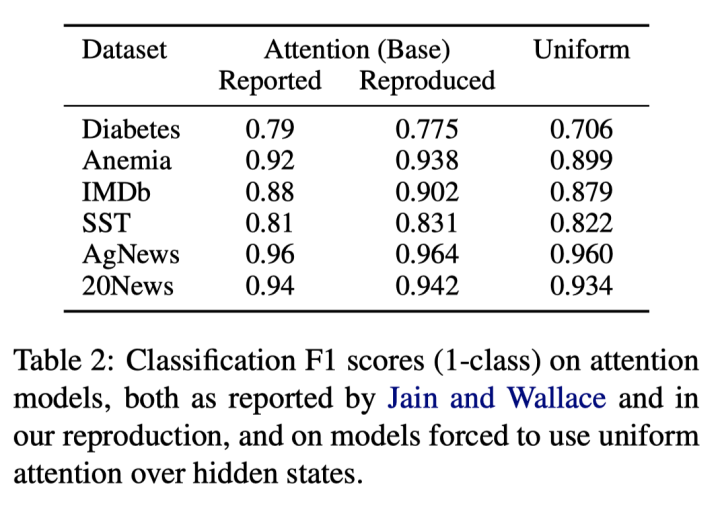
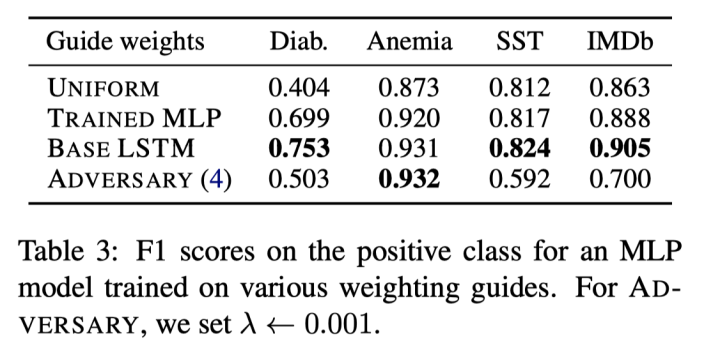
实验一,uniform-weights baseline:在训练好的模型中将注意力权重单独固定为随机分布,和原始模型在测试数据上进行比较,发现竟然效果差别不大(如下表)。 -
实验二,expected variance:和反方一辩提出的对抗注意力方法一样,但是变换随机种子对比效果——结果发现在SST数据集上进行扰动较为稳定,而其他数据集上attention的分布情况变化较大。但是总体可以看出无论是对抗方法还是随机种子,对模型attention的影响都比较大。 -
实验三,diagnose attention:将原模型的LSTM换成一个带tanh激活的MLP,分别进行(1)随机化MLP并进行测试;(2)固定注意力层,单独训练MLP部分并进行测试。在替换后的模型中,除了attention层以外不会接触上下文信息。将这一结果与原模型的效果进行比较,效果为原模型>替换LSTM为线性层>>随机分布attention,说明attention并不是随机的,它有学习到某种模型无关的token重要性信息。 -
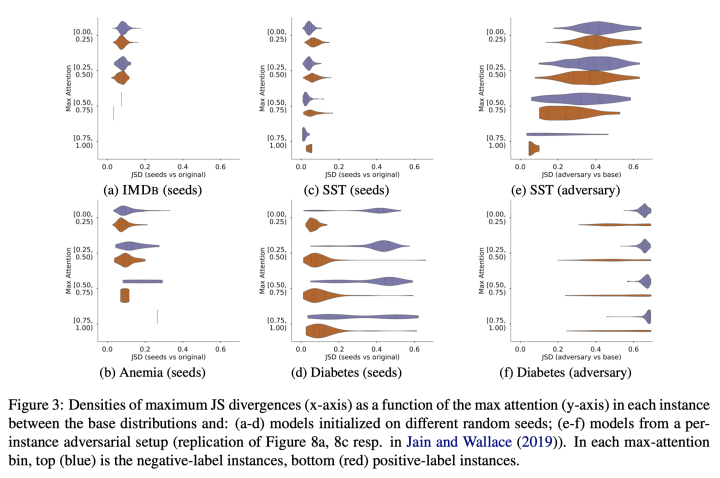
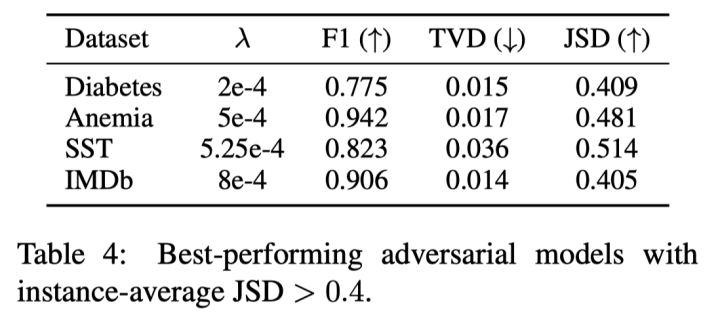
实验四,model-consitstent adversery:和反方一辩提出的方法不同,这里提出了一个能够在所有实例上起作用的注意力对抗方法,通过定义一个特别的损失: (即约束和原始模型的预测差异,同时增大attention的分布差异),并以蒸馏形式(严格来说不能算蒸馏,这里借用这一概念方便理解)训练一个结构相同的模型,这一模型可以在与原始模型输出相似的前提下使得attention权重分布尽量和原始模型不一致。 -
最终训练效果上,可以在基本保持模型预测效果的前提下达到0.4的KL散度,这是较大的分布差距了。而且几个例子的热力图能说明,和反方辩手的将注意力集中在单个token上的操作不一样,这里的实验能够使得多个token的注意力发生绝对值大于0.1的改变! -
实验四的补刀来了:此时对上述的模型进行LSTM替换的实验,发现模型在替换后无法为MLP层提供预测信息,导致新的模型效果变得很差!(下表最后一行,Adversery模型结果显著低于上方模型) -
反方一辩论将注意力和基于梯度的方法比较的部分没有问题,但是通过对抗找到等价注意力权重的方式是有问题的:
-
注意力并非在所有场合起作用,以下四个定量的测试可以说明。
-
" Attention Distribution is not a Primitive.":注意力机制本来就不是一组数字,和整个模型协调工作才有意义,凭空产生一个对抗分布只是在数值上等价但是这个分布是没有意义的。 -
"Existence does not Entail Exclusivity.":LSTM模型输出可以通过多种方式组合得到模型预测,而这里偏偏使用了注意力的输出。并且对每个样本各自做对抗找到反例而不是找一个对全部样本都有效的分布简直不要太简单。 -
而且,这一工作没有提供一个基线能证明对抗方法的有效性:到底能在多大程度上改变多少注意力权重?改变多大能算有显著区别?
