TPAMI 2022 | 不同数据模态的人类动作识别综述,涵盖500篇文章精华
机器之心专栏
本文对最近被 TPAMI 接收的一篇综述文章 Human Action Recognition from Various Data Modalities: A Review(基于不同数据模态的人类动作识别综述)进行解读。


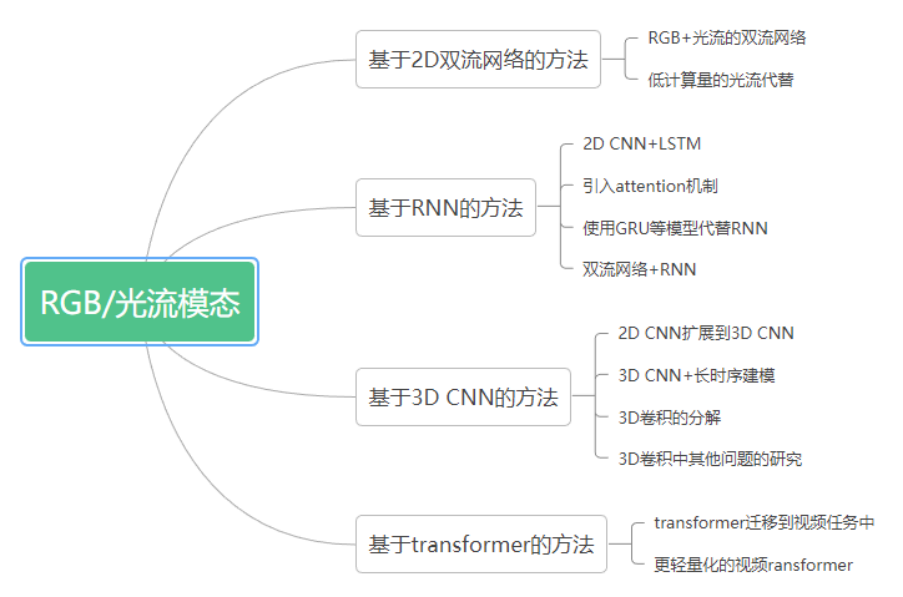
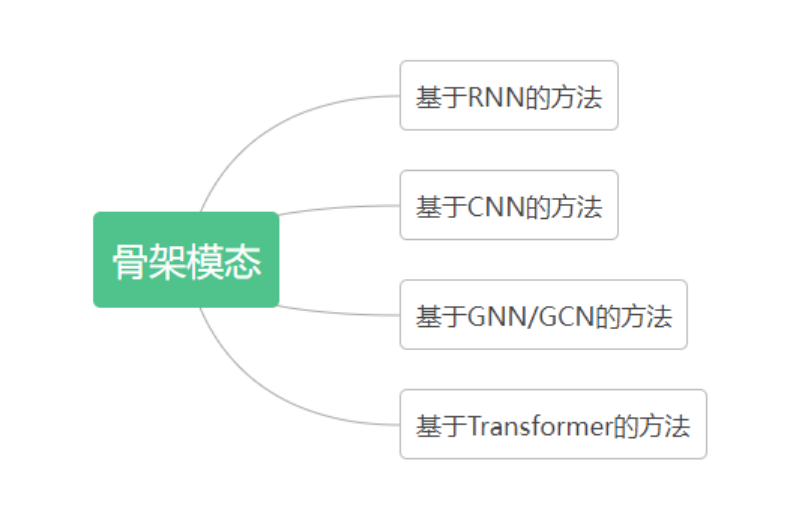
