让特征感受野更灵活,腾讯优图提出非对称卡通人脸检测,推理速度仅50ms
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

该文是腾讯优图&东南大学联合提出一种的非对称卡通人脸检测算法,该方法取得了
2020 iCartoon Face Challenge(Under 200MB)竞赛的冠军,推理速度仅为50ms且无需任何预训练模型。该文包含不少的trick,是检测领域不错的文章,推荐大家了解一下。
Abstract
由于诸多复杂场景导致卡通人脸检测比常规人脸检测更具挑战性,针对卡通人脸特性(huge difference within intra-face),该文提出一种非对称卡通人脸检测算法,称之为ACFD。 所提方法包含这样几个模块:(1)一种新颖的骨干网络VoVNetV3,该骨干网络有多个非对称汇聚模块(AOSA)构成;(2)非对称双向特征金字塔网络(ABi-FPN);(3) 动态锚点匹配策略(DAM);(4)边界二值分类损失(MBC)。
特别的,为生成具有灵活感受野的特征,采用VoVNetV3提取多尺度金字塔特征,然后采用ABi-FPN同时进行融合与增强以处理极限姿态的人脸。除此之外,采用DAM对每个人脸匹配充足的高质量锚点,并采用MBC提升强判别性能。
基于上述模块的有效性,所提方法ACFD取得了2020 iCartoon Face Challenge(Under 200MB)竞赛的冠军,推理速度仅为50ms且无需任何预训练模型。
该文主要有这样几点贡献:
-
提出一种新颖的骨干网络VoVNetV3; -
提出一种ABi-FPN同时进行多尺度特征融合与语义信息增强; -
提出DAM策略匹配高质量锚点; -
提出MBC模块提升卡通人脸判别能力 -