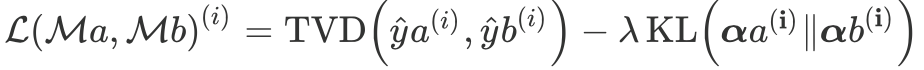
最后,Pruthi等人(ACL2020)在《Learning to Deceive with Attention-Based Explanations》中提出了一种产生欺骗性注意力权重的方法。他们的方法通过在训练过程添加一个惩罚项,可以诱导注意力权重分布倾向于部分“不被允许的词”(例如,特定性别相关的token),以很小的性能损失训练出一个结构相同但是带有偏见的模型,当使用这一模型的注意力权重进行解释时,将会影响公正性。
从上述讨论可以发现,注意力即使可以用作解释,其适用范围也存在很大的局限性,至少无法完全对预测作出忠实的解释——因为即便是针对同一个预测,也能通过一定方法获得不同的注意力解释,说明这一解释是不合理的。
补充:关于《Attention is not Explanation》和《Attention is not not Explanation》之间的争论,知乎上也有一些评论和解说:如何评价NAACL2019 paper:Attention is not Explanation? - LinT的回答 - 知乎
如何评价NAACL2019 paper:Attention is not Explanation?
1.2 使用注意力机制分析的任务是否合理?
本节指出,在不同任务上注意力能起的作用不同,因而解释效果也有不同,无法一概而论。
Vashishth等人(2019年)在《ATTENTION INTERPRETABILITY ACROSS NLP TASKS》中提出注意力机制在单个序列的模型中远不如涉及两个序列的模型(如NLI或MT)重要。
如果使用统一权重,NMT 模型的性能会显著降低,而随机注意权重对文本分类性能的影响最小。因此,文本分类研究的结果可能不会概括为注意力是关键组成部分的任务。
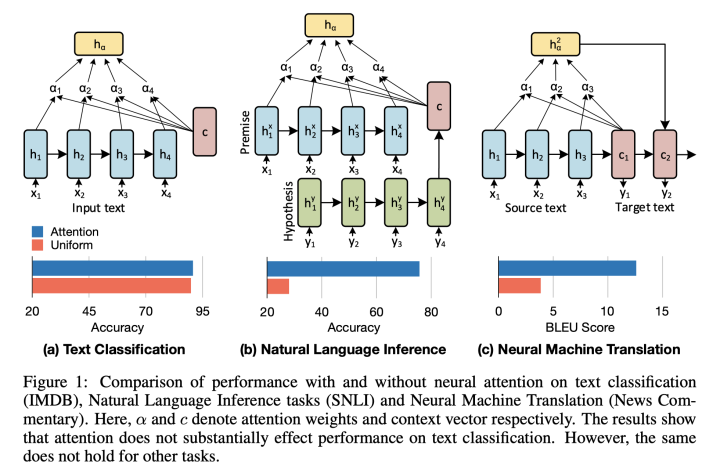
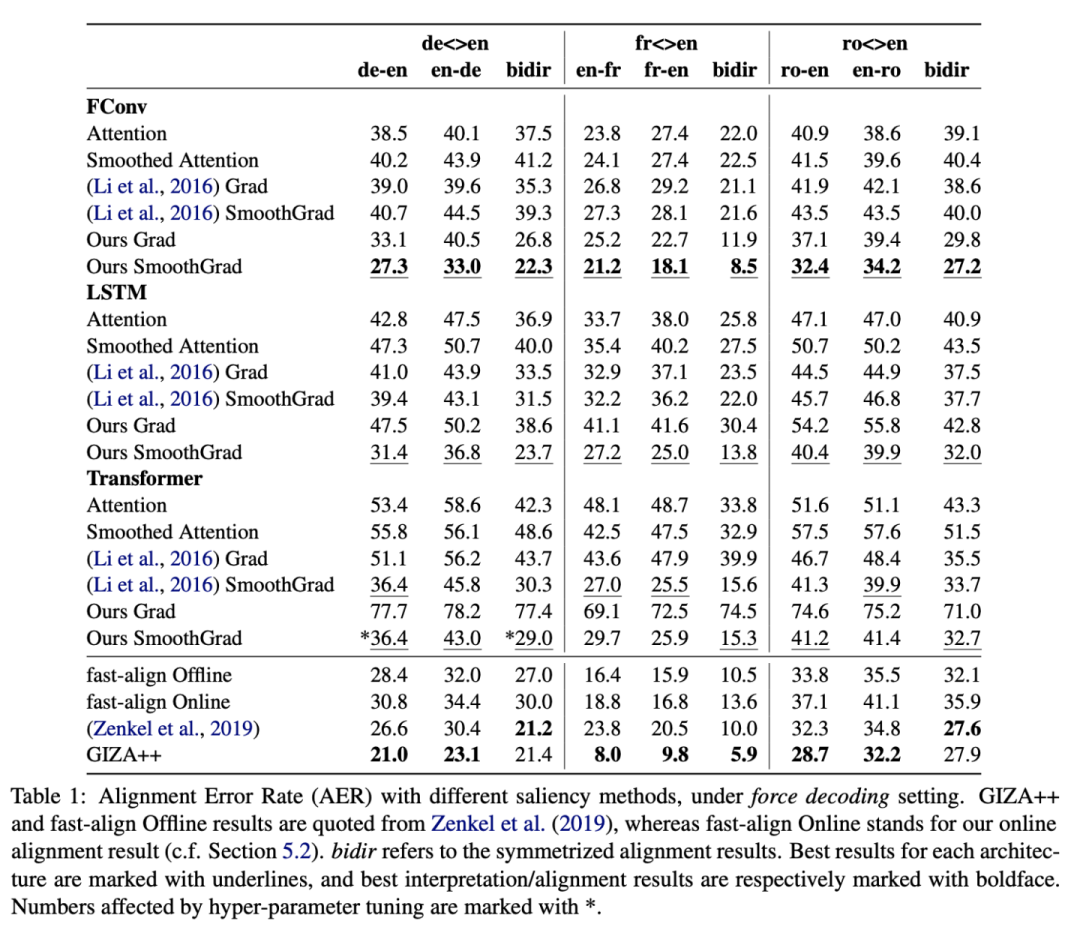
然而,有工作提出,即使在机器翻译这样的领域显著性方法表现依然比attention更好(Ding等,ACL2019,《Saliency-driven word alignment interpretation for neural machine translation》)。
Ding等人的工作中在基于梯度和注意力的解释方法基础上,还提出smooth-grad,以及smooth-attention:对输入的word embedding做扰动,加入高斯分布的随机噪音,并将梯度/注意力结果取平均值,以获得更稳定的结果。
下图为对比的实验结果,这里的衡量手段为将注意力的关注结果与人工标注的结果进行对比,指标为AER(Alignment Error Rate):
1.3 注意力机制是否能构成因果解释?