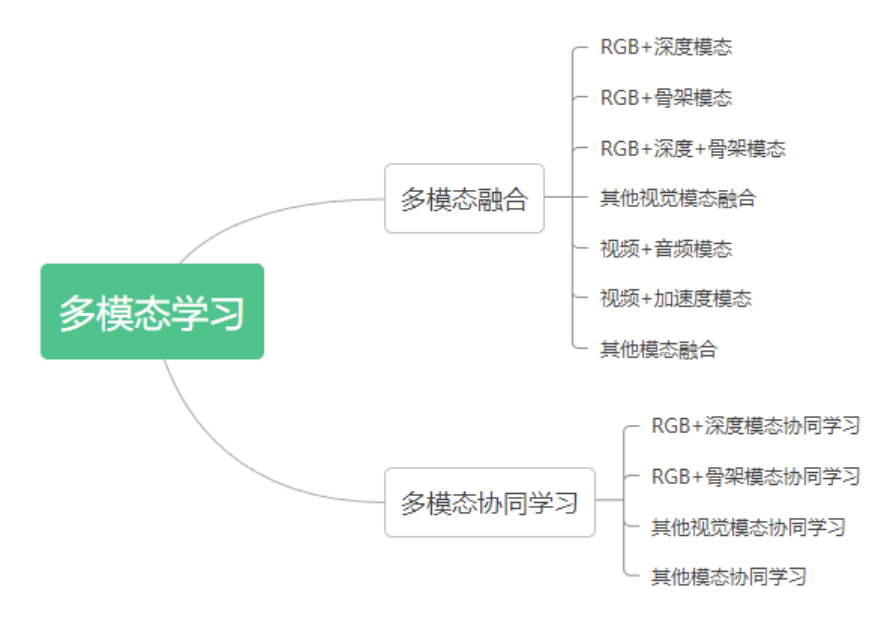
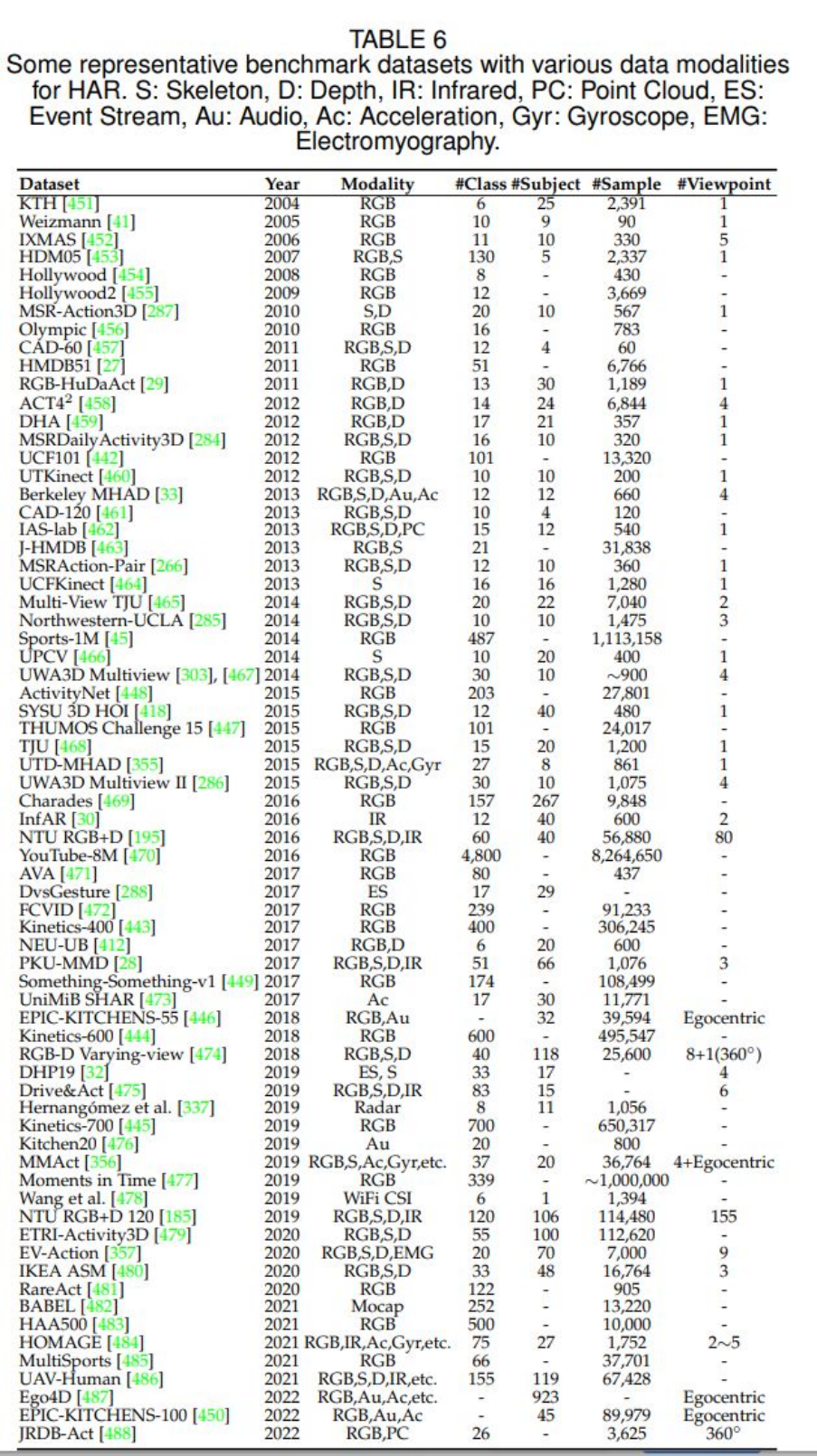
[1] K. Simonyan and A. Zisserman, "Two-stream convolutional networks for action recognition in videos," in Advances in Neural Information Processing Systems, vol. 27, 2014.
