解决强化学习反馈稀疏问题之HER方法原理及代码实现
来源: 转公众“小小挖掘机”
编辑:DeepRL
在强化学习中,反馈稀疏是一个比较常见同时令人头疼的问题。因为我们大部分情况下都无法得到有效的反馈,模型难以得到有效的学习。为了解决反馈稀疏的问题,一种常用的做法是为Agent增加一些内在的目标使反馈变的不再稀疏。
本文将介绍一种修改目标,使有效回报数量变多的方法。该方法称简称HER (paper地址):https://arxiv.org/abs/1707.01495v1。
1、问题背景
论文中使用Bit Flipping的例子来作为介绍。在该例子中,环境会初始化两个长度为N,由0和1组成的数组,其中一个为初始值,另一个是目标值。Agent在每一时刻可以选择反转其中的一个数字,将0变为1或者将1变为0。在一定步数T的限制下,当Agent操纵的数组和目标数组完全一致时,Agent会获得正向的反馈,其余情况下,会获得负向的反馈。该例子的示意图如下:

当数组长度为N时,该任务的状态,动作,奖励如下:
状态state:共有2^N种状态,每个状态的维度为N。
动作action:共有N中动作,代表反转的数字的index。
奖励reward:如果当前Agent控制的数组与目标数组不一致,即时奖励为-1。否则为0,同时游戏结束。
可以看出,该问题的正向反馈非常稀疏,而且随着数组的长度变长,反馈越来越稀疏。Agent需要很长的时间才能学习到最优策略。
既然问题出在反馈非常稀疏,那么我们增加反馈出现的频率不就可以了么?一种常见的思想是奖励塑形(Reward Shaping),比如根据人工的经验设计一些新的奖励。在这个例子中,可以用两个数组的平方距离来作为新的奖励,如果平方距离小,说明两个数组更接近,那么可以给一个高的奖励,反之可以给一个低的奖励。但是这种方法需要一定的专业知识,同时如果重塑不恰当,有可能会适得其反。
而本文提出的Hindsight Experience Replay方法,基于后见之明的思想。人类相较于代码中的Agent,有一个明显的长处就是在无法得到明确的反馈的情况下,依然可以积累一定的经验,而Agent却无法获得任何的收获。那么我们是否可以把这部分经验也告诉Agent呢?
回到我们的Bit Flipping中来,假设我们的初始状态时s0,目标状态时st,经过T轮的行动之后,得到的状态是sT。虽然sT不等于st,但是这部分经验是可以保留下来的,万一下次的目标状态是sT呢?
2、HER原理
HER的实现思路如下:

图中的重点是经验池Replay Buffer的构建,而模型本身可以选择任意off-policy的强化学习模型,如DQN、DDPG等。经验池的构造过程我们可以进行如下拆解:
(1)基于实际目标g采样完整序列
我们首先要采样M个完整的序列。对于任意一个序列,我们首先采样它的初始状态和目标状态,因为此时每个序列的目标是不同的,我们要根据不同的目标来选择动作,所以动作的采样同时基于当前的状态s和目标g:
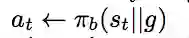
同时,基于状态s、动作a以及目标g来计算奖励r:
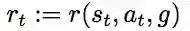
因此保存的每一条经验可以由五部分组成:当前状态s,采取的动作a,即时奖励r,下一个状态s',当前的目标g。
我们把这部分基于实际目标g采样得到的经验存放入经验池中。可以看到,这部分经验中的反馈大多都是负反馈。每一个完整的序列最多只有一条正反馈。
(2)通过变换目标得到新的经验
对于每一个序列,我们可以得到一些额外的经验,我们通过一些方法来得到一个新的目标g' 即下面的这一步:
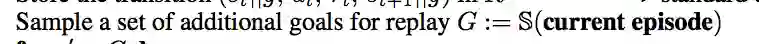
我们根据g',以及t时刻的状态s,t时刻的动作a,来计算新的奖励r':
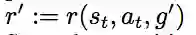
并将(st,at,r',st+1,g')存入我们的经验池中。
构造好我们的经验池之后,我们就可以通过一些强化学习算法来训练我们的Agent了。
(3)新目标的获取方法
我们主要有4种新目标的获取方式:
final — goal corresponding to the final state in each episode:把相应序列的最后时刻的状态作为新的目标goal
future — replay with k random states which come from the same episode as the transition being replayed and were observed after it:从该时刻起往后的同一序列中的状态,随机采样k个作为新的目标goal。
episode — replay with k random states coming from the same episode as the transition being replayed:对于同一序列中的状态,随机采样k个作为新的目标goal。
random — replay with k random states encountered so far in the whole training procedure:从全局出现过的state中,随机选择k个作为新的目标goal。
对于第一种方式,每一条原始经验可以得到一条新的经验,而对于后三种方式,每一条原始经验可以得到k条新的经验。
3、HER简单实现
好了,我们本文就来模拟实现一下文中提到的Bit Flipping问题。代码地址为:
https://github.com/princewen/tensorflow_practice/tree/master/RL/Basic-HER-Demo
RL的模型我们选择的是Double DQN。
3.1 环境搭建
我们首先来建立一个表示环境的类BitFlip,我们这里设计了两种reward的形式,一种是前文有提到过的奖励塑形的方式,即用两个序列的平方距离来代表reward;另一种就是稀疏的方式,如果两个序列相同,奖励0,否则奖励-1
class BitFlip():
def __init__(self, n, reward_type):
self.n = n # number of bits
self.reward_type = reward_type
def reset(self):
self.goal = np.random.randint(2, size=(self.n)) # a random sequence of 0's and 1's
self.state = np.random.randint(2, size=(self.n)) # another random sequence of 0's and 1's as initial state