这一部分笔者了解并不多,所以仅仅简略摘要部分内容,有待补充。
Grimsley等人(2020年)在《Why attention is not explanation: Surgical intervention and causal reasoning about neural models》说,按照解释的因果(Causality)定义,注意力就不是定义的解释。
借鉴科学哲学工作,作者指出因果解释预意味着“外科手术式的干预“(surgical intervention)是可能的,而深度神经网络则不是这样:无法在保持所有其他变量不变性的同时仅仅干预注意力这一变量。
尽管人们期待直观的“know it when they see it”一望便知的解释方法,然而关于解释的定义及其评估方法尚无一致的结论。这篇文章从干预主义的因果逻辑出发,针对可解释提出了三个问题:
-
干预主义的观点分析可解释研究是否合适? -
可解释的研究是否实现了手术式的干预(surgical intervention)以获得因果上的论据? -
当attention无法被手术式地操作,基于attention的解释方法会导致什么结果?
干预主义者的论述只涉及科学中的因果解释。这也导向了一个推论:当一个网络不会也不会产生因果关系的解释时,它仍然可以提供替代的非因果类型的解释。并且:
-
在产生可解释的神经模型时应寻求这些类型的解释。 -
非因果解释是可以从手术干预失败的神经模型中得出的唯一解释类型。
插入介绍一下解释哲学的流派:
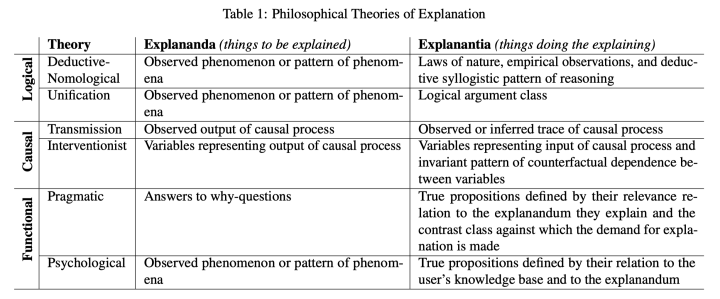
作为因果解释,需要有以下的要素:
-
干预的可操作性 -
干预即对变量进行量化的操作,观察记录其带来系统整体的输出变化 -
可量化的干预会对结果造成相应的影响 -
干预的过程是手术式的,即控制变量 -
如下图中,左图是可干预的(观察A和C关系时控制B),右图则抵抗干预(做不到控制变量)
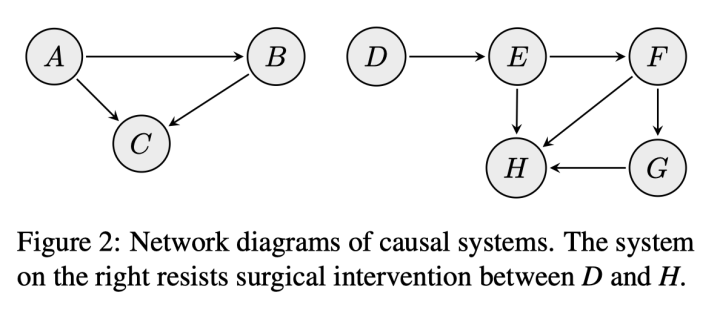
注意力机制只是整个模型的一小部分,而和注意力相关的还有注意力之前的层;而在控制变量的干预中,其他的变量必须指保持不变的(invariant)。
由于不满足因果解释的条件,这种基于注意力的解释方法不是因果解释,只是似然的解释(满足人们心理的解释)。
这里仅仅涉及文章的一部分讨论,具体细节请查看原始论文《Why attention is not explanation: Surgical intervention and causal reasoning about neural models》
1.4 提升注意力的可解释性
如果对注意力还不死心的话,还可以想办法改进注意力以实现更忠实的可解释。
Mohankumar 等人 (2020)《Towards transparent and explainable attention models》 观察到LSTM状态的隐藏表示高度相似性,并提出了多元化驱动(diversity-driven)的训练目标,使隐藏表示在时间步长之间更加多样化。它们使用representation erasure,与原始注意力相比,由此产生的注意力权重更容易导致决策翻转。
-
这文章批判了一番注意力,抬了一手积分梯度,不过这不是最早提出将积分梯度用在NLP上的工作。 -
发现各个单词的LSTM隐藏表示接近,随机化排列attention都不影响模型结果。 -
提出了一种diversity-driven LSTM以增强attention可解释性,并用pearson相关度和JS散度来衡量attention结果和IG的相似度,说明了自己模型的效果。
