如何用技术搞好英俄翻译?

阿里妹导读:俄语站是AliExpress最大的国家分站,每天有大量的商品信息需要由英文翻译成俄文,英俄翻译的质量直接影响俄罗斯本地买家的体验。俄语是一种形态非常丰富的语言,同一个意思的俄文单词根据其所在语境不同,往往会有十几种形态变化,这给英俄翻译带来了很大挑战。阿里巴巴翻译团队的工作将词尾预测机制成功应用在基于神经网络的翻译模型中,非常有效地缓解了这一问题。
作者:宋楷/Kai Song(阿里巴巴), 张岳/Yue Zhang(新加坡科技设计大学), 张民/Min Zhang (苏州大学), 骆卫华/Weihua Luo(阿里巴巴)
会议:AAAI-18
摘要
神经网络翻译模型受限于其可以使用的词表大小,经常会遇到词表无法覆盖源端和目标端单词的情况,特别是当处理形态丰富的语言(例如俄语、西班牙语等)的时候,词表对全部语料的覆盖度往往不够,这就导致很多“未登录词”的产生,严重影响翻译质量。
已有的工作主要关注在如何调整翻译粒度以及扩展词表大小两个维度上,这些工作可以减少“未登录词”的产生,但是语言本身的形态问题并没有被真正研究和专门解决过。
我们的工作提出了一种创新的方法,不仅能够通过控制翻译粒度来减少数据稀疏,进而减少“未登录词”,还可以通过一个有效的词尾预测机制,大大降低目标端俄语译文的形态错误,提高英俄翻译质量。通过和多个比较有影响力的已有工作(基于subword和character的方法)对比,在5000万量级的超大规模的数据集上,我们的方法可以成功地在基于RNN和Transformer两种主流的神经网络翻译模型上得到稳定的提升。
研究背景
近年来,神经网络机器翻译(Neural Machine Translation, NMT)在很多语种和场景上表现出了明显优于统计机器翻译(Statistic Machine Translation, SMT)的效果。神经网络机器翻译将源语言句子编码(encode)到一个隐状态(hidden state),再从这个隐状态开始解码(decode),逐个生成目标语言的译文词。NMT系统会在目标端设置一个固定大小的词表,解码阶段的每一步中,会从这个固定大小的词表中预测产生一个词,作为当前步骤的译文词。受限于计算机的硬件资源限制,这个词表往往不会设的很大(一般是3万-5万)。
并且随着词表的增大,预测的难度也会相应地增加。基于词(word)的NMT系统经常会遭遇“未登录词”(Out of vocabulary, OOV)的问题,特别是目标端是一个形态丰富(Morphologically Rich)的语言时,这个问题会更加严重。以“英-俄”翻译为例,俄语是一种形态非常丰富的语言,一个3-5万的词表往往不能覆盖俄语端的所有词,会有很多OOV产生。OOV的出现对翻译质量的影响是比较大的。
针对这个问题,有很多方法尝试解决。其中一些方法会从翻译粒度的角度出发(translation granularity),另外还有一些方法尝试有效地扩展目标端词表大小。这些方法虽然能有效地减少OOV,但是这些方法并没有对目标端语言的形态(morphology)进行专门的建模。
对于俄语这种形态丰富的语言,词干(stem)的个数会比词的个数少很多,因此很自然的,我们会想到要对词干和词尾(suffix)分别进行建模。我们设计实现了一种方法,在解码时每一个解码步骤(decoding step)中,分别预测词干和词尾。训练阶段,目标语言端会使用两个序列,分别是词干序列和词尾序列。词干序列和词尾序列的生成过程如下图所示:
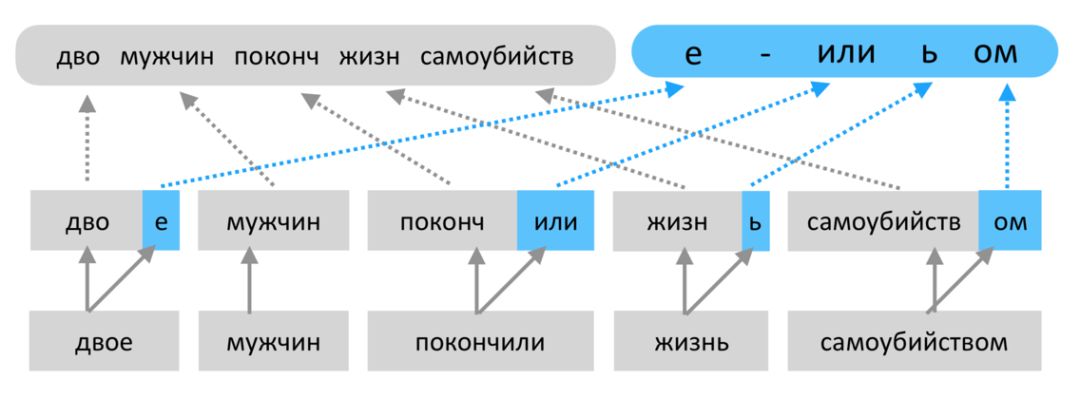
(词干序列和词尾序列的生成,“N”表示词干和词本身相同,即这个词没有词尾)