return np.copy(self.state), np.copy(self.goal)
def step(self, action):
self.state[action] = 1-self.state[action] # flip this bit
done = np.array_equal(self.state, self.goal)
if self.reward_type == 'sparse':
reward = 0 if done else -1
else:
reward = -np.sum(np.square(self.state-self.goal))
return np.copy(self.state), reward, done
def render(self):
print("\rstate :", np.array_str(self.state), end=' '*10)
3.2 经验池类构建
我们这里的经验池中除了上文提到的五部分之外,还多了一个done表示是否结束,其实有没有都可以:
class Episode_experience():
def __init__(self):
self.memory = []
def add(self, state, action, reward, next_state, done, goal):
self.memory += [(state, action, reward, next_state, done, goal)]
def clear(self):
self.memory = []3.3 DDQN-Agent构建
接下来,我们创建一个DDQN的Agent。Double DQN中有eval-net和target-net,具体的细节我们就不介绍了,网络模型的构建过程如下:
def _set_model(self): # set value network
tf.reset_default_graph()
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, self.state_size], 'state')
self.tfs_ = tf.placeholder(tf.float32, [None, self.state_size], 'next_state')
self.tfg = tf.placeholder(tf.float32, [None, self.goal_size], 'goal')
self.tfa = tf.placeholder(tf.int32, [None, ], 'action')
self.tfr = tf.placeholder(tf.float32, [None, ], 'reward')
self.tfd = tf.placeholder(tf.float32, [None, ], 'done')
def _build_qnet(state, scope, trainable, reuse):
with tf.variable_scope(scope, reuse=reuse):
net = tf.layers.dense(tf.concat([state, self.tfg], axis=1), 256, activation=tf.nn.relu,
trainable=trainable)
q = tf.layers.dense(net, self.action_size, trainable=trainable)
return q, tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=scope)
self.q_eval, e_params = _build_qnet(self.tfs, 'eval', trainable=True, reuse=False)
self.q_targ, t_params = _build_qnet(self.tfs_, 'target', trainable=False, reuse=False)
self.update_op = [tf.assign(t, self.tau * e + (1 - self.tau) * t) for t, e in
zip(t_params, e_params)] # soft update
if self.use_double_dqn:
q_eval_next, _ = _build_qnet(self.tfs_, 'eval', trainable=True, reuse=True) # reuse the same eval net
q_eval_next_best_action = tf.argmax(q_eval_next, 1)
self.q_target_value = tf.reduce_sum(self.q_targ * tf.one_hot(q_eval_next_best_action, self.action_size),
axis=1)
else:
self.q_target_value = tf.reduce_max(self.q_targ, axis=1)
self.q_target_value = self.tfr + self.gamma * (1 - self.tfd) * self.q_target_value
if self.clip_target_value:
self.q_target_value = tf.clip_by_value(self.q_target_value, -1 / (1 - self.gamma), 0)
self.q_eval_action_value = tf.reduce_sum(self.q_eval * tf.one_hot(self.tfa, self.action_size), axis=1)
self.loss = tf.losses.mean_squared_error(self.q_target_value, self.q_eval_action_value)
self.train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(self.loss)
self.saver = tf.train.Saver()
self.sess.run(tf.global_variables_initializer())
接下来,要实现一个选择动作的函数,在Q-learning中,一般是通过e-greedy的策略进行动作选择的,目的是增加Agent的探索能力。
def choose_action(self, state, goal):
if np.random.rand() <= self.epsilon:
return np.random.randint(self.action_size)