Tutek 和 Snajder (2020) 具有类似的动机,使用单词级目标,在隐藏状态和它们所代表的词之间实现更牢固的连接,从而影响注意力。Deng等人(2018年)提议以variational attention作为Bahdanau等人(2015年)soft attention的替代,认为后者不是一致的,而只是一种近似性。它们具有允许后对齐的额外好处,以输入和输出句子为条件。
2. 显著性方法
终于到了本文的主角——显著性方法(Saliency methods)。
这里的显著性方法主要讨论了基于梯度的方法(Gradient-based methods)、基于传播的方法(Propagation-based methods)和基于擦除的方法(Occlusion-based methods)。此外还有一类方法依赖替代模型(LIME等),由于解释成本较高而不在此讨论。
下图来源:《Evaluating Recurrent Neural Network Explanations》,这里的CD又是另一种方法了,不做展开

2.1 基于梯度的方法
2.1.1 Gradient/梯度:
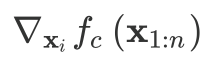
Jiwei Li等,2016《Visualizing and understanding neural models in NLP》
本文首先总结了此前CV领域的多种特征可视化方法:反演(Inversion)、反向传播与反卷积网络(Back-propagation & Deconvolutional Networks)、生成(Generation)等技巧。
然后对NLP领域的SST情感分析、AutoEncoder还原两个任务,分别在原始词句、语义增强或取反、以及语句连接(转折/并列关系等)的词句上进行如下的可视化技巧:
-
t-SNE,对词/句向量进行降维,在2d平面可视化。 -
Saliency,绘制输出对输入的一阶梯度热力图,以梯度绝对值衡量预测对输入的敏感度,较大梯度对应的词称为sentiment token(或者sentiment indicator),即在情感分析任务起较大作用的词。 -
Average and Variance,对saliency作句内平均和差分,和第二点的作用相同。
下图为情感分析任务的saliency可视化:
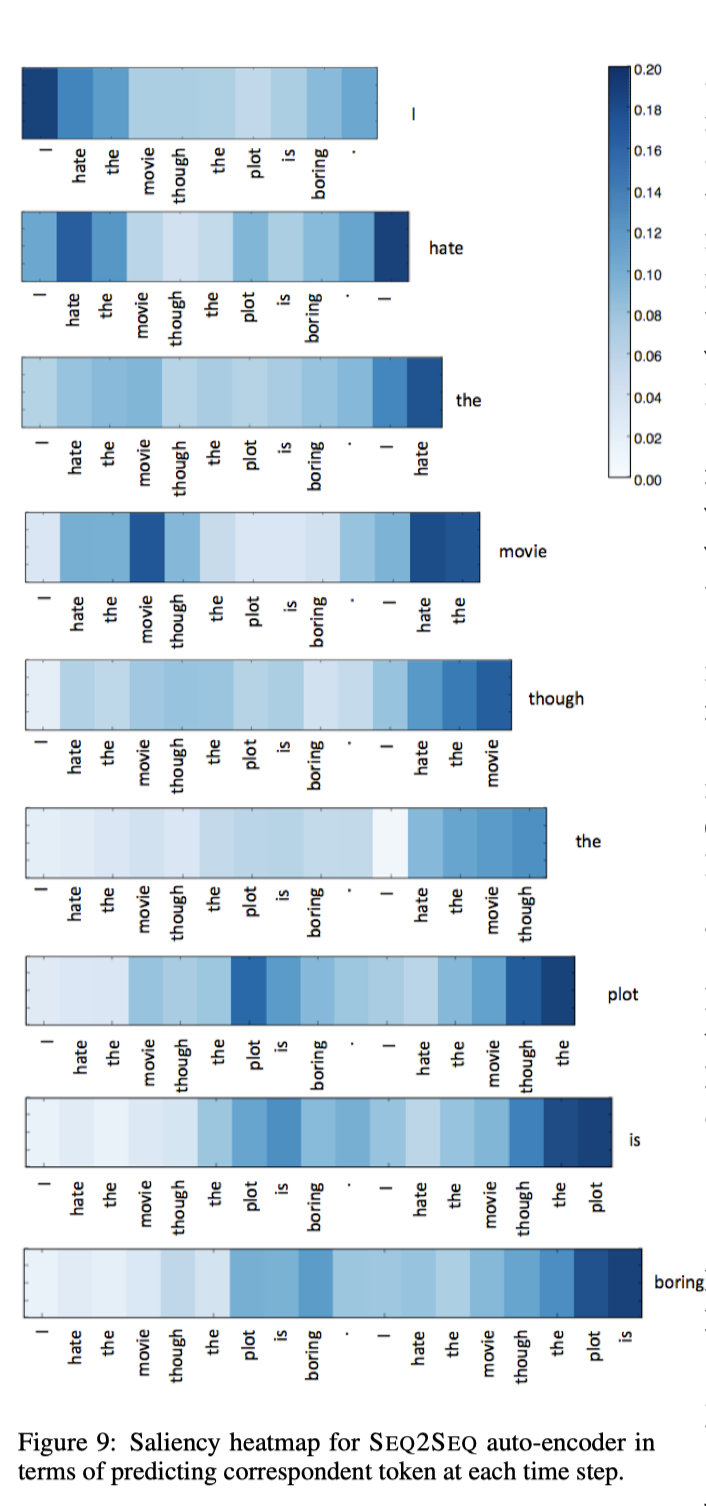
下图为seq2seq任务(这里用的是还原输入的auto-encoder)的saliency可视化随时间步的变化:
2.1.2 Gradient*input/梯度与输入的乘积:
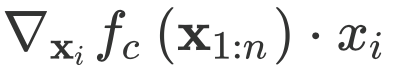
Denil等,2015年arxiv《Extraction of salient sentences from labelled documents》
这一篇提出了一种层次卷积CNN,并提出了基于梯度和输入乘积的可视化方法识别和提取与主题相关的句子,如下图:

这篇参考了CV领域的《Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps》的显著性图,这一篇也推荐读者阅读。
以及为自动句子提取系统引入了一种新的可扩展评估技术,从而避免了耗时的人验证数据的注释。当然,这篇文章对比对象比较弱(一个用了word2vec的浅层网络,一个随机方法,一个启发式方法)。
2.1.3 Integrated Gradient/积分梯度:
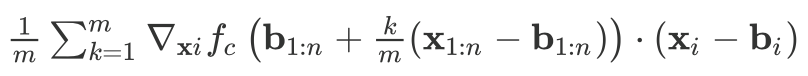
Sundararajan等,ICML2017《Axiomatic attribution for deep networks》
这篇文章不但提出了预测归因的新方法——积分梯度,还提出了如下的解释性方法应当满足的公理(Axiom):
-
