“照骗”难逃Adobe的火眼金睛——用机器学习让P图无所遁形

译者 | shawn
编辑 | 姗姗
出品 | 人工智能头条 (公众号ID:AI_Thinker)
【导读】下图是 2008 年伊朗政府发布的一张图片,然而强大的网友们却凭借着肉眼,看出来图中黄色圈出的部分和红色圈出的部分是一模一样的,不得不说网友们真的是火眼金睛。而在今年的 CVPR 计算机视觉大会, Adobe 展示了他们最新的研究,旨在利用机器学习识别经过处理过的图像。这篇研究论文在业内虽然谈不上什么突破性,而且也还没有转化为商业化产品,但是看到作为图像编辑软件龙头老大的 Adobe 进行这样的研究,着实是一件有趣的事。今天人工智能头条就为大家介绍一下这个有趣的工作!

▌前言
世界各地的专家越来越担心新的 AI 工具的出现让图片和视频编辑越来越容易,尤其是一些令人震惊的内容在社交媒体上未经查实就可以被迅速传播。 Adobe 就是此类 AI 工具中的佼佼者,不过它也在研究如何利用机器学习自动识别被编辑过的图片,以解决上述问题。
这篇新论文展示了如何利用机器学习识别三种常见的图像处理操作:
拼接(splicing)—— 拼接取自不同图像的两部分;如下图中第一行,经过识别与分析,向日葵并不是原图中的一部分,是从另外一张图片中截取后放到最后的图片中,这种对图片的编辑操作叫拼接;
复制(cloning)—— 在同一图像中复制粘帖物体;下图中第二行,真的是两只鸟吗?经过识别与分析发现,后面更远处的那只鸟完全是前面更近这只鸟的复制品,这类操作叫图片的克隆(复制);
移除(removal)——移除图像中的物体;下图中第三行,可以非常容易的发现,黄色小球被从图片中移除了,这种对图片的操作称为移除。

为了识别出这些处理操作,数字取证专家通常会在图像的隐藏图层中寻找线索。上面提到的三种操作往往会留下数字处理痕迹,例如:由图像传感器造成的颜色和亮度随机变化不一致现象(也称图像噪声)。举例来说,当拼接两张不同图像,或者在同一图像中将某一部分中的一个物体复制粘帖到另一部分时,背景噪声会无法匹配,就像是用另一种与墙面颜色相近的颜料涂抹墙上的一个斑点。
和许多其他机器学习系统一样,Adobe 的机器学习系统在训练时使用的也是由经剪辑图像组成的大型数据集。借助这个数据集,系统学习并识别篡改操作的常见模式。
▌研究介绍
图像处理检测与传统的语义对象检测不同,前者更多关注的是篡改痕迹而不是图像内容,这意味着图像处理检测需要学习丰富的特征。我们用四个标准图像处理数据集进行了试验,试验表明我们所提出的双流框架的检测性能达到了先进水准,不仅优于单流框架,而且优于其他替代方法,并且对图像尺寸调整和压缩有很好的鲁棒性(robustness)。
图像编辑方法和方便的图像编辑软件出现后,低成本的图像篡改或处理操作得到了广泛使用。有时,在完成拼接、复制或移除这三种常见的处理操作后还要进行后处理,例如高斯平滑处理(Gaussian smoothing)。即使进行仔细检查,人类也很难识别出被处理的区域。

