成立不足五年,GMV 达百亿美元,东南亚淘宝 Shopee 是如何进行数据库选型的?

作者丨刘春辉
策划丨田晓旭
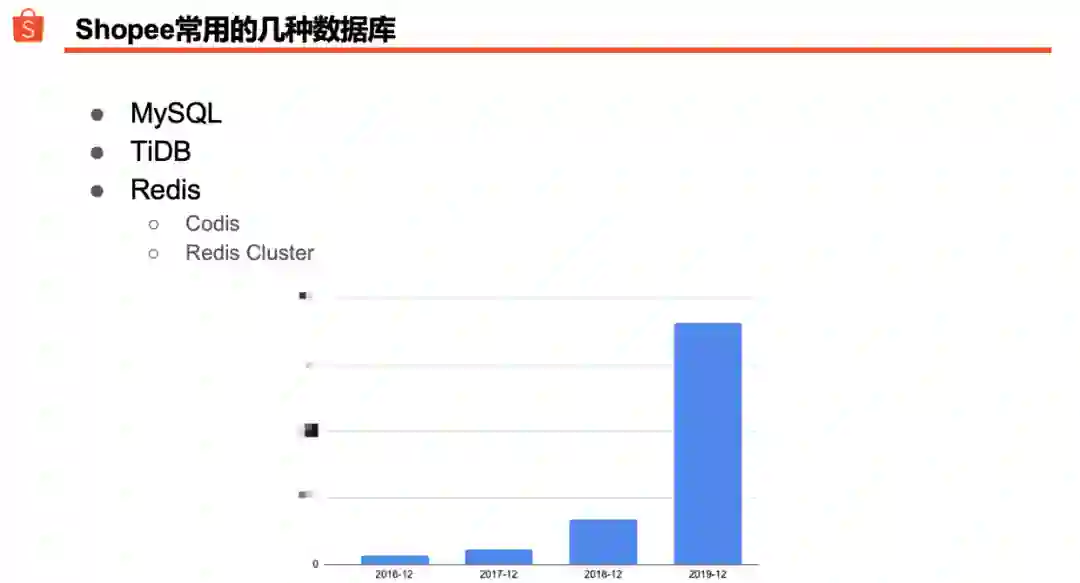
先说一下当前 Shopee 线上在用的几种数据库:
在 Shopee,我们只有两种关系数据库:MySQL 和 TiDB。目前大部分业务数据运行在 MySQL 上,TiDB 集群的比重过去一年来快速增长中。
Redis 在 Shopee 各个产品线使用广泛。从 DBA 的角度看,Redis 是关系数据库的一种重要补充。
内部也在使用诸如 HBase 和 Pika 等多种 NoSQL 数据库,使用范围多限于特定业务和团队。不在本次讨论范围内。
过去的一年里,我们明显感觉到数据库选型在 DBA 日常工作中的占比越来越重了。随着业务快速成长,DBA 每周需要创建的新数据库较之一两年前可能增加了十倍不止。我们每年都会统计几次线上逻辑数据库个数。上图展示了过去几年间这个数字的增长趋势(纵轴表示逻辑数据库个数,我们把具体数字隐去了)。
历史数据显示,逻辑数据库个数每年都有三到五倍的增长,过去的 2019 年增长倍数甚至更高。每个新数据库上线前,DBA 和开发团队都需要做一些评估以快速决定物理设计和逻辑设计。经验表明,一旦在设计阶段做出了不当决定,后期需要付出较多时间和人力成本来补救。因此,我们需要制定一些简洁高效的数据库选型策略,确保我们大多数时候都能做出正确选择。
我们的数据库选型策略可以概括为三点:
默认使用 MySQL。
积极尝试 TiDB。
在必要的时候引入 Redis 用于消解部分关系数据库高并发读写流量。
在使用 MySQL 的过程中我们发现,当单数据库体量达到 TB 级别,开发和运维的复杂度会被指数级推高。DBA 日常工作会把消除 TB 级 MySQL 数据库实例排在高优先级。
“积极尝试 TiDB”不是一句空话。2018 年初开始,我们把 TiDB 引入了到 Shopee。过去两年间 TiDB 在 Shopee 从无到有,集群节点数和数据体积已经达到了可观的规模。对于一些经过了验证的业务场景,DBA 会积极推动业务团队采用 TiDB,让开发团队有机会获得第一手经验;目前,内部多数业务开发团队都在线上实际使用过一次或者多次 TiDB。
关于借助 Redis 消解关系数据库高并发读写流量,后面会展开讲一下我们的做法。

在制定了数据库选型策略之后,我们在选型中还有几个常用的参考指标:
1TB:对于一个新数据库,我们会问:在未来一年到一年半时间里,数据库的体积会不会涨到 1TB?如果开发团队很确信新数据库一定会膨胀到 TB 级别,应该立即考虑 MySQL 分库分表方案或 TiDB 方案。