Sensitivity(敏感度):对于某个特征不同导致预测结果不同的输入,解释方法应该对这一不同的特征具有非零的归因。反之,如果模型预测(数学上)不取决于某个变量,那么它的归因因该是零。 -
梯度方法违背了该公理。举个具体的例子,对于ReLU(1-x),对 的变化区间,输出从0变到1,但是在x=1的时候,梯度方法给出的归因值为0。这显然是不合适的——这就是重要的 梯度饱和(Gradient Saturation)问题。
-
反卷积网络(Deconvolution networks)和引导反向传播(Guided Back-propagation)方法也违背了这一公理,原因同上。 -
DeepLIFT和LRP(Layer Relevance Propagation,后面会介绍)这一类方法计算的是离散梯度而非瞬时梯度,它们满足这一公理。
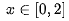 的变化区间,输出从0变到1,但是在x=1的时候,梯度方法给出的归因值为0。这显然是不合适的——这就是重要的
梯度饱和(Gradient Saturation)问题。
的变化区间,输出从0变到1,但是在x=1的时候,梯度方法给出的归因值为0。这显然是不合适的——这就是重要的
梯度饱和(Gradient Saturation)问题。
关于梯度饱和问题,可以参考《Not just a black box: Learning important features through propagating activation differences》。此外,之前的文章里也有讨论相关的内容,以及积分梯度的简单科普(Q3部分):
DiagnoseRE:关系抽取泛化性能分析
-
Implementation Invariance(实现不变性):如果两个结构实现不同的网络的输出对于所有输入均相等,则它们在功能上是等效的,则应当满足其归因一致。归因方法应满足实现不变性,即,对于两个功能等效的网络,归因始终是相同的。这样的定义不涉及实现细节。 -
现在讨论DeepLIFT和LRP。这两个方法使用离散梯度代替了常规的梯度,而梯度方法是满足实现不变性的,替代后的结果则不满足这一规则。下图(来自原文附录B)是一个具体例子,两个功能完全一致的网络,DeepLIFT和LRP的最终归因不同,而积分梯度是满足这一性质的。 -
如果归因方法不能满足实现不变性,则归因可能对模型的不重要方面敏感。例如,如果网络体系结构的自由度超过了表示一个功能所需的自由度,则可能有两组导致相同功能的网络参数值。取决于初始化或其他原因,训练过程可以收敛到一组值上,但是底层网络功能将保持不变。由于这些原因,模型的归因解释是不同的。

好,接下来用一句话介绍积分梯度这一方法:
所谓积分梯度,就是将输入沿着基线(即输入的变化起点)到当前值(即当前输入)的梯度进行积分,获得一个路径积分:
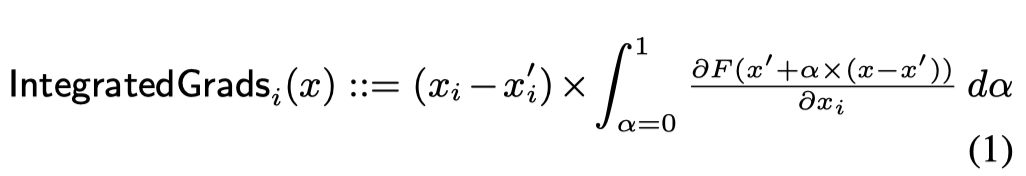
这一条积分路径不影响结果,所以出于简单考虑选择线性路径,用等间隔的面积进行近似。
紧接着作者提出了另一条公理:
-
Completeness(完整性):归因等于输入值的预测与基线值的预测之间的差。这一公理使得解释性方法可以定量计算特征的重要性,而不仅仅是选择最高的标签。
显然,积分梯度方法是满足这一公理的。而积分梯度也满足实现不变性,因为它只基于模型梯度!
这是一个很神奇的推论:两个模型的功能完全一致->模型的梯度一致->基于梯度的可解释是一致的。
此外,积分梯度还满足很多奇妙的性质,此处篇幅所限不加展开。
下面介绍积分梯度方法的实验结果。
-
ImageNet图像识别(看起来更还原图像的边缘了)

-
问题分类,标记红色和蓝色分别对应支持预测结果的token和不支持的token。 -
这里的红色,灰色,蓝色对应正,零,负的归因 -
