从概念到技术,再到国际标准和开源社区,联邦学习只用两年时间

联邦学习为什么这么火?!
作者 | 京 枚
编辑 | 唐 里
8 月 16 日,第二十八届国际联合人工智能大会(IJCAI 2019)在澳门成功闭幕。
本届 IJCAI 正值 IJCAI50 周年,主办方组织了一系列的主题活动。除了论文、Tutorial、Workshop、demo、展览等常规环节之外,还举办了包括 IJCAI 50 周年纪念、AI in China、用户数据隐私等极具特色的 panel 环节。而在这诸多内容中,「联邦学习」无疑是最值得关注的内容之一。
在 8 月 12 日的 Workshop Day 中,由微众银行与 IBM 等机构举办的「首届联邦学习国际研讨会」成为了当天最受欢迎的 Workshop,研讨会尚未开始就已爆满,还有不少参会者挤在门外旁听,听众的热情超出了主办方的预期。

据 AI 科技评论了解,本次「首届联邦学习国际研讨会」由微众银行、IBM Research 主办,并得到了爱思唯尔、创新工场、松鼠 AI 的赞助和中国人工智能开源软件发展联盟(AIOSS)及 IEEE 等机构的支持。
在 IJCAI 大会期间同时还举办了「IEEE P3652.1(联邦学习基础架构与应用) 标准工作组第三次会议」,另外「AI 安全专题研讨会」、「AI 与用户隐私」圆桌会上微众银行也分享了联邦学习的相关内容。这恐怕也是自 2017 年联邦学习概念提出以来,联邦学习研究人员首次在人工智能国际顶会上如此密集的发声,以微众银行为代表的诸多企业的参与也标志着联邦学习已经逐步从基础研究走向落地应用,而「首届联邦学习国际研讨会」的召开则标志了联邦学习国际社区的正式成立,联邦学习进入了一个新的阶段。
联邦学习为何成为备受产业界关注的热点?
2006 年以来,随着深度学习神经网络的提出、算法改善和算力的提升、以及大数据的广泛应用,人工智能迎来了一波新的高峰。2016 年的「人机大战」AlphaGo 战胜围棋世界冠军李世石,不仅展示了以大数据驱动的人工智能的巨大潜力,也让人们更加期待一个人工智能在各行各业中得以实现的新时代的到来。
然而理想很丰满,现实很骨感——在实际应用中,大多数应用领域均存在数据有限且质量较差的问题,在某些专业性很强的细分领域(如医疗诊断)更是难以获得足以支撑人工智能技术实现的标注数据。同时在不同数据源之间存在难以打破的壁垒,「大数据」往往只是越来越多的「数据孤岛」的总称。
同时随着大数据的发展,重视数据隐私和安全已经成为一种世界性的趋势,而欧盟「数据隐私保护条例」(General Data Protection Regulation,GDPR)等一系列条例的出台更是加剧了数据获取的难度,这也给人工智能的落地应用带来了前所未有的挑战。
「联邦学习」(Federated Learning)就是为解决传统机器学习方法所面临的数据困境的一种新的尝试。这是一种在保护数据隐私、满足合法合规要求的前提下,多参与方或多计算结点之间开展高效率的机器学习的新型人工智能基础技术。联邦学习具有以下特点:
在联邦学习的框架下,各参与者地位对等,能够实现公平合作;
数据保留在本地,避免数据泄露,满足用户隐私保护和数据安全的需求;
能够保证参与各方在保持独立性的情况下,进行信息与模型参数的加密交换,并同时获得成长;
建模效果与传统深度学习算法建模效果相差不大。尤其在联邦迁移学习过程中可做到「无损失」,避免了迁移学习的负迁移;
联邦学习是一个「闭环」的学习机制。模型效果取决于数据提供方对自己和他人的贡献,有助于激励更多机构加入数据联邦。