所提方法取得了2020 iCartoon Face Challenge竞赛检测赛道冠军。
Method
下图给出了所提ACFD的网络架构图,它采用VoVNetV3-51作为骨干网络(包含6个阶段生stride=4到128的特征),然后采用ABi-FPN进行多尺度特征融合与增强,最后采用锚点Head网络输出稠密预测。
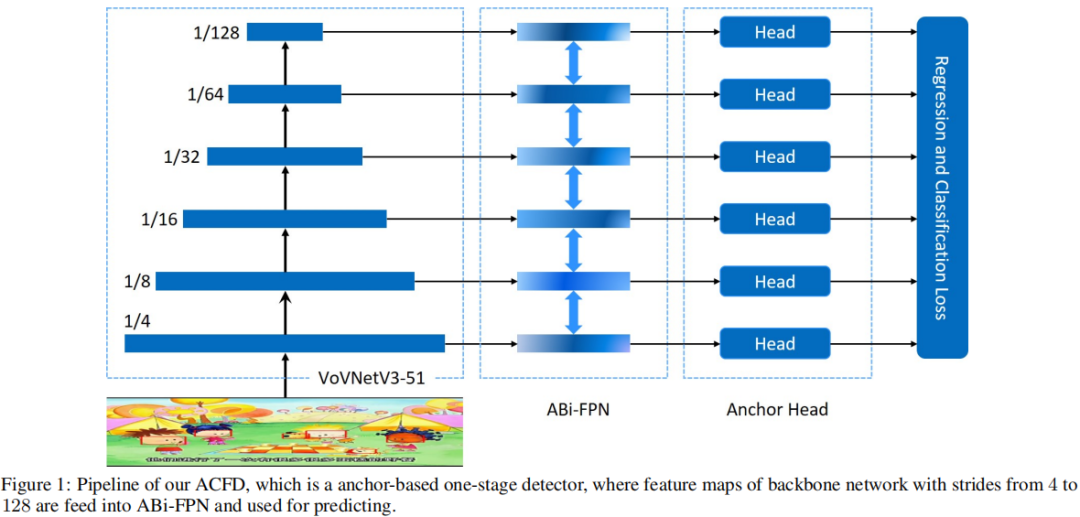
VoVNetV3
VoVNet是一种计算高效的骨干网络,其OSA模块可以输出灵活的特征表达;VoVNetV2通过添加残差连接方式解决了VoVNet训练的局限性,同时引入一种高效的注意力机制(eSE)。为进一步提升特征的灵活性,作者提出了一种更有效的骨干网络VoVNetV3,其核心模块如下所示。
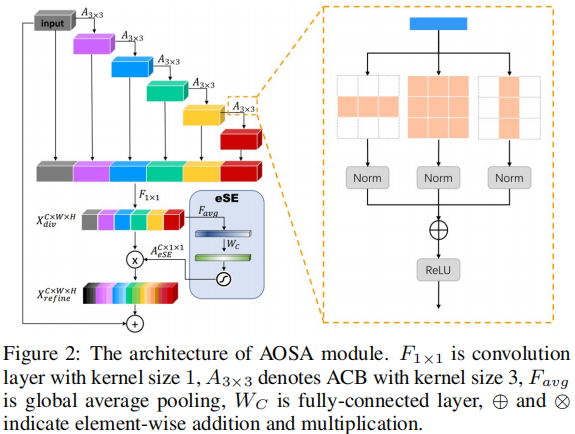
VoVNet与VoVNetV2的OSA模块采用了不同于DenseNet的稠密连接方式,而是采用相对稀疏连接的方式生成特征,每个特征与前接卷积特征相连从而生成更大感受野的特征,最后将所有特征进行一次Concat融合。可以看到:OSA模块可以生成更丰富感受野的特征。然而OSA仅仅处理方框感受野,这种处理方式可能会影响不同角度的人脸检测性能。受启发于ACNet,作者提出了一种非对称OSA模块,称之为AOSA,见上图右。
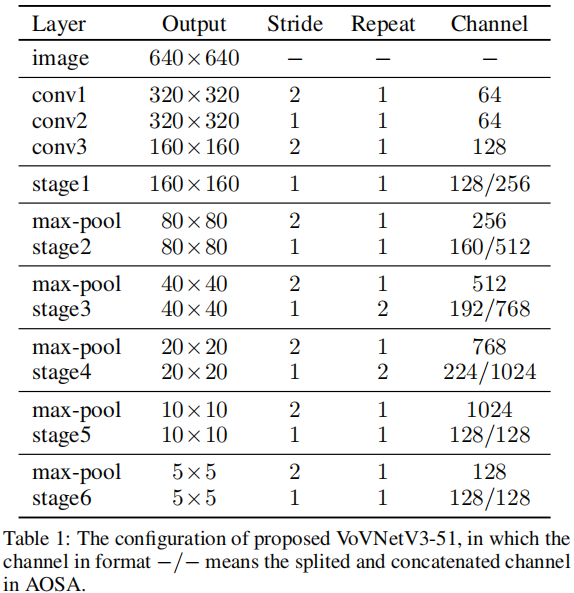
作者采用所提AOSA模块构建VoVNetV3-51骨干网络,网络结构信息见下表。
ABi-FPN
目前,大多人脸检测器采用ResNet或VGG提取多尺度特征,然而它们仅仅可以处理方框感受野的,这可能会影响极限角度的人脸检测。而卡通人脸中大约有10%的比例大于2.0或小于0.5.