这里发现,基于积分梯度的归因很大程度上和人工定义的规则一致,同时也有助于发现新规则;但是也有如“charles”之类的数据bias导致的错误归因。

-
翻译任务

这篇文章在图像、文本和一个化学场景都做了实验。大概这就是ICML水准的论文吧~除了新方法,还有理论,并且有多组跨领域的实验。
在介绍了梯度方法以后,这里引用Ancona在2017年的《Gradient-Based Attribution Methods》提出的一点小小区分:敏感度(Sensitivity)和显著性(Saliency):
-
敏感度(Sensitivity)指的是,输入需要变化多少才会引起输出变化;显著性(Saliency)指的是每个输入单词对预测的边际效应(marginal effect)。 -
梯度方法测量Sensitivity,而梯度×输入和IG测量显著性(Saliency)。模型可能在某个时间步上对输入敏感,但对预测很重要的部分则取决于实际输入向量。
2.2 基于传播的方法
这里概要介绍一下分层相关传播(Layer-wise Relevance Propagation,LRP)。
首先是对获得输出$f_c(x_{1:n})$ ,这是顶层相关性。然后,使用特殊的向后传递,在每个层将传入的相关性重新分配到该层的输入之间。
每种层都有自己的传播规则。例如,对于前馈层(Bach等,2015)和LSTM层(Arras等,2017)有不同的规则。相关性将重新分配,直到到达输入层。尽管LRP需要实现自定义的反向传递,但它确实允许精确控制以保持相关性,并且已被证明比在文本分类中使用基于梯度的方法更好(Arras等,2019)。
Arras等人在ACL2019的workshop《Evaluating Recurrent Neural Network Explanations》
这一篇对多种方法进行了比较:

值得注意的是,这篇文章的比较中提到积分梯度方法比CD(Contextual Decomposition,这又是另一个方法了)和LRP要差?论据如下:
-
论据一,ICLR2018发表的《BEYOND WORD IMPORTANCE: CONTEXTUAL DECOMPOSITION TO EXTRACT INTERACTIONS FROM LSTMS》对CD和IG进行比较,在LSTM模型上进行比较,包括词级别、句子级别(子句):
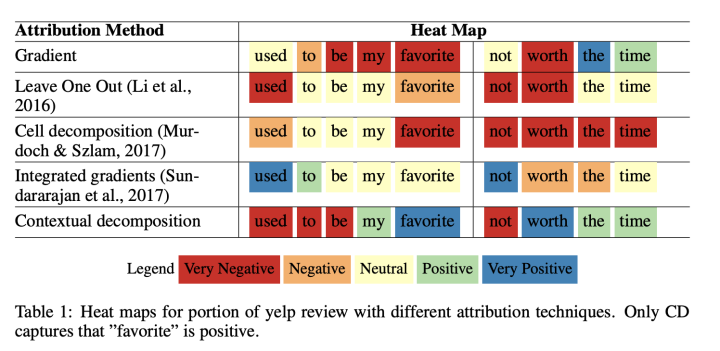
这里的比较是用积分梯度的正负对应情感的正负,并将其与LR的参数进行相关度计算,这一实验结果中CD和IG是最好的,但是IG依然不如CD。
-
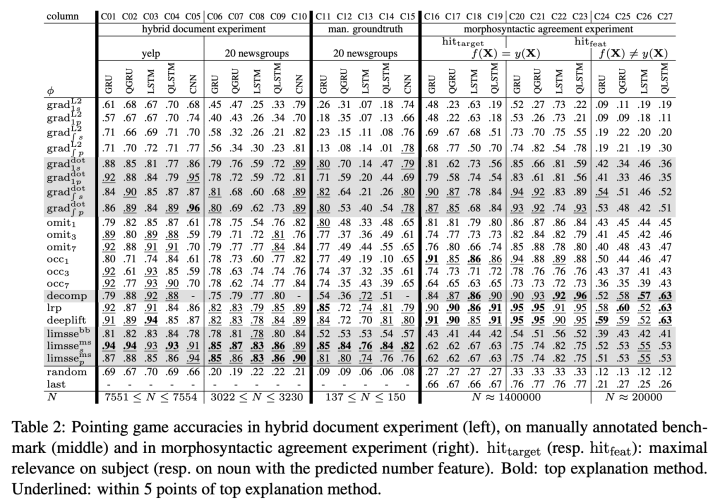
论据二,ACL2018发表的《Evaluating neural network explanation methods using hybrid documents and morphosyntactic agreement》对多种方法进行比较:
这边有三种实验的比较结果,结论是积分梯度不如LRP方法,感兴趣的读者可以阅读原始论文:
2.3 基于遮挡的方法
通过遮挡(Occlusion)或擦除输入特征,并测量其对模型的影响作为输入的显著性。直观上,删除不重要的特征不会影响模型,而对于重要特征则相反。
2.3.1 基于遮挡
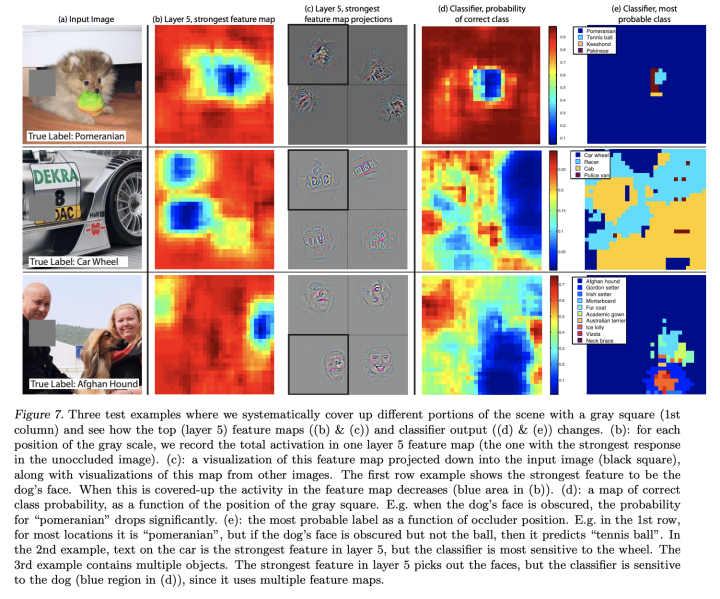
2014ECCV《Visualizing and understanding convolutional networks》
这篇非常出名、引用量上万的文章本意不是要讲擦除的,而是对CNN的层特征进行分析,顺手做的……因为主要是讲CV的所以就不详细介绍了。
贴个图,对原始图像的遮挡和识别的变化,一目了然:
2.3.2 擦除方法