act_values = self.sess.run(self.q_eval, {self.tfs: state, self.tfg: goal})
return np.argmax(act_values[0]) # use tf.argmax is much slower, so use np我们的DDQN的Agent也有存储经验的功能,我们把经验池中的经验喂给Agent:
def remember(self, ep_experience):
self.memory += ep_experience.memory
if len(self.memory) > self.buffer_size:
self.memory = self.memory[-self.buffer_size:] # empty the first memories随后,是模型进行学习的代码,每次从Agent的经验池中选择一个batch的经验进行学习,并更新eval-net的参数:
def replay(self, optimization_steps):
if len(self.memory) < self.batch_size: # if there's no enough transitions, do nothing
return 0
losses = 0
for _ in range(optimization_steps):
minibatch = np.vstack(random.sample(self.memory, self.batch_size))
ss = np.vstack(minibatch[:, 0])
acs = minibatch[:, 1]
rs = minibatch[:, 2]
nss = np.vstack(minibatch[:, 3])
ds = minibatch[:, 4]
gs = np.vstack(minibatch[:, 5])
loss, _ = self.sess.run([self.loss, self.train_op],
{self.tfs: ss, self.tfg: gs, self.tfa: acs,
self.tfr: rs, self.tfs_: nss, self.tfd: ds})
losses += loss
return losses / optimization_steps # return mean loss
最后,我们需要实现一个函数,用于将eval-net的参数复制给target-net:
def update_target_net(self, decay=True):
self.sess.run(self.update_op)
if decay:
self.epsilon = max(self.epsilon * self.epsilon_decay, self.epsilon_min)这里使用的是soft-replace:
self.update_op = [tf.assign(t, self.tau * e + (1 - self.tau) * t) for t, e in zip(t_params, e_params)] # soft update3.4 经验池构建
这一步是往经验池类中注入经验。我们首先创建两个经验池类,一个是使用原始目标得到的经验,另一个是HindSIght的经验:
ep_experience = Episode_experience()
ep_experience_her = Episode_experience()原始的经验构造很简单,从一个初始的状态开始,让我们的agent根据当前的state和目标goal选择动作action,并由环境给出奖励以及下一时刻的next_state:
for t in range(size):
action = agent.choose_action([state], [goal])
next_state, reward, done = env.step(action)
ep_experience.add(state, action, reward, next_state, done, goal)
state = next_state
if done:接下来,我们就要通过变换目标的方式来得到新的经验,这里采取的方式是future。假设当前的时刻为t,我们从t+1到T中采样k个时刻,把该时刻的state作为新的goal,并计算新的reward。
if use_her: # The strategy can be changed here
# goal = state # HER, with substituted goal=final_state
for t in range(len(ep_experience.memory)):
for k in range(K):
future = np.random.randint(t, len(ep_experience.memory))
goal = ep_experience.memory[future][3] # next_state of future
state = ep_experience.memory[t][0]
action = ep_experience.memory[t][1]
next_state = ep_experience.memory[t][3]
done = np.array_equal(next_state, goal)
reward = 0 if done else -1
ep_experience_her.add(state, action, reward, next_state, done, goal)3.5 模型训练
接下来,我们把两部分的经验喂给Agent,然后Agent就可以通过学习来更新自己的策略了。
agent.remember(ep_experience)
agent.remember(ep_experience_her)
ep_experience.clear()
ep_experience_her.clear()
mean_loss = agent.replay(optimization_steps)
agent.update_target_net()参考文献
1、原文:https://arxiv.org/abs/1707.01495v1
2、《强化学习精要:核心算法与Tensorflow实现》
关于小小挖掘机公众:
小小挖掘机在推荐系统有非常多的文章,涉及了机器学习、深度学习和强化学习,转载和学习请查看该公众号(wALsjwj)

深度强化学习实验室
算法、框架、资料、前沿信息等
长按二维码关注我们吧
GitHub仓库
https://github.com/NeuronDance/DeepRL
欢迎Fork,Star,Pull Request

微信交流群助手:
NeuronDance