通过这种方式,数据稀疏问题会得到缓解,因为词干的种类会显著小于词的种类,而词尾的种类只有几百种。
相关工作
基于子词(subword)的和基于字符(character)的这两种方法,从调整翻译粒度的角度出发来帮助缓解目标端形态丰富语言的翻译问题。一种基于子词的方法利用BPE(Byte Pari Encoding)算法来生成一个词汇表。语料中经常出现的词会被保留在词汇表中,其他的不太常见的词则会被拆分成一些子词。由于少数量的子词就可以拼成全部不常见的词,因此NMT的词表中只保留常见词和这些子词就可以了。
还有一种基于字符的NMT系统,源端句子和目标端句子都会表示为字符的序列,这种系统对源端形态丰富的语言可以处理得比较好,并且通过在源端引入卷积神经网络(convolutional neural network, CNN),远距离的依赖也可以被建模。上述两种方式虽然可以缓解数据稀疏,但是并没有专门对语言的形态进行建模,子词和字符并不是一个完整的语言学单元(unit)。
还有一些研究工作是从如何有效地扩大目标端词汇表出发的,例如在目标端设置一个很大的词汇表,但是每次训练的过程中,只在一个子表上进行预测,这个子表中包含了所有可能出现的译文词。这种方法虽然可以解决未登录词的问题,但是数据稀疏问题仍然存在,因为低频的词是未被充分训练的。
神经网络机器翻译
本文在两种主要的神经网络翻译系统上验证了“基于词尾预测”的方法的有效性,分别是基于递归神经网络的机器翻译(Recurrent Neural Network Based, RNN-based)和谷歌在17年提出的最新的神经网络翻译模型(Transformer),详细介绍可以查看相应论文。RNN-based神经网络机器翻译如下图:
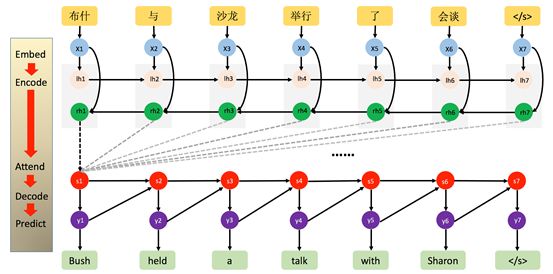
(“NeuralMachine Translation by Jointly Learning to Align and Translate”, Bahdanau etal., 2015)
Transformer的结构如下图:
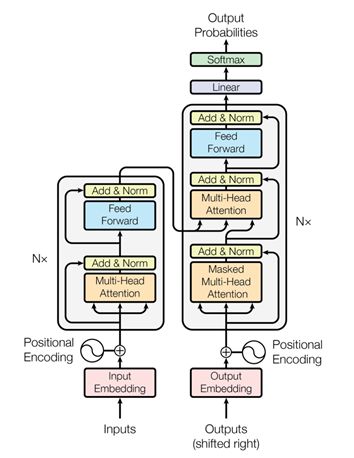
(“AttentionIs All You Need”, Ashish Vaswani et al., 2017)
俄语的词干和词尾
俄语是一种形态丰富的语言,单复数(number)、格(case)、阴阳性(gender)都会影响词的形态。以名词“ball”为例,“ball”是一个中性词,因此不会随阴阳性的变化而变化,但当单复数、格变化时,会产生如下多种形态:
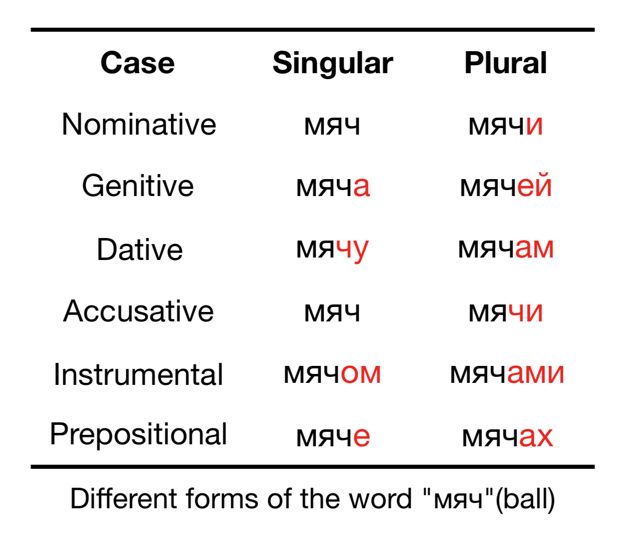
一个俄语词可以分为两部分,即词干和词尾,词尾的变化是俄语形态变化的体现,词尾可以体现俄语的单复数、格、阴阳性等信息。利用一个基于规则的俄语词干获取工具,可以得到一个俄语句子中每一个词的词干和词尾。
词尾预测网络
在NMT的解码阶段,每一个解码步骤分别预测词干和词尾。词干的生成和NMT原有的网络结构一致。额外的,利用当前step生成的词干、当前decoder端的hidden state和源端的source context信息,通过一个前馈神经网络(Feedforwardneural network)生成当前step的词尾。网络结构如下图:
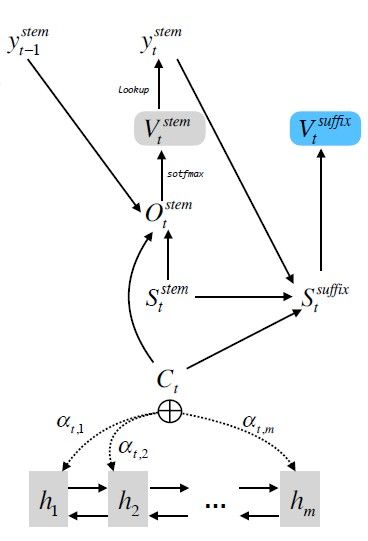
最后,将生成的词干和词尾拼接在一起,就是当前step的译文单词。
实验
我们在RNN和Transformer上都进行了实验,在WMT-2017英俄新闻翻译任务的部分训练语料(约530万)上,效果如下图:

其中,Subword是使用基于子词方法作为baseline,Fully Character-based是使用基于字符的NMT系统作为baseline。“SuffixPrediction”是我们的系统。
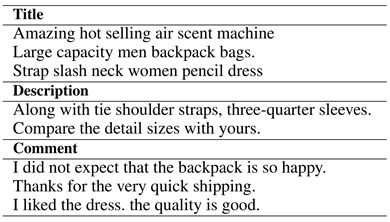
另外,我们还在电子商务领域的数据上,使用超大规模的语料(5000万),证明了该方法的有效性,实验结果如图:

测试集包括商品的标题(Title)、详情(Description)和用户评论(Comment)内容,示例如下:
一些翻译结果的例子:

第一个例子中,标号为1和2的俄语词的形态代表着这个词是一个反身动词(reflexive verb),反身动词的直接宾语和主语是同一个事物,换句话说,反身动词的施事者和受事者是同一个事物。从源端句子中可以看出,“return”的施事者是购买商品的人,受事者是某个要退还的商品,因此1和2的译文词是错误的。3的译文词是正确的,它的词尾代表着它是一个不定式动词(infinitive verb),这个不定式动词是可以有宾语的。在第二个例子中,标号1和2代表复数形式,4代表单数。第三个例子中,3代表过去时,1和2代表现在时。上面的例子中,相比于基于子词和基于字符的模型,我们的模型可以产生更正确的俄语形态。
总结
我们提出了一种简单、有效的方法来提高目标端是形态丰富语言(例如“英-俄”)的NMT系统的翻译质量。在解码阶段的每一个步骤中,首先生成词干,然后生成词尾。我们在两种NMT模型(RNN-based NMT和Transformer)上,和基于子词(subword)和字符(character)的方法进行了对比,证明了方法的有效性。我们使用了大规模(530万)和超大规模(5000万)的语料,在新闻和电子商务两个领域上进一步这种方法可以带来稳定的提升。在我们的工作中,词尾在NMT中首次被专门地建模。

你可能还喜欢
点击下方图片即可阅读




关注「阿里技术」
把握前沿技术脉搏