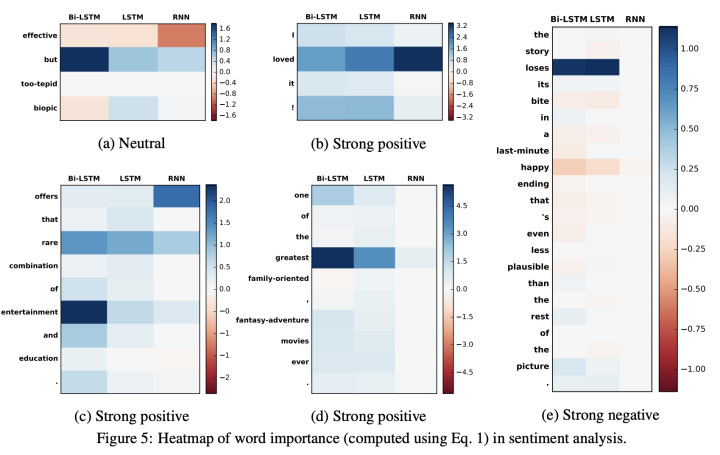
Jiwei Li等人,2017arxiv《Understanding neural networks through representation erasure》 PS:《Visualizing and understanding neural models in NLP》也是这个大佬写的。
这篇用擦除带来的结果变化反映要素的重要性,还做了最小反转预测的强化学习(略):
-
词级别擦除:
维度级别擦除(探究这些重要维度的值和词频的关系):
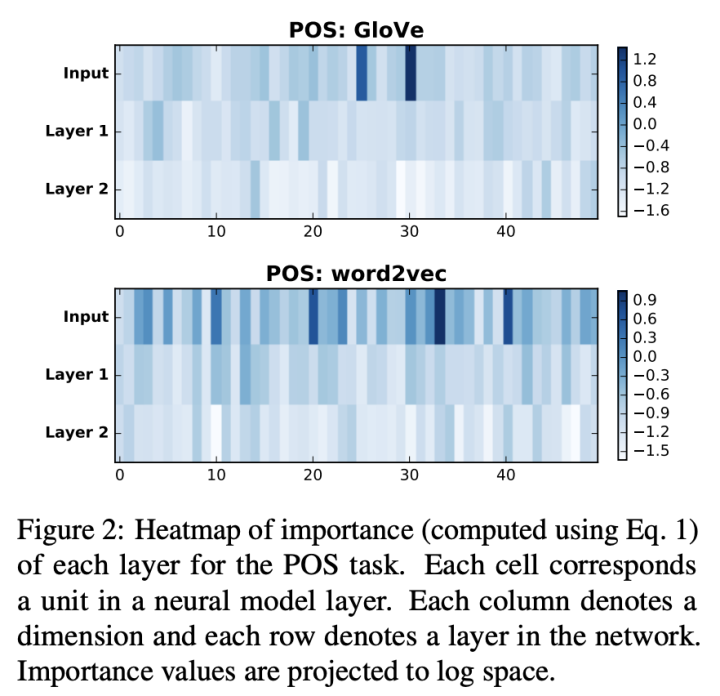
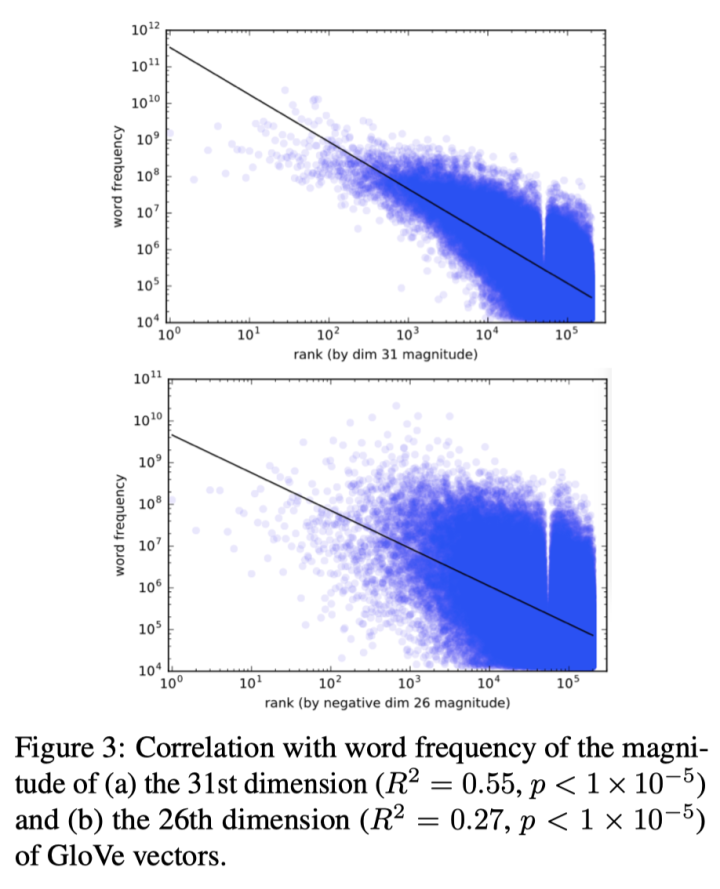
-
用擦除维度带来的平均结果变化表示维度的重要性: -
并计算显著的维度和词频的相关性,查看是否这些维度的数值绝对值大小和词频相关
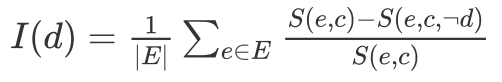
3. 注意力vs显著性:孰优孰劣?
现在论证为什么在解释上应该优先使用显著性方法。
在许多被引用的论文中,无论是暗含的还是明示的,解释的目的都是揭示哪些输入单词是最终预测中最重要的单词。这可能是注意力计算每个输入一个权重的结果,因此必须根据这些输入来理解它。
-
忠诚度:对于模型开发人员而言,忠诚度比合理度更重要。模型未必符合人们的直觉,而输入显著性方法则致力于正面解决目标:它们揭示了为什么要根据每个输入词与该预测的相关性做出一个特定的模型预测。 -
覆盖率:从输入词嵌入到目标输出预测值,输入显著性方法通常会考虑整个计算路径,而注意权重不是:注意权重在计算的某一点上反映了模型对每种输入表示的参与程度,但是这些表示可能已经混入了来自其他输入的信息。 -
高效性:有人可能会争辩说,注意力分散很容易就可以从模型提取出来,并且计算效率高。但是,在TensorFlow之类的框架中只需一行就可以计算输出相对输入的梯度,因此实现困难不是一个有力的论据。梯度方法等可解释方法和注意力同样高效!
最具有讽刺意味的是,有时解释性注意力是通过将其与基于梯度的度量进行比较来进行评估的,那么为什么我们不直接用这些显著性方法?

4. 注意力就这么一无是处吗?非也。
大棒下去,胡萝卜得跟上:注意力研究也是有价值的,只不过和可解释的关系不大。
纵观近年对注意力机制的研究,还是有许多有价值的工作涌现:
4.1 注意力机制的作用依然是重要的研究目标
-
Voita等在ACL2019发表的《Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned》分析注意力头的作用。 -
Michel在NIPS2019发表的《Are sixteen heads really better than one?》同样分析了注意力头在Transformer体系结构中的作用,并确定了他们具有的一些独特功能。 -
Strubell在EMNLP2018(还是Best Paper!)发表的《Linguistically-informed self-attention for semantic role labeling》通过增加语言学的偏见,训练注意力头执行依赖关系解析。
4.2 注意力可以为其他解释提供参考
如果调整了解释的定义,例如,明确表达了不同的预期用户和不同的解释目标,则注意力可能会成为某些应用程序的有用解释。
-
Strout等(ACL2019)证明,对于用户和目标而言,有监督的注意力比随机或无监督的注意力帮助人类更快地完成任务。——至少,可以给用户提供一种心理上的可靠性。
5. 那么,显著性就是终极的方法了吗?
既然你这么问了,答案一定是:没有最好,只有更好。
5.1 超越显著性方法之外
来自注意力的嘲讽:我虽然实力不如你,但长得比你好看啊!