联邦学习的上述特点对于打破数据孤岛、推动人工智能在更多的行业落地上有着重要的意义。为了给用户提供更好的服务,在人工智能应用中需要多方整合数据迫切性达到了一个前所未有的程度。
但如果在公司间无法交换数据,除了少数几家拥有海量用户、具备产品和服务优势的「巨无霸」公司外,大多数企业难以以一种合理合法的方式跨越人工智能落地的数据鸿沟,或者对于他们来说需要付出巨大的成本来解决这一问题。
联邦学习正是在现有的机制和流程无法改变的情况下,希望通过技术手段建立一个虚拟的共有模型,从而达到好像大家把数据聚合在一起建立的最优模型一样的效果。
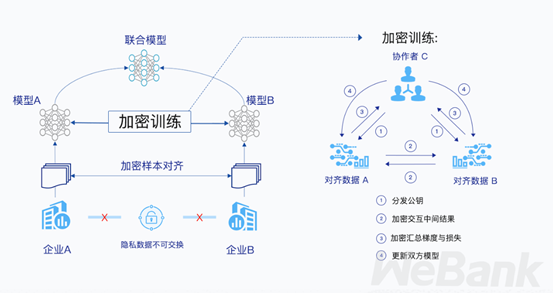
值得一提的是,这种数据聚合并不是简单地将各方数据进行合并,而是在各参与方自有数据不出本地、通过加密机制下的交换方式,从而在各参与方一端均建立起高质量的模型(例如说,企业 A 建立一个分类任务模型,企业 B 建立一个预测任务模型)。相比起各数据主体拥有私有数据「各自为政」的传统方式,「联邦」包含着将多方以平等的地位团结起来,有「君子和而不同」的意义。
关于「联邦学习」的名字还有一个故事:在早期国内将「FederatedLearning」大多翻译为「联合学习」,现多称为「联邦学习」。其中的区别是,如果用户是个人,确实是把他们的模型「联合」起来学习;而如果用户是企业、银行、医院等大数据拥有者,这种技术则更像是将诸多「城邦」结合起来,「联邦」一词则更为准确。这一名字的变化,也反映着联邦学习的研究主体从理论转向实际应用的变化趋势。
联邦学习的进化之路
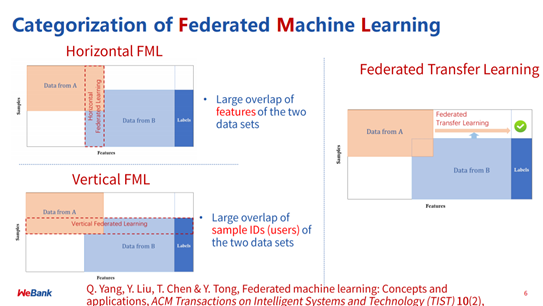
2017 年,为解决安卓手机用户个人终端设备上的模型(如输入法预选词的推荐模型)训练引发的数据安全和大量数据传输问题,谷歌提出了一种新的数据联合建模方案,使得用户在使用安卓手机时在本地更新模型参数,并将参数上传到云上,从而使得具有相同特征维度的数据方联合建立模型。它能够解决两个数据集的样本特征重叠部分较大、样本重叠部分较小的数据集分布情况。这种联合建模方案被称为横向联邦学习,也是最早的联邦学习的方式。
联邦学习的分类
针对不同的数据样本类型,除了横向联邦学习,还有纵向联邦学习和联邦迁移学习两种不同的方式。
前者用于解决样本重叠部分较大,而样本特征重叠部分较小的数据集、需要纵向切分的情况,而针对数据集的样本和样本特征重叠部分都比较小、或没有重叠部分的情况。
香港科技大学讲席教授、微众银行首席人工智能官杨强教授带领微众银行 AI 团队将迁移学习和联邦学习结合起来提出了联邦迁移学习,不是通过对数据进行切分进行训练,而是通过迁移学习进行训练。
从业务场景上具体举例来说,相同业务类型、不同区域的场景(如两家不同地区的区域性银行)适用横向联邦学习,同一区域、不同业务类型的场景(如深圳的一家银行和超市)适合纵向联邦学习,而区域和业务不同的机构(如一家美国超市和一家中国的银行)则通过引入联邦迁移学习来解决单边数据规模和标签样本不足的问题。
由此也可见,微众银行 AI 团队提出的联邦迁移学习针对的情景更加具有普适性,也更符合未来大数据、多企业、跨行业的应用需求。
杨强教授领导下的微众银行AI团队则是成为了中国乃至国际联邦学习的主要推动者。
从 2018 年起,微众银行 AI 团队不仅在 CCAI、AAAI、CCF 青年精英大会、IJCAI 等各类学术交流会议上多次交流联邦学习成果,还与 CCF、IEEE 等专业组织多次举办研讨会,与业界共探联邦学习的创新突破;在近期发表的多篇论文中,微众 AI 团队介绍的联邦学习思路下针对有安全需求的有监督学习、强化学习、决策树的具体方法,包括安全的联邦迁移学习、联邦强化学习以及 SecureBoost 安全树模型受到了研究者和业界的关注。