1000 万行或 10GB:单一 MySQL 表的记录条数不要超过 1000 万行,或单表磁盘空间占用不要超过 10GB。我们发现,超过这个阈值后,数据库性能和可维护性上往往也容易出问题(部分 SQL 难以优化,不易做表结构调整等)。如果确信单表体积会超越该上限,则应考虑 MySQL 分表方案;也可以采用 TiDB,TiDB 可实现水平弹性扩展,多数场景下可免去分表的烦恼。
每秒 1000 次写入:单个 MySQL 节点上的写入速率不要超过每秒 1000 次。大家可能觉得这个值太低了;许多开发同学也常举例反驳说,线上 MySQL 每秒写入几千几万次的实际案例比比皆是。我们为什么把指标定得如此之低呢?首先,上线前做估算往往有较大不确定性,正常状况下每秒写入 1000 次,大促等特殊场景下可能会陡然飙升到每秒 10000 次,作为设计指标保守一点比较安全。其次,我们允许开发团队在数据库中使用 Text 等大字段类型,当单行记录长度增大到一定程度后主库写入和从库复制性能都可能明显劣化,这种状况下对单节点写入速率不宜有太高期待。因此,如果一个项目上线前就预计到每秒写入速率会达到上万次甚至更高,则应该考虑 MySQL 分库分表方案或 TiDB 方案;同时,不妨根据具体业务场景看一下能否引入 Redis 或消息队列作为写缓冲,实现数据库写操作异步化。
P99 响应时间要求是 1 毫秒,10 毫秒还是 100 毫秒?应用程序要求 99% 的数据库查询都要在 1 毫秒内返回吗?如果是,则不建议直接读写数据库。可以考虑引入 Redis 等内存缓冲方案,前端直接面向 Redis 确保高速读写,后端异步写入数据库实现数据持久化。我们的经验是,多数场景下,MySQL 服务器、表结构设计、SQL 和程序代码等方面做过细致优化后,MySQL 有望做到 99% 以上查询都在 10 毫秒内返回。对于 TiDB,考虑到其存储计算分离和多组件协作实现 SQL 执行过程的特点,我们通常把预期值调高一个数量级到 100 毫秒级别。以线上某 TiDB 2.x 集群为例,上线半年以来多数时候 P99 都维持在 20 毫秒以内,偶尔会飙升到 200 毫秒,大促时抖动则更频繁一些。TiDB 执行 SQL 查询过程中,不同组件、不同节点之间的交互会多一些,自然要多花一点时间。
内部的数据库设计评估清单里包含十几个项目,其中“要不要分库分表”是一个重要议题。在相当长时间里,MySQL 分库分表方案是我们实现数据库横向扩展的唯一选项;把 TiDB 引入 Shopee 后,我们多了一个“不分库分表”的选项。