为解决上述局限问题,PyramidBox、DSFD、RefineFace等在特征融合模块之后添加了一个额外的模块进行感受野进行精炼处理(尽管有效果但是低效率)。不同于前述方法,该文提出一种有效且高效的ABi-FPN模块同时进行特征融合、语义信息增强以及感受野精炼处理。采用ACB模块替换Bi-FPN中的卷积即可得到所提出的ABi-FPN模块,它可以使得特征感受野更灵活。
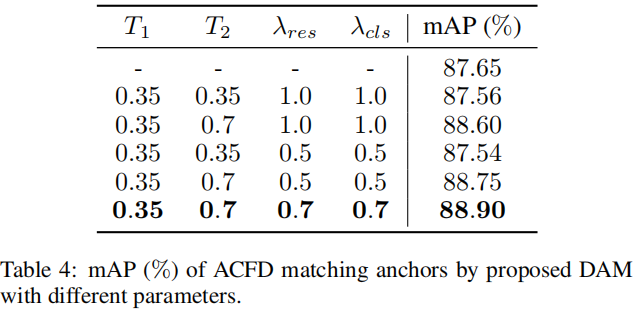
Dynamic Anchor Match

HamBox发现一个有趣的现象:某些不匹配的锚点具有非常强的回归能力,见上图b。具有强回归能力的锚点将得到一个具有大IoU得分的边界框(尽管它本身的IoU非常小)。
受上述现象启发,作者提出一种DAM策略以充分利用这些具有强回归能力的锚点,从而更好的为每个GT人脸匹配充足的高质量锚点。首先,IoU得分大于阈值的锚点被设置为正;然后,如果对应回归框的IoU得分大于阈值将被补偿为正。算法细节如下,挺有意思的一种处理策略。

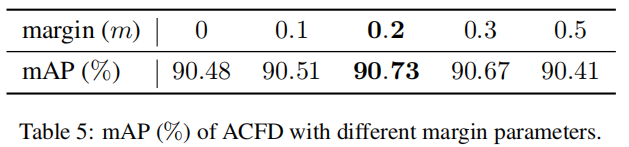
Margin Binary Classification Loss
正如前面所提到的,DAM可以为每个人脸匹配充足的高质量锚点,然而这些高质量锚点可能距离GT人脸比较远,从而影响训练过程中的损失。为此,作者提出在第一步分开计算匹配锚点损失权值,并在第二部对高质量锚点进行补偿,其中回归与分类损失定义如下:
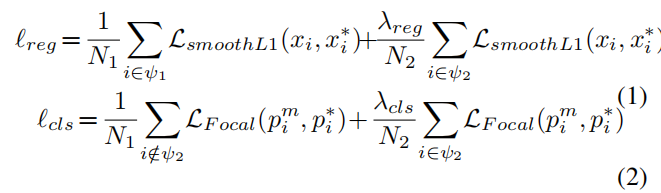
其中 分别表示匹配锚点 与补充锚点 的数量, 表示对应的加权系数。
为提出网络的分类性能(即判别哪些人脸与背景相似),作者将人脸识别领域常用的边界损失(通过添加额外硬边界约束促使最大化类间差异,最小化类内差异)引入到人脸检测领域。在边界二分类应用中,假设 表示网络的输出,那么边界预测可以定义如下:
其中 表示对应的one-hot标签,m表示硬边界约束, 用于计算分类损失。
Experimetns
在训练数据方面,作者将50000张iCartoon Face图像分为45000用于训练5000用于测试。在最后的竞赛提交阶段,所有模型均用于训练。
在数据增广方面,作者采用了:
-
color distort for training images,
-
expand the images with a random range [1*,* 4] by mean-padding to augment the small faces
-
crop the images with a random size at a random position to augment the big faces
-
random tile the faces to anchor scales, finally, resize the images to 640×640 for feeding into the network.
在锚点设置方面,每个检测层一个锚点且尺度为4,比例为1:1.因此总计有34125个锚点,且可以覆盖16-512大小的人脸。
在训练方面,模型采用kaiming方式进行初始化,优化器为SGD,momentum=0.9,权值衰减因子为 ,batch=64,同时采用warmup策略。在200、250、280epoch进行学习率x0.1,合计训练300epoch。
其他超参数,动态锚点匹配参数 ,加权系数为 ,分类损失中的边界参数为0.2.