在技术落地上,微众银行还将联邦学习应用于自身的信贷风控、客户权益定价等多项金融业务流程;与此同时,微众银行还与鹏城实验室、瑞士再保险、极视角等多家企业及机构签署合作,将联邦学习技术推广应用于更多领域。
微众银行 AI 团队还致力于推动联邦学习的标准化。这也是一项技术走向成熟并逐步落地时的必要过程,联邦学习要想真正实现落地应用,就必须建立一种企业之间的对话语言,并且是得到国际法律法规体系支持的对话语言。
去年 10 月份微众银行 AI 团队向 IEEE 标准协会提交了关于建立联邦学习标准的提案——「Guide forArchitectural Framework and Application of Federated Machine Learning」(联邦学习基础架构与应用标准),并于 2018 年 12 月获批。
随后在杨强教授的主导下成立了 IEEE P3652.1(联邦学习基础架构与应用) 标准工作组,工作组在今年 2 月和 6 月分别召开了第一次、第二次会议,分别梳理了各自领域内的联邦学习典型案例,对联邦学习标准的具体形式及内容进行了讨论,对标准草案的制定提出了建设性意见。
在本次的 IJCAI 会议上,微众银行再次联合 20 余家国内外企业、单位共同举办了 IEEE P3652.1(联邦学习基础架构与应用) 标准工作组第三次会议,这次会议的主要内容是聚焦联邦学习各项指标的评估如何量化、标准如何体现联邦学习技术的合规性、联邦学习应用案例的分类归纳等议题。
联邦学习进入国际标准流程,其意义在于让加入联邦学习联盟的企业能够在同一个框架上对话,同时如果新的企业或机构想要加入联邦学习,也必须按照这一标准的规定应用同样的框架,这样反过来又能够推动联邦学习生态的扩大,可以说是给整个联邦学习的生态建设打下了一个基石,意义巨大。
走出金融场景,用开源平台打造AI大数据生态
一直以来,金融行业是大数据与人工智能落地最具潜力的行业之一。金融行业是数据密集型行业,金融数据具有更高的实时性、安全性和稳定性的要求,结构化数据占比高,应用场景广泛。但与此同时,金融行业还有赖于利用第三方数据来为客户提供更好的服务,自身业务特点也对金融数据的数据安全和个人隐私保护带来了极大的困难,数据孤岛现象严重,这也是为何联邦学习首先在微众银行这样的创新金融企业落地和开花结果的原因。
但联邦学习所适用的场景不仅仅是金融行业。在其他行业,数据孤岛的问题也同样普遍存在。如何利用联邦学习的能力做到「学习如何学习」,在积累了很多领域的学习经验后将迁移的例子做成训练集,让人工智能来规划如何在不同领域中实现迁移,对人工智能的落地具有指导性的意义。而在此过程中,积累的领域越多,可获得的训练集(即不同领域间相互迁移的例子)将会呈指数型的增长,因此建立一个联邦学习的生态系统至关重要。
基于此种思考,微众银行 AI 团队发起了一个旨在开发和推广安全和用户隐私保护下的 AI 技术及其应用的项目「联邦学习生态」(FedAI Ecosystem)。项目在确保数据安全及用户隐私的前提下,建立基于联邦学习的 AI 技术生态,使得各行业更充分发挥数据价值,推动垂直领域案例落地。
对技术推进的另一种方式是开源。
今年 6 月份微众银行开源了工业级联邦学习技术框架 Federated AI Technology Enabler(简称 FATE)。之所以称之为「工业级」,在于它能够解决包括计算架构可并行、信息交互可审计、接口清晰可扩展在内的三个工业应用常见问题。
