谷歌云的自动重启机制失灵,导致网络和 ComputeEngine 宕机 93 分钟 !
到头来还得靠活生生的人来救驾!
不妨说说还是人来得可靠的又一个案例:谷歌近日承认,2018年1月18日谷歌云的us-central1和europe-west3这两个可用区中的计算引擎(Compute Engine)停运了93分钟,根本原因出在了自动化失灵上。
谷歌将那次停运归咎于“网络编程失效”,表示Autoscaler(自动扩展器)服务因此没有正常运行,因而无法扩展实例组。该软件失效意味着,新的虚拟机或刚迁移的虚拟机无法与其他可用区中的虚拟机进行联系。
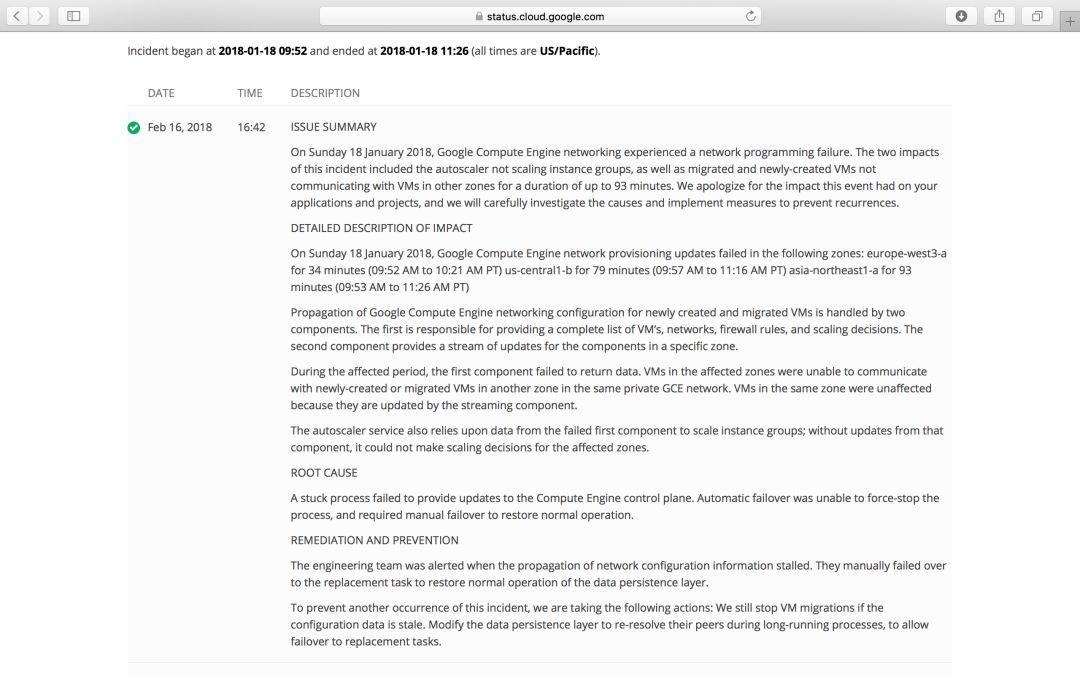
这个云计算市场的有力竞争者解释了这次宕机事件,透露“传播刚创建和迁移的虚拟机的谷歌计算引擎网络配置这项任务由两个组件来处理。第一个组件负责提供虚拟机、网络、防火墙规则和扩展决策的完整列表。”
“第二个组件为特定可用区中的部件提供更新数据流。”
在停运期间,第一个组件没有发送任何数据。缺少这种信息意味着,其他受影响的可用区的虚拟机无法搞清楚该如何联系其他虚拟机。Autoscaler服务也依赖来自失效的第一个组件的信息流来扩展实例组,由于没有收到来自该组件的更新信息,它无法为受影响的可用区做出扩展决策。
那么,为什么那第一个组件失效?谷歌称这个问题是“进程被卡壳了,结果没有为计算引擎控制面板发送更新数据”。换句话说,原来的进程挂起了。
本来这通常不是个问题,但“自动故障切换无法强制终止进程,需要手动故障切换才能恢复正常操作。”
是的,你明白了:自动化机制失灵了,最后还是人收拾了残局。
或者就像谷歌说的那样:“传播网络配置信息的任务出现停滞时,工程团队收到了警报,他们在故障后手动切换到替换任务,以恢复数据持久层的正常运行。”
谷歌郑重承诺,将来,“如果配置数据过时,它会停止虚拟机迁移”,并且“数据持久层会在长时间运行的进程期间重新解析对等体(peer),以便故障后切换到替换任务。”
听起来谷歌还是要走自动化的路子。所以老兄,切忌太过沾沾自喜了。
相关阅读:
AWS vs Azure vs 谷歌云:市场份额、2017年纵览
谷歌云 TPU 开放:「AlphaGo背后的芯片」进入商用化
谷歌:路由器更新和数据中心自动化出了岔子,云服务中断2个小时