从我们的经验来看,有几种场景下采用 MySQL 分库分表方案的副作用比较大,日常开发和运维都要付出额外的代价和成本。DBA 和开发团队需要在数据库选型阶段甄别出这些场景并对症下药。
难以准确预估容量的数据库。举例来讲,线上某日志数据库过去三个月的增量数据超过了之前三年多的存量体积。对于这类数据库,采用分库分表方案需要一次又一次做 Re-sharding,每一次都步骤繁琐,工程浩大。Shopee 的实践证明,TiDB 是较为理想的日志存储方案;当前,把日志类数据存入 TiDB 已经是内部较为普遍的做法了。
需要做多维度复杂查询的数据库。以订单数据库为例,各子系统都需要按照买家、卖家、订单状态、支付方式等诸多维度筛选数据。若以买家维度分库分表,则卖家维度的查询会变得困难;反之亦然。一方面,我们为最重要的查询维度分别建立了异构索引数据库;另一方面,我们也在 TiDB 上实现了订单汇总表,把散落于各个分片的订单数据汇入一张 TiDB 表,让一些需要扫描全量数据的复杂查询直接运行在 TiDB 汇总表上。
数据倾斜严重的数据库。诸如点赞和关注等偏社交类业务数据,按照用户维度分库分表后常出现数据分布不均匀的现象,少数分片的数据量可能远大于其他分片;这些大分片往往也是读写的热点,进而容易成为性能瓶颈。一种常用的解法是 Re-sharding,把数据分成更多片,尽量稀释每一片上的数据量和读写流量。最近我们也开始尝试把部分数据搬迁到 TiDB 上;理论上,如果 TiDB 表主键设计得高度分散,热点数据就有望均匀分布到全体 TiKV Region 上。
总体来说,MySQL 分库分表方案在解决了主要的数据库横向扩展问题的同时,也导致了一些开发和运维方面的痛点。一方面,我们努力在 MySQL 分库分表框架内解决和缓解各种问题;另一方面,我们也尝试基于 TiDB 构建“不分库分表”的新型解决方案,并取得了一些进展。
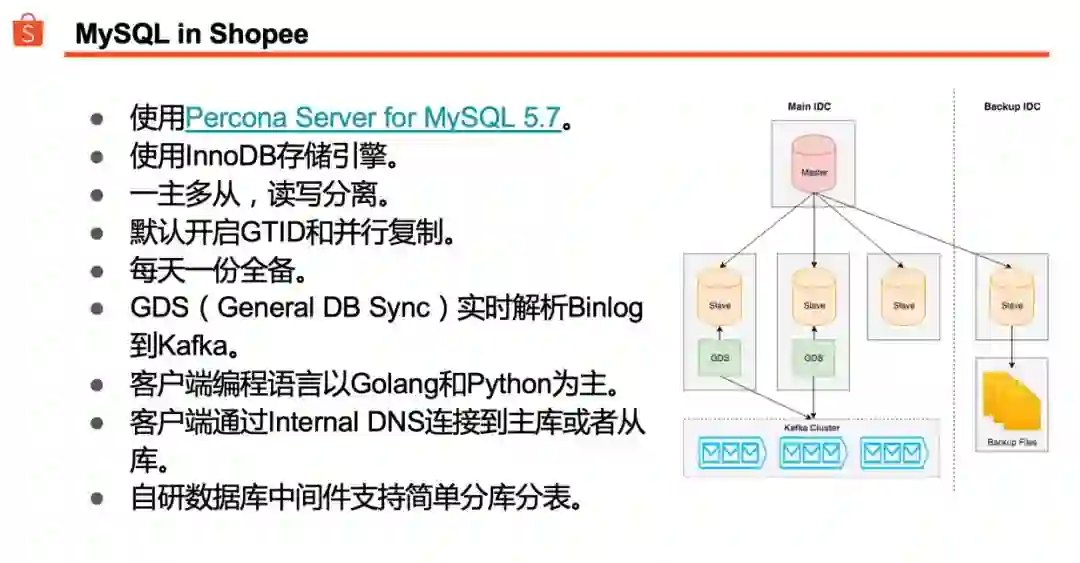
Shopee 的母公司 SEA Group 成立于 2009 年。我们从一开始就使用 MySQL 作为主力数据库,从早期的 MySQL 5.1 逐渐进化到现在的 MySQL 5.7,我们已经用了十年 MySQL。
我们使用 Percona 分支,当前存储引擎以 InnoDB 为主。
一主多从是比较常见的部署结构。我们的应用程序比较依赖读写分离,线上数据库可能会有多达数十个从库。一套典型的数据库部署结构会分布在同城多个机房;其中会有至少一个节点放在备用机房,主要用于定时全量备份,也会提供给数据团队做数据拉取等用途。
如果应用程序需要读取 Binlog,从库上会安装一个名为 GDS(General DB Sync)的 Agent,实时解析 Binlog,并写入 Kafka。