FATE 项目并不仅仅提供了一系列开箱即用的联邦学习算法、比如 LR、GBDT、CNN 等等,更重要的是给开发者提供了实现联邦学习算法和系统的范本,大部分传统算法都可以经过一定改造适配到联邦学习框架中来,通过项目开源,对相关机构进行 AI 赋能,提升机构自身的建模技术和能力,为工业界人员快速开发应用提供一种简洁有效的解决方案,支持在多场景下的开拓和应用采用联合共建、平台服务等方式进行解决方案落地。
尽管联邦学习为诸多之前人工智能难以落地的应用场景提供了一个可行的思路,在具体的落地上,不同行业也还存在一系列不同的问题。如在「首届联邦学习国际研讨会」现场,一位来自华为的技术人员对 AI 科技评论表示,他来参加这个研讨会的目的是希望解决他在实际应用中相关技术的两个困惑,一是在智慧城市的场景中,如何利用有标注的数据,通过联邦学习帮助利用本地摄像头无标注数据进行学习,二是在医疗场景中,在拉通两个医院的交换模型之前,是否可能初步预测交换得到的性能得到提升。在联邦学习进一步推广的路上,还需要更多的人加入生态的建设。
令人欣喜的是,本次研讨会收到了很多来自各高校机构、企业的优秀论文,联邦学习的社区在进一步壮大。同时在研讨会第二天,微众银行再次升级了 FATE,推出首个可视化联邦学习工具 FATEBoard,以及联邦学习建模 pipeline 调度和生命周期管理工具 FATEFlow,并对 FederatedML 进行了重大升级,在算法上也有了更新。新版的 FATE 还加入可部分支持多方的功能,在后续版本中,微众银行 AI 团队将会对支持多方功能做进一步的加强。

IJCAI 上举办的首届联邦学习国际研讨会是联邦学习的一个重要时间节点。
在此之前,尽管关于联邦学习有过许多论文、演讲和新闻报道,但外界几乎没有一个能够一窥全貌的机会,联邦学习的研究者也极少能有机会汇聚一堂了解联邦学习当前发展的全貌。IJCAI 上开展的首届国际联邦学习研讨会,是联邦学习社区的第一次集中发声,也同时吸引了大量各界人士的关注。而在今年 12 月在温哥华举行的机器学习顶会 NeurIPS 上,微众银行也将再度举办联邦学习研讨会,向大众分享更多联邦学习方面的研究进展及实践经验。
展望
自从 2012 年的第三波人工智能浪潮汹涌而来,在最初的新鲜劲褪去后,我们与人工智能已遭遇「七年之痒」式的审美疲劳。
尽管人工智能领域依然有持续性的进展,但在大众的眼里,人工智能的承诺仍然大部分没有实现。研究者已经意识到,在人工智能领域的突破极度依赖标注数据,像 ImageNet 这样的开放式高质量数据集已经成为创新的动力之源。
未来人工智能的挑战依然在数据方面:随着互联网、5G 技术的进步和廉价传感器的更多应用,未来的数据将会呈现海量碎片化的趋势,在训练数据集上要求更低的技术,包括生成对抗网络、强化学习、迁移学习与联邦学习,将会成为研究者们寄予厚望的方向。
那么,联邦学习未来是否可期?
本次研讨会爆满的场面也是一个极强的信号,面向实际问题的人工智能解决方案要能有效解决数据不足、割裂、小数据的数据困境,更一定要解决安全、合规、隐私保护的问题,并且还要能够提高模型的效率。目前这样一个 AI 技术时代,用户隐私保护将成为社会的一个强约束,越来越多的人和企业开始意识到「数据孤岛」的严重性以及数据共享的迫切性。联邦学习能够同时兼顾解决这两个问题(隐私保护与共享),为我们建立一个跨企业、跨数据、跨领域的大数据 AI 生态提供了良好的技术支持,而连接更多行业和应用场景的联邦学习生态系统,也将是联邦学习得以脱颖而出的利器。
点击 阅读原文 查看更多IJCAI顶会见闻!



