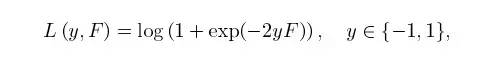
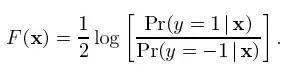

长按识别二维码享更多精彩
作为一家SaaS公司,有赞向商家提供强大的微商城系统和完整的移动电商解决方案。伴随着公司产品受众不断增长的同时,灰黑产业也慢慢伸出了触角,妄图利用有赞便捷的支付、传播等能力获取非法的利益,因此如何高效的遏制灰黑产业的侵蚀,是我们面临的一个重要挑战。总的来说,目前有赞面临的主要风险类型包括:
盗卡:盗用用户银行卡,在有赞店铺上消费
欺诈:通过发布低价商品,诱骗消费者购买
套现:在自己创建的店铺里进行虚假交易用以套现信用卡
垃圾信息:发布虚假消息、色情等违规商品、页面
盗账户:黑客用其他平台获取的账户密码通过撞库来非法盗取用户在赞平台的账户
以上所列各种违法、违规行为危害到正常商户以及买家利益,同时也会平台带来资损。在减少对正常用户打扰的前提下如何高效的对风险进行防控,是有赞风控的愿景和使命。
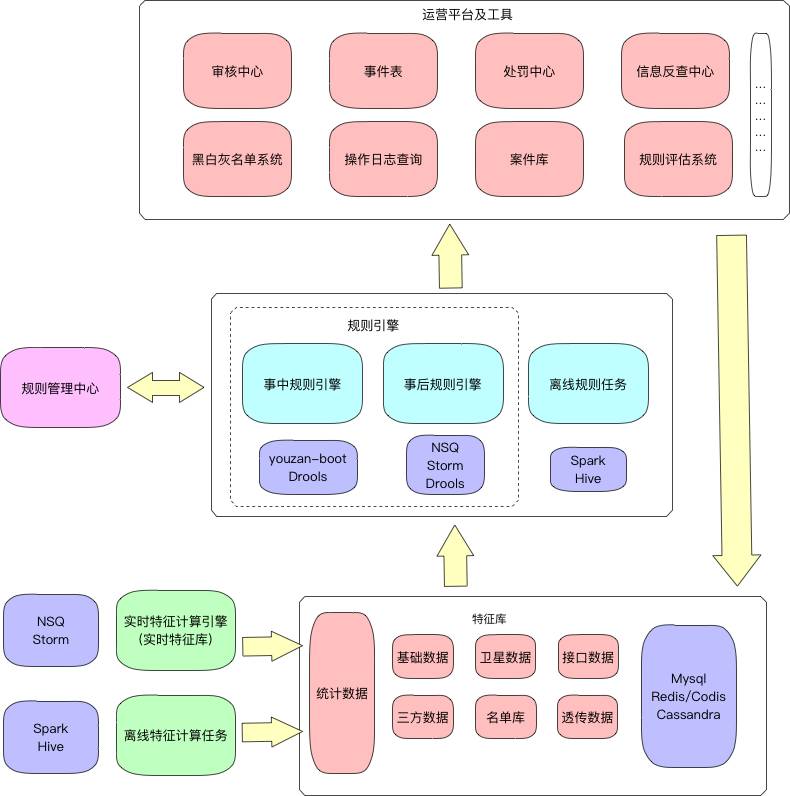
有赞风控架构
作为风控架构的“大脑”,规则引擎的运行依赖于其他系统的支撑,包括:
实时特征库
顾名思义,特征库为实时规则引擎提供必要的特征支持。举个例子,当一笔订单传入规则引擎时,我们不仅希望得到该笔订单对应的各种静态特征(谁何时在某地花费了多少代价做了什么),也希望得到该人累加交易情况,这样做出的判断才更有说服力,这里累加交易情况的任务主要由实时特征库来完成,我们的风控特征库主要采用Storm架构,通过接入NSQ消息,将消息内的各种特征进行剥离、汇总、统计,统一存入数据库及缓存中,为规则引擎提供实时统计数据。
规则管理中心
有赞风控规则管理中心是供运营配置线上规则的入口,并保持与规则引擎的定时同步,规则使用数据仓库组织,底层数据用数据库进行存储。通过规则管理中心,将开发人员从繁杂的规则编码中解放出来,只需要专心开发特征即可。
风控离线任务
风控离线任务分为离线规则任务、离线特征计算任务。离线规则任务主要运行离线规则以及满足运营的离线数据需求,离线特征计算任务提供规则引擎所需的深度定制特征(如用户评分、可信特征),主要计算框架为Hive/Spark。
运营平台及工具
包括审核中心、事件表、处罚中心、信息反查中心、黑白灰名单系统、操作日志查询、案件库、规则评估系统等。 风控是一项和业务结合特别紧密的工作,风控系统的好坏说到底需要业务指标来衡量。对整个风控系统而言,运营平台是最终的展示方,同时运营通过这些工具也为规则引擎提供了数据支撑,完成了风控系统的闭环。
风控系统架构图
有赞风控规则引擎
在规则引擎构建之初,我们考虑过多种规则引擎选型方案,包括自建规则引擎内核以满足自身业务的个性化需求,而后考虑到:
自建规则引擎对中小型公司并不适用,开发人员重复造轮子耗费大量的人力物力
部分开源的规则引擎内嵌了优化算法,保证了规则执行效率
部分开源的规则引擎有大量的社区及成功案例支持,可方便的对所遇到问题进行反馈
最终,我们选择了使用较为广泛的JBoss公司维护的Drools。
Drools是基于RETE算法的开源规则引擎,它具有性能高、可扩展性好、功能全等特点。有赞风控规则引擎基于Drools进行开发,将事件按业务风险类型进行分类,每类布控具体的规则、模型对风险进行防控。
天下武功,唯快不破,当发生一笔潜在案件时,如果不能在短时间内发现并处理,对于资金类案件来说,有资损的风险;对于信息类案件而言,有垃圾信息被大量曝光、损坏平台声誉的风险。有赞实时规则引擎分为事中和事后两类,其中事中引擎采用了有赞内部的统一接口框架youzan-boot,事后采用了Storm实时流处理框架。有赞风控规则引擎可在100ms内检测、拦截潜在的风险行为。
规则引擎代码示例:
// 反欺诈订单业务
String bizName = "antiCheat";
String bizModel = "order";
Order order = new Order();
order.setShopScore(86);
order.setOrderNo("E2017xxxxxxxxxx");
order.setPay(100L);
order.setPayTime("2017-01-01 00:00:00");