[2] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei, "Large-scale video classification with convolutional neural networks," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1725-1732.
[3] B. Zhang, L. Wang, Z. Wang, Y. Qiao, and H. Wang, "Real-time action recognition with enhanced motion vector cnns," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2718-2726.
[4] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell, "Long-term recurrent convolutional networks for visual recognition and description," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 2625-2624.
[5] S. Sharma, R. Kiros, and R. Salakhutdinov, "Action recognition using visual attention," arXiv preprint arXiv:1511.04119, 2015.
[6] Z. Wu, X. Wang, Y.-G. Jiang, H. Ye, and X. Xue, “Modeling spatial-temporal clues in a hybrid deep learning framework for video classification,” in Proceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 461-470.
[7] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, "Learning spatiotemporal features with 3d convolutional networks," in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 4489-4497.
[8] G. Varol, I. Laptev, and C. Schmid, "Long-term temporal convolutions for action recognition," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1510-1517, 2017.
[9] Z. Qiu, T. Yao, and T. Mei, "Learning spatio-temporal representation with pseudo-3d residual networks," in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 4489-4497.
[10] Y. Zhou, X. Sun, C. Luo, Z.-J. Zha, and W. Zeng, "Spatiotemporal fusion in 3d cnns: A probabilistic view," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 1725-1732.
[11] J. Kim, S. Cha, D. Wee, S. Bae, and J. Kim, "Regularization on spatio-temporally smoothed feature for action recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 12103-12112.
[12] ] G. Bertasius, H. Wang, and L. Torresani, "Is space-time attention all you need for video understanding?," in ICML, vol. 2, no. 3, 2021.
[13] Q. Fan, C.-F. Chen, and R. Panda, "Can an image classifier suffice for action recognition?," in International Conference on Learning Representations, 2022.
[14] D. Neimark, O. Bar, M. Zohar, and D. Asselmann, "Video transformer network," in Proceedings of the IEEE International Conference on Computer Vision, 2021, pp. 3163-3172.
[15] Y. Du, W. Wang, and L. Wang, "Hierarchical recurrent neural network for skeleton based action recognition," in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1110-1118.
[16] A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, "Ntu rgb+d: A large scale dataset for 3d human activity analysis," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1010-1019.
[17] Y. Hou, Z. Li, P. Wang, and W. Li, "Skeleton optical spectra-based action recognition using convolutional neural networks," IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 3, 2016.
[18] P. Wang, Z. Li, Y. Hou, and W. Li, "Action recognition based on joint trajectory maps using convolutional neural networks," in Proceedings of the 24th ACM international conference on Multimedia, 2016, pp. 102-106.
[19] L. Shi, Y. Zhang, J. Cheng, and H. Lu, "Skeleton-based action recognition with directed graph neural networks," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7912-7921.
[20] S. Yan, Y. Xiong, and D. Lin, "Spatial temporal graph convolutional networks for skeleton-based action recognition," in Thirty-second AAAI conference on artificial intelligence, 2018.
[21] Y. Zhang, B. Wu, W. Li, L. Duan, and C. Gan, "Stst: Spatial-temporal specialized transformer for skeleton-based action recognition," in Proceedings of the 29th ACM international conference on Multimedia, 2021, pp. 3229-3237.
[22] Y. Wang, Y. Xiao, F. Xiong, W. Jiang, Z. Cao, J. T. Zhou, and J. Yuan, "3dv: 3d dynamic voxel for action recognition in depth video," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 511-520.
[23] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, "Pointnet++: Deep hierarchical feature learning on point sets in a metric space," in Advances in Neural Information Processing Systems, vol. 30, 2017.
[24] X. Liu, M. Yan, and J. Bohg, "Meteornet: Deep learning on dynamic 3d point cloud sequences," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 9246-9255.
[25] J. Imran and P. Kumar, "Human action recognition using rgb-d sensor and deep convolutional neural networks," in 2016 international conference on advances in computing, communications and informatics (ICACCI), 2016, pp. 144-148.
[26] P. Wang, W. Li, J. Wan, P. Ogunbona, and X. Liu, "Cooperative training of deep aggregation networks for rgb-d action recognition," in Thirty-second AAAI conference on artificial intelligence, 2018.
[27] H. Wang, Z. Song, W. Li, and P. Wang, "A hybrid network for large-scale action recognition from rgb and depth modalities," Sensors, vol. 20, no. 11, 2020.
[28] R. Zhao, H. Ali, and P. Van der Smagt, "Two-stream rnn/cnn for action recognition in 3d videos," in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 4260-4267.
[29] M. Zolfaghari, G. L. Oliveira, N. Sedaghat, and T. Brox, "Chained multi-stream networks exploiting pose, motion, and appearance for action classification and detection," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 2904-2913.