用不同篡改方法处理后的图像示例
从上到下分别展示的是拼接、复制移动和移除操作
这些篡改方法使得分辨真实图像和被处理过的图像变得越来越难。专注于图像取证(image forensics)的新研究非常重要,因为其目标是防止不法分子使用被篡改的图像进行不道德的商业或政治活动。当前的目标检测网络主要用于检测图像中所有不同类别的目标,而图像处理检测网络专门用于检测被篡改的区域(通常为图像中的目标)。通过研究RGB图像内容和图像噪声特征,我们探讨了如何调整目标检测网络,以使其能够执行图像处理检测。
图像取证的最新研究利用局部噪声特征和相机彩色滤波阵列(Camera Filter Array,CFA)模式等线索,将图像中的特定patch或像素分类为“被篡改”和“未被篡改”两个类别,并定位被篡改的区域。其中,大部分方法针对的是一种单一篡改方法。最近提出的一种基于长短期记忆网络(LSTM)的架构通过学习可以检测被篡改的边界(edge),并对被篡改的 patches 进行分割。
在本文中,我们提出了一种双流Faster R-CNN网络,对其进行端对端训练,检测经处理图像中被篡改的区域。其中一个流是RGB流,其作用是从RGB图像输入中提取特征,找出篡改痕迹(例如:对比度差异、不自然的边界等)。另一个流是噪声流,其作用是利用从SRM模型(steganalysis rich model)过滤层中提取的噪声特征,找出图像中真实区域和被篡改区域的噪声间的不一致。然后,用一个双线性池化层整合从RGB流和噪声流中提取出的特征,以进一步改进这两种模式的空间共现性(spatial co-occurrence)。
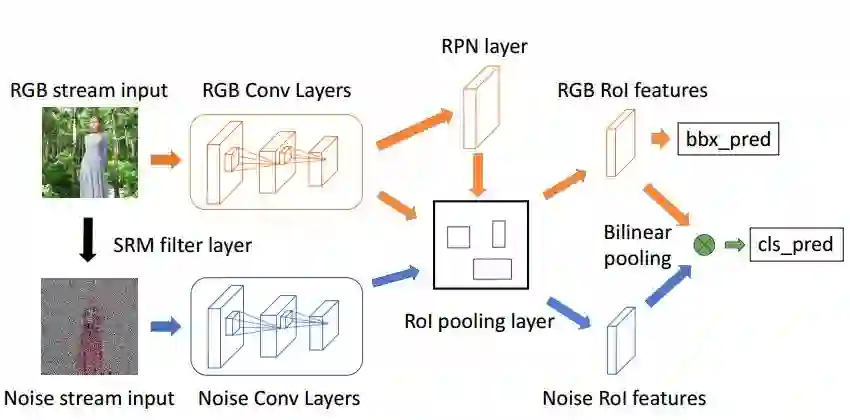
双流Faster R-CNN网络图示
网络结构中各部分为:
RGB stream input:RGB 流输入;对可见的篡改痕迹(例如:物体边界经常出现的高对比度)进行建模,并将边界框(bounding boxes)回归为ground-truth。
SRM filter layer:SRM 过滤层;提取噪声 feature map,然后利用噪声特征提供图像处理分类的附加依据;
Noise stream input:噪声流输入;分析图像中的局部噪声特征,先让输入RGB图像通过一个 SRM 过滤层;
RGB Conv Layers:RGB 卷积层
Noise Conv Layers:噪声卷积层
RGB 流和噪声流共用 RPN 网络生成的 region proposals,RPN 网络只将 RGB 特征作为输入。Faster R-CNN 中的 RPN(Region Proposal Network)负责 propose 可能包含相关目标的图像区域,其经过改造后可以执行图像处理检测。
RPN layer:RPN 层
RoI pooling layer:Rol 池化层;从 RGB 流和噪声流中选择空间特征;
RGB RoI features:RGB RoI 特征;
Bilinear pooling:双线性池化;
Noise RoI features:噪声 Rol 特征;
预测边界框(表示为‘bbx pred’)是 RGB Rol 特征中生成的。为了区别被篡改和未被篡改的区域,我们利用从 RGB 通道中提取的特征来捕捉线索,例如:被篡改边界视觉上的不一致,被篡改区域和真实区域间的对比效应等。
在完成 Rol 池化后,网络的线性池化层将整合从 RGB 流和噪声流中分别提取的空间共现特征。
最后,将所得结果输入到一个全连接层和一个 softmax 层,网络生成预测标签(表示为‘cls pred’))并确定预测边界是否经过处理。
第二个流背后,当从图像(源图像)中移除某一目标并将其粘贴到另一图像(目标图像)中时,源图像和目标图像的噪声特征是不可能匹配的。如果用户对被篡改的图像进行压缩,就可以部分掩饰这些特征差异。
为了利用这些特征,我们将 RGB 图像转化为噪声域(noise domain),然后将局部噪声特征作为第二个流的输入。在一张图像中生成噪声特征的方法有很多种。我们参考了 SRM 模型(steganalysis rich model)图像处理分类的最新研究后,最终选择 SRM 过滤器核(SRM filter kernels)来生成噪声特征,然后将这些 SRM 过滤器核最为第二个 Faster R-CNN 的输入通道。
对 RGB 流和噪声流中提取的特征进行双线性池化,然后每个 Rol 池化层将依据从这两个流中提取的特征检测篡改痕迹。
▌研究结果
先前的图像处理数据集只有几百张图像,不足以训练一个深度网络。为了克服这个困难,我们在 COCO 数据集的基础上创造了一个合成的篡改图像数据集,用来预训练模型,然后再在不同数据集上对模型进行微调,以进行测试。我们在四个标准数据集上的试验结果表明,该模型的表现十分优秀。我们的这项研究有两大贡献。一,我们展示了如何将 Faster R-CNN 框架改造为可以执行图像处理检测的双流框架。我们研究了两种模式——RMB 篡改痕迹和局部噪声特征不一致性,对这两种模式进行双线性池化,以识别被篡改的区域。二,我们证明了在检测不同篡改方法时 RGB 流和噪声流时互补的,这使得我们的框架在四个图像处理数据集上的表现优于其他先进的方法。
▌结束语
Adobe 的发言人在接受科技媒体 The Verge 采访时表示,这项研究还是一个 “早期研究项目”,但是未来 Adobe 希望可以 “开发用于监督和验证数字媒体可信性的技术”。这句话意味着什么还不清楚,因为 Adobe 之前从未发布过任何用于识别虚假图像的软件。但是 Adobe 指出,与执法机构的合作(例如:利用数字取证技术帮助寻找失踪儿童)正是 Adobe 对其技术负责任态度的体现。
撇开对 AI 危害的警告不谈,越来越多的研究致力于在数字世界打假,如果正如那些 AI 危害论者所说,人类将进入某种后真相时代,那么我们将需要使用一切可以使用的工具来辨别真假。而 AI 就像是一把双刃剑,既可以带来危害,也可以带来帮助。
参考链接:
https://www.theverge.com/2018/6/22/17487764/adobe-photoshopped-fakes-edit-spotted-using-machine-learning-ai
http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhou_Learning_Rich_Features_CVPR_2018_paper.pdf
——【完】——