在推理阶段,采用了多尺度( )方式提交测试。先看看效果再说。
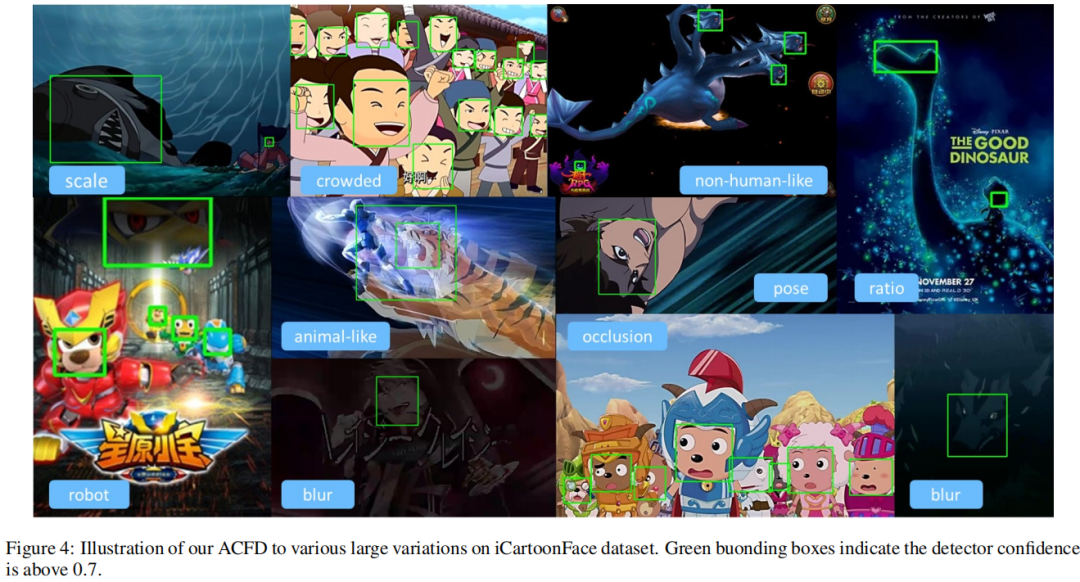
首先,给出了不同骨干网络下的模型性能对比,见下表。所提方法VoVNetV3-51取得了最佳得分。

然后,给出了ResNet50作为骨干网络时不同Head的性能,ABi-FPN获胜。

其次,给出了DAM的消融实验结果。可以看到:DAM以1.3%的指标高于baseline。
与此同时,给出了MBC分类损失的消融实验结果。
最后,作者给出了卡通人脸检测方案一步步改进对比表。而最终参赛的模型取得了92.91%的指标,高居榜首。

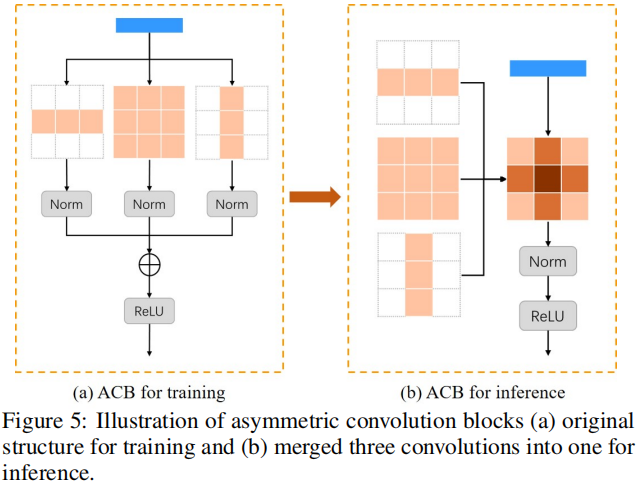
最后的最后,作者还提供了算法的推理耗时优化(竞赛要求推理耗时不超过50ms,而前述模型肯定是超过了)。首先,进行ACB的合并,下图给出了ACB的合并示意图;然后,进行Conv与BatchNorm的合并;最后,采用torch2rt工具将Pytorch模型转为TensorRT加速。
Conclusion
为解决卡通人脸检测困难问题,作者提出了一种新颖的非对称卡通人脸检测器ACFD。ACFD包含(1)一个新提出的VoVNetV3骨干网络用于提取多尺度特征;(2)一种ABi-FPN模块同时进行特征融合与增强;(3)一种动态锚点匹配策略;(4)引入边界二值分类损失进一步增强网络的判别能力。
该文最核心的创新可能是DAM与MBC两块,而VoVNetV3则是VoVNetV2与ACNet的组合,ABi-FPN则是Bi-FPN与ACNet的组合。但不管怎么说,能夺冠的方法就是好方法。
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