应用程序透过 DNS 入口连接主库或从库。
我们自研的数据库中间件,支持简单的分库分表。何为“简单的分库分表”?只支持单一分库分表规则,可以按日期、Hash 或者某个字段的取值范围来分片;一条 SQL 最终只会被路由到单一分片上,不支持聚合或 Join 等操作。
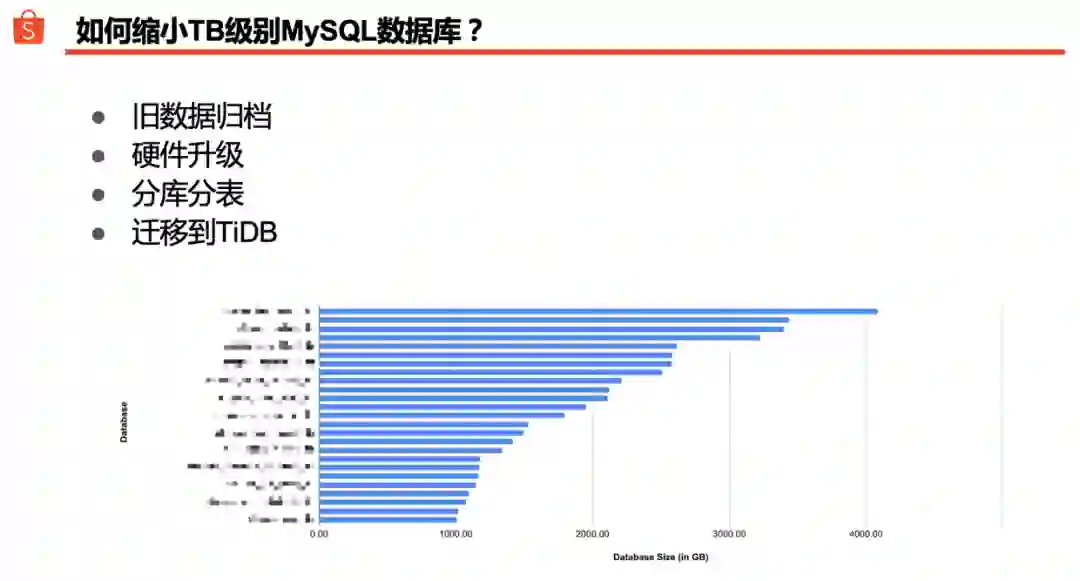
根据我们的统计,Shopee 线上数据库中 80% 都低于 50GB;此外,还有 2.5% 的数据库体积超过 1TB。上图列出了部分 TB 级别数据库的一个统计结果:平均体积是 2TB,最大的甚至超过 4TB。
采用 MySQL 分库分表方案和迁移到 TiDB 是我们削减 TB 级 MySQL 数据库实例个数的两种主要途径。除此之外,还有一些办法能帮助我们对抗 MySQL 数据库体积膨胀带来的负面效应。
旧数据归档。很多旧数据库占据了大量磁盘空间,读写却不频繁。换言之,这些旧数据很可能不是『热数据』。如果业务上许可,我们通常会把旧数据归档到单独的 MySQL 实例上。当然,应用程序需要把读写这些数据的流量改到新实例。新实例可以按年或按月把旧数据存入不同的表以避免单表体积过大,还可以开启 InnoDB 透明页压缩以减少磁盘空间占用。TiDB 是非常理想的数据归档选项:理论上,一个 TiDB 集群的容量可以无限扩展,不必担心磁盘空间不够用;TiDB 在计算层和存储层皆可水平弹性扩展,我们得以根据数据体积和读写流量的实际增长循序渐进地增加服务器,使整个集群的硬件使用效率保持在较为理想的水平。
硬件升级(Scale-up)。如果 MySQL 数据体积涨到了 1TB,磁盘空间开始吃紧,是不是可以先把磁盘空间加倍,内存也加大一些,为开发团队争取多一些时间实现数据库横向扩展方案?有些数据库体积到了 TB 级别,但业务上可能不太容易分库分表。如果开发团队能够通过数据归档等手段使数据体积保持在一个较为稳定(但仍然是 TB 级别)的水准,那么适当做一下硬件升级也有助于改善服务质量。
前文中我们提到,使用 Redis 来解决关系数据库高并发读写流量的问题,下面我们就来讲讲具体的做法。
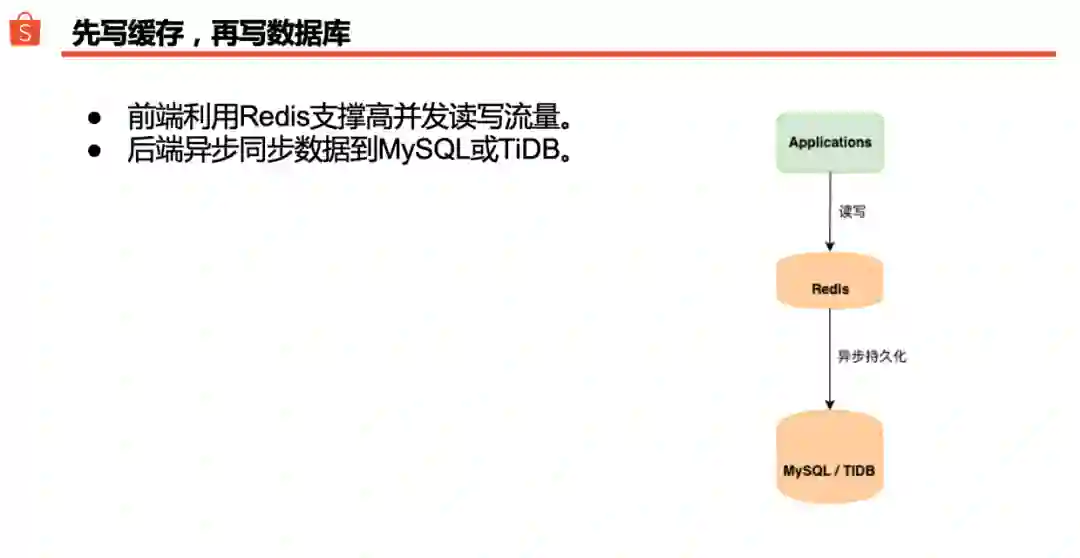
比较常用的一种做法是:先写缓存,再写数据库。应用程序前端直接读写 Redis,后端匀速异步地把数据持久化到 MySQL 或 TiDB。这种做法一般被称之为“穿透式缓存”,其实是把关系数据库作为 Redis 数据的持久化存储层。如果一个系统在设计阶段即判明线上会有较高并发读写流量,把 Redis 放在数据库前面挡一下往往有效。