[30] J. Liu, A. Shahroudy, D. Xu, A. C. Kot, and G. Wang, "Skeleton-based action recognition using spatio-temporal lstm network with trust gates," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 3007-3021, 2017.
[31] H. Rahmani and M. Bennamoun, "Learning action recognition model from depth and skeleton videos," in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5832-5841.
[32] S. S. Rani, G. A. Naidu, and V. U. Shree, "Kinematic joint descriptor and depth motion descriptor with convolutional neural networks for human action recognition," Materials Today, vol. 37, 3164-3173, 2021.
[33] A. Shahroudy, T.-T. Ng, Y. Gong, and G. Wang, "Deep multimodal feature analysis for action recognition in rgb+d videos," IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 5, pp. 1045-1058, 2017.
[34] J.-F. Hu, W.-S. Zheng, J. Pan, J. Lai, and J. Zhang, "Deep bilinear learning for rgb-d action recognition," in Proceedings of the European Conference on Computer Vision, 2018, pp. 5832-5841.
[35] P. Khaire, P. Kumar, and J. Imran, "Combining cnn streams of rgb-d and skeletal data for human activity recognition," Pattern Recognition Letters, vol. 115, pp. 107-116, 2018.
[36] S. Ardianto and H.-M. Hang, "Multi-view and multi-modal action recognition with learned fusion," in 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp. 1601-1604, 2018.
[37] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, "Temporal segment networks: Towards good practices for deep action recognition," in Proceedings of the European Conference on Computer Vision, 2016, pp. 20-36.
[38] C. Wang, H. Yang, and C. Meinel, "Exploring multimodal video representation for action recognition,"in 2016 International Joint Conference on Neural Networks (IJCNN), pp. 1924-1931, 2016.
[39] E. Kazakos, A. Nagrani, A. Zisserman, and D. Damen, "Epic-fusion: Audiovisual temporal binding for egocentric action recognition," in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 5492-5501.
[40] R. Gao, T.-H. Oh, K. Grauman, and L. Torresani, "Listen to look: Action recognition by previewing audio," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 10457-10467.
[41] N. Dawar and N. Kehtarnavaz, "A convolutional neural network-based sensor fusion system for monitoring transition movements in healthcare applications," in 2018 IEEE 14th International Conference on Control and Automation (ICCA), pp. 482-485, 2018.
[42] H. Wei, R. Jafari, and N. Kehtarnavaz, "Fusion of video and inertial sensing for deep learning–based human action recognition," Sensors, vol. 19, no. 17, 2019.
[43] A. Gorban, H. Idrees, Y.-G. Jiang, A. Roshan Zamir, I. Laptev, M. Shah, and R. Sukthankar, "THUMOS challenge: Action recognition with a large number of classes." http://www.thumos.info/, 2015.
[44] H. Akbari, L. Yuan, R. Qian, W.-H. Chuang, S.-F. Chang, Y. Cui, and B. Gong, "Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text,"in Advances in Neural Information Processing Systems, vol. 27, 2014.
[45] N. C. Garcia, P. Morerio, and V. Murino, "Modality distillation with multiple stream networks for action recognition," in Proceedings of the European Conference on Computer Vision, 2018, pp. 5832-5841.
[46] N. C. Garcia, P. Morerio, and V. Murino, "Learning with privileged information via adversarial discriminative modality distillation," IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 10, pp. 2581-2593, 2019.
[47] N. C. Garcia, S. A. Bargal, V. Ablavsky, P. Morerio, V. Murino, and S. Sclaroff, "Dmcl: Distillation multiple choice learning for multimodal action recognition," arXiv preprint arXiv:1912.10982, 2019.
[48] B. Mahasseni and S. Todorovic, "Regularizing long short term memory with 3d human-skeleton sequences for action recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3054-3062.
[49] . Wang, C. Gao, L. Yang, Y. Zhao, W. Zuo, and D. Meng, "Pm-gans: Discriminative representation learning for action recognition using partial-modalities," in Proceedings of the European Conference on Computer Vision, 2018, pp. 384-401.
[50] Y. Liu, K. Wang, G. Li, and L. Lin, "Semantics-aware adaptive knowledge distillation for sensor-to-vision action recognition," IEEE Transactions on Image Processing, vol. 30, pp. 5573-5588, 2021.
[51] H. Alwassel, D. Mahajan, L. Torresani, B. Ghanem, and D. Tran, "Self supervised learning by cross-modal audio-video clustering," arXiv preprint arXiv:1911.12667, 2019.
[52] B. Korbar, D. Tran, and L. Torresani, "Cooperative learning of audio and video models from self-supervised synchronization," in Advances in Neural Information Processing Systems, vol. 31, 2018.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