order.setPayPlace("浙江省杭州市");
// 获取已初始化的规则数据
KnowledgeBase kBase = LoadRuleBase.knowledgeBase;
FactType modelType = kBase.getFactType(bizName, bizModel);
// 新建无状态的会话
StatelessKnowledgeSession session = kBase.newStatelessKnowledgeSession();
// 会话中添加监听器
TrackingAgendaEventListener trackingAgendaEventListener = new TrackingAgendaEventListener();
session.addEventListener(trackingAgendaEventListener);
Object modelObj = null;
try {
// 将业务模型数据转化为相应的规则引擎模型数据
modelObj = order.bizMO2rMO(modelType);
// 执行规则
session.execute(modelObj);
} catch (Exception e) {
logger.error("Exception occurs, orderNo:{}, detail:{}", order.getOrderNo(), ExceptionUtil.getTrace(e));
}
// 获取激活规则信息
List<Activation> activations = trackingAgendaEventListener.getActivationList();
if (null != activations) {
for (Activation act : activations) {
String actRuleName = act.getRuleName();
logger.info("订单:{}, 激活规则:{}", order.getOrderNo(), actRuleName);
}
}
// 获取规则执行后,引擎的返回值
Integer actionCode = (Integer) modelType.get(modelObj, "action_code");
String actionReason = (String) modelType.get(modelObj, "action_reason");
String actionRes = "actionCode: " + String.valueOf(actionCode) + " actionReason: " + actionReason;
logger.info("订单:{}, 执行结果:{}", order.getOrderNo(), actionRes);
AntiCheatRiskDTO acrDTO = new AntiCheatRiskDTO();
acrDTO.setActionCode(actionCode);
acrDTO.setActionReason(actionReason);
return acrDTO;
其中,每个规则的执行后的返回值是由运营人员根据业务需求事先配置好的。需要说明的是,我们不需关心每个规则具体返回的结果,运营人员通过在规则管理中心调整规则的优先级及执行逻辑,最终返回的执行结果将是最符合业务逻辑的值。
除了会让具体的事件(登录、下单、支付、发布微页面等)过相应的规则外,有赞风控规则引擎还内嵌了一些与业务契合度较高的算法,如GBDT、FM、优化的Bayes等,作为规则的重要补充,这些算法训练出来的模型,可以抓取到规则未覆盖或难以覆盖的案件。
以GBDT为例,下面介绍下算法模型在有赞规则引擎中的使用方法。
GBDT(Gradient Boosting Decision Tree),是一种迭代的决策树模型,与传统的boost方法不同的是,它的每一次优化都是利用梯度下降方法往残差减少的方向进行。这里因为我们是二分类任务(例:判断一笔订单是有无欺诈嫌疑),因此我们采Friedman论文中的negative binomial log-likelihood作为损失函数:
其中,
并依次设置好残差、叶子节点值。
特征提取
要训练出高可用的模型,好的特征必不可少。好的特征的重要特点是区分度较高,这就需要算法开发人员和业务敏感度高的风控运营人员紧密配合,对配置的规则进行分析,提取出较好的规则因子,同时,算法开发人员还应对业务流程非常熟悉,发挥自己的想象力,结合实际情况,创造出高可用的特征。对实际业务而言,很多情况下,一个好的特征的加入比模型参数调优甚至模型优化更加有效,同时,好的特征还可以防止过拟合的发生。 将确定好的特征,利用Spark(出于性能方面考虑,主要采用Spark Sql导入到Hive中(对于如已知收货电话,需要求取收货电话归属地等需要二次加工的情况,采用PySpark对数据进行处理),将Hive表分区作为相应的版本号(方便对数据质量进行评估),作为单次训练样本。
模型训练
机器学习一个重要的需求就是样本的数量要尽可能的多,然而风控业务天然有这方面的缺陷,以交易为例,实际被风控的案例极少,这就导致正负样本数量极不平衡,因此我们采用重采样的方法增加正样本(有风险订单)的数量,具体方法是将样本包含的数值化特征采用SMOTE方法进行重采样,对标签化特征采用随机选择的方法重采样,最后将二者组合成新的样本。 实际训练过程中,需要对算法包含的最大迭代次数、步长、最大树深等参数进行多次适当的调节,选择出识别率最高的参数。这里,考虑到GBDT采用的boosting方法的进化能力较快,同时为维护性能,我们的数深在5-7层之间,最大迭代次数在5-10次之间。
规则引擎中运行代码示例:
GBDTTree[] gbdtTree = new GBDTTree[treeNum];
for (int i=0 ;i < treeNum; i++){
String treeString = treeStringList[i];
gbdtTree[i] = new GBDTTree();
gbdtTree[i].getGBDTTreeFromString(treeString);
}
// 传入字符型和分类型数据
order.setNumeric1(num1);
order.setNumeric2(num2);
order.setNumeric3(num3);
order.setCategoricalA(categoryA);
order.setCategoricalB(categoryB);
order.setCategoricalC(categoryC);
// 得到样本为正样本(可疑订单)的概率
float fValue = 0.0f;
for (int i = 0; i < treeNum; i++) {
float value = gbdtTree[i].getPredictValue(order);
fValue += learnRate * value;
}
float posRate = 1 / (1 + Math.exp(-2 * fValue));
// 超过预设阈值,上传至审核中心
if (posRate > GBDT_CHEAT_THRESHOLD) {
upLoad2ReviewCenter(order);
}
代码中,由于业务的敏感性,将具体特征名称隐去。
小结
基于Drools开发的有赞规则引擎,在Storm、Spark/Hive等流数据及分布式处理引擎的计算支撑下、多种算法模型的“法力加持下”,目前很好的满足了有赞的风控需求,但随着公司业务的增长,未来规则引擎的稳定性、性能、有效性也面临着更大的挑战,总体而言,后续还是会从规则引擎本身及算法模型两方面出发,在增强规则引擎框架的同时继续研究更多机器学习算法在风控业务上的作用。
参考
Drools
https://www.drools.org/
GBDT
https://statweb.stanford.edu/~jhf/ftp/trebst.pdf
SMOTE: Synthetic Minority Over-sampling Technique
https://www.jair.org/media/953/live-953-2037-jair.pdf
本文来自有赞技术团队博客 http://tech.youzan.com/rules-engine/
长按识别二维码享更多精彩