在 Shopee,一些偏社交类应用在大促时的峰值往往会比平时高出数十上百倍,是典型的“性能优先型应用”(Performance-critical Applications)。如果开发团队事先没有意识到这一点,按照常规做法让程序直接读写关系数据库,大促时不可避免会出现“一促就倒”的状况。其实,这类场景很适合借助 Redis 平缓后端数据库读写峰值。
如果 Redis 集群整体挂掉,怎么办?一般来说,有两个解决办法:
性能降级:应用程序改为直接读写数据库。性能上可能会打一个大的折扣,但是能保证大部分数据不丢。一些数据较为关键的业务可能会更倾向于采用这种方式。
数据降级:切换到一个空的 Redis 集群上以尽快恢复服务。后续可以选择从零开始慢慢积累数据,或者运行另一个程序从数据库加载部分旧数据到 Redis。一些并发高但允许数据丢失的业务可能会采用这种方式。

还有一种做法也很常见:先写数据库,再写缓存。应用程序正常读写数据库,Shopee 内部有一个中间件 DEC (Data Event Center)可以持续解析 Binlog,把结果重新组织后写入到 Redis。这样,一部分高频只读查询就可以直接打到 Redis 上,大幅度降低关系数据库负载。
把数据写入 Redis 的时候,可以为特定的查询模式定制数据结构,一些不太适合用 SQL 实现的查询改为读 Redis 之后反而会更简洁高效。
此外,相较于“双写方式”(业务程序同时把数据写入关系数据库和 Redis),通过解析 Binlog 的方式在 Redis 上重建数据有明显好处:业务程序实现上较为简单,不必分心去关注数据库和 Redis 之间的数据同步逻辑。Binlog 方式的缺点在于写入延迟:新数据先写入 MySQL 主库,待其流入到 Redis 上,中间可能有大约数十毫秒延迟。实际使用上要论证业务是否能接受这种程度的延迟。
举例来讲,在新订单实时查询等业务场景中,我们常采用这种“先写数据库,再写缓存”的方式来消解 MySQL 主库上的高频度只读查询。为规避从库延迟带来的影响,部分关键订单字段的查询须打到 MySQL 主库上,大促时主库很可能就不堪重负。历次大促的实践证明,以这种方式引入 Redis 能有效缓解主库压力。
讲完 MySQL 和 Redis,我们来接着讲讲 TiDB。
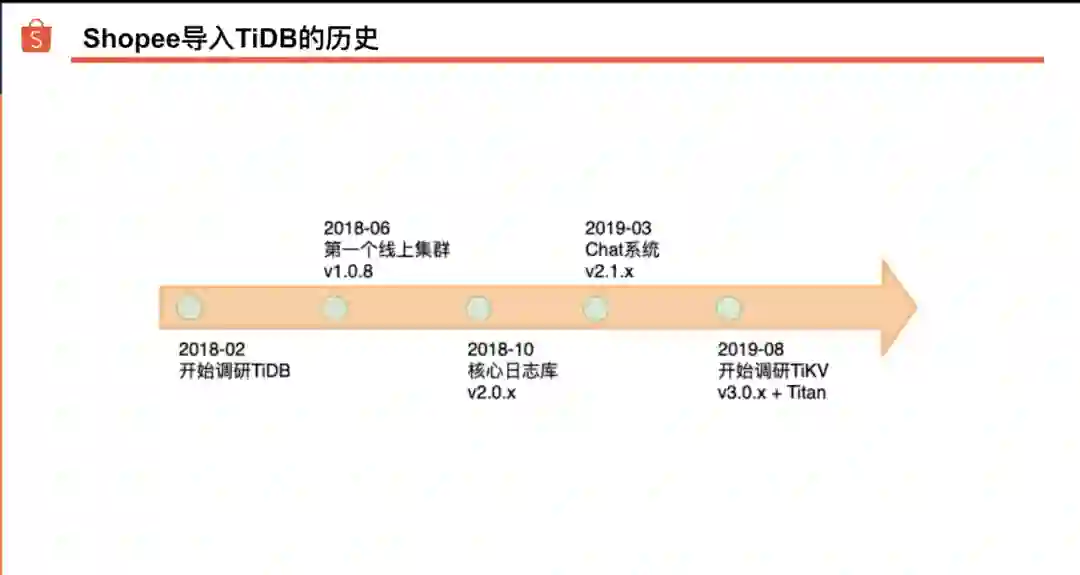
我们从 2018 年初开始调研 TiDB,到 2018 年 6 月份上线了第一个 TiDB 集群(风控日志集群,版本 1.0.8)。2018 年 10 月份,我们把一个核心审计日志库迁到了 TiDB 上,目前该集群数据量约 7TB,日常 QPS 约为 10K ~ 15K。总体而言,2018 年上线的集群以日志类存储为主。