注意力的可视化有很多工具,如下:
Vig在2019的《A Multiscale Visualization of Attention in the Transformer Model》提出的注意力可视化工具:

Hoover在2020ACL demo的《exBERT: A Visual Analysis Tool to Explore Learned Representations in Transformer Models》提出的exBERT工具:
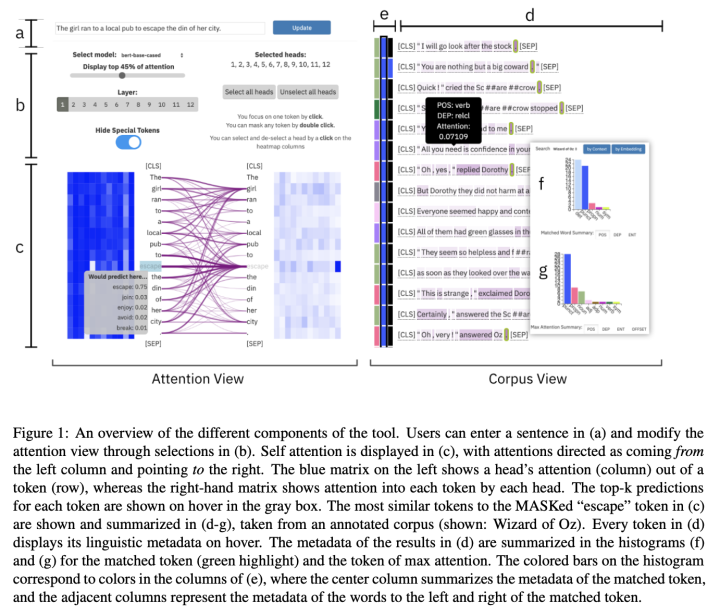
此外,显著性方法还有一些模型中间过程的表示能力缺陷:
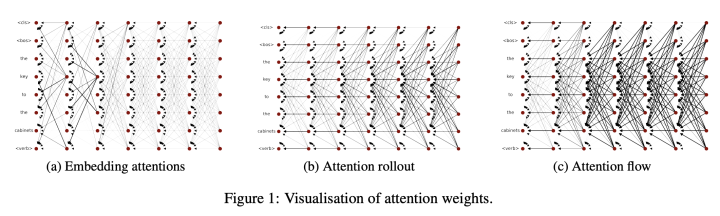
Abnar在2020《Quantifying attention flow in transformers》提出attention rollout和attention flow作为attention的近似,能更好地反映信息的流动:
于是有人提出了拓展的方法:
DeCao在EMNLP2020的《How do decisions emerge across layers in neural models? interpretation with differentiable masking》提出的DiffMask方法不仅揭示了模型知道哪些输入很重要,还揭示了重要信息在模型各层中的流动存储在哪一层:

5.2 显著性方法的局限性
显著性方法存在一些已知的问题,这里有一些非常有趣的结果。
首先是擦除方法的问题:
Hooker在NIPS2019的《A benchmark for interpretability methods in deep neural networks》提出,基于遮挡和擦除的方法以及基于擦除的评估的已知问题(Bach等,2015;DeYoung等,2020)是预测概率的变化可能是由于损坏的输入脱离训练数据的多样性——也就是说,概率的下降可以通过输入为OOD而不是由于缺少重要特征来解释。
其次是显著性方法对输入变化的脆弱性:
Kindersman的《The (un)reliability of saliency methods》(2017,挂在arxiv上没发表)提出显著性方法不满足输入不变性。
通过在输入中加入固定的向量(这部分不会对预测产生影响),梯度方法可能会带来归因错误的结果!仅仅把输入向量数值平移就可以让归因产生错误:
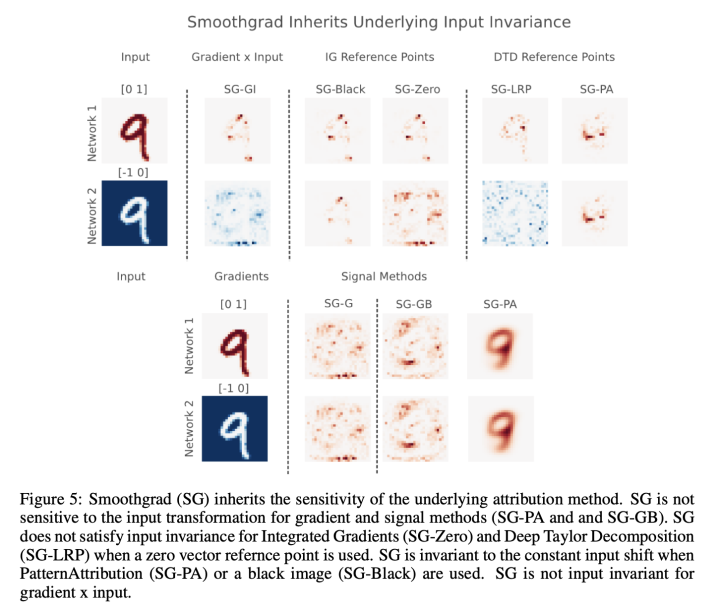
加个小猫试试:

最后,还有一个很大的限制:显著性方法的表达能力问题。
显然,基于token的显著性权重只能在非常狭义的意义上被称为解释。这里有一份积分梯度的拓展工作:
Janizek的《Explaining explanations: Axiomatic feature interactions for deep networks》(2020,挂在arxiv上没发表)拓展了IG到Integrated Hessians,通过指出重要特征之间的依赖关系,解释了成对特征的相互作用,可以克服重要性的平坦表示的某些局限性,但很难完全理解为什么深度非线性模型仅通过查看输入标记即可得出一定的预测。
6. 结论
本文总结了关于注意力是否是解释的辩论,并观察到解释的目的通常是确定哪些输入与预测最相关。输入显着性方法比注意力更具有忠实度,因而适合面向模型开发人员的解释。
笔者个人的一些结论:可解释方面目前还是以经验性的比较为主,缺少一个金标准;梯度的saliency map这一套在CV已经屡见不鲜了,但目前的解释水平还有待提高。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“AES” 就可以获取《【万字长文】注意力机制可解释大论述》专知下载链接