2019 年开始我们尝试把一些较为核心的线上系统迁移到 TiDB 上。3 月份为买家和卖家提供聊天服务的 Chat 系统部分数据从 MySQL 迁移到了 TiDB 。最近的大促中,峰值 QPS 约为 30K,运行平稳。今年也有一些新功能选择直接基于 TiDB 做开发,比如店铺标签、直播弹幕和选品服务等。这些新模块的数据量和查询量都还比较小,有待持续观察验证。
TiDB 3.0 GA 后,新的 Titan ( https://github.com/tikv/titan ) 存储引擎吸引了我们。在 Shopee,我们允许 MySQL 表设计中使用 Text 等大字段类型,通常存储一些半结构化数据。但是,从 MySQL 迁移到 TiDB 的过程中,大字段却可能成为绊脚石。一般而言,TiDB 单行数据尺寸不宜超过 64KB,越小越好;换言之,字段越大,性能越差。Titan 存储引擎有望提高大字段的读写性能。目前,我们已经着手把一些数据迁移到 TiKV 上,并打开了 Titan,希望能探索出更多应用场景。

目前 Shopee 线上部署了二十多个 TiDB 集群,约有 400 多个节点。版本以 TiDB 2.1 为主,部分集群已经开始试水 TiDB 3.0。我们最大的一个集群数据量约有 30TB,超过 40 个节点。到目前为止,用户、商品和订单等电商核心子系统都或多或少把一部分数据和流量放在了 TiDB 上。
我们把 TiDB 在 Shopee 的使用场景归纳为三类:
日志存储场景
MySQL 分库分表数据聚合场景
程序直接读写 TiDB 的场景

第一种使用场景是日志存储。前面讲到过,我们接触 TiDB 的第一年里上线的集群以日志类存储为主。通常的做法是:前端先把日志数据写入到 Kafka,后端另一个程序负责把 Kafka 里的数据异步写入 TiDB。由于不用考虑分库分表,运营后台类业务可以方便地读取 TiDB 里的日志数据。对于 DBA 而言,可以根据需要线性增加存储节点和计算节点,运维起来也较 MySQL 分库分表简单。

第二种使用场景是 MySQL 分库分表数据聚合。Shopee 的订单表和商品表存在 MySQL 上,并做了细致的数据分片。为了方便其他子系统读取订单和商品数据,我们做了一层数据聚合:借助前面提到的 DEC 解析 MySQL Binlog,把多个 MySQL 分片的数据聚合到单一 TiDB 汇总表。这样,类似 BI 系统这样的旁路系统就不必关注分库分表规则,直接读取 TiDB 数据即可。除此之外,订单和商品子系统也可以在 TiDB 汇总表上运行一些复杂的 SQL 查询,省去了先在每个 MySQL 分片上查一次最后再汇总一次的麻烦。
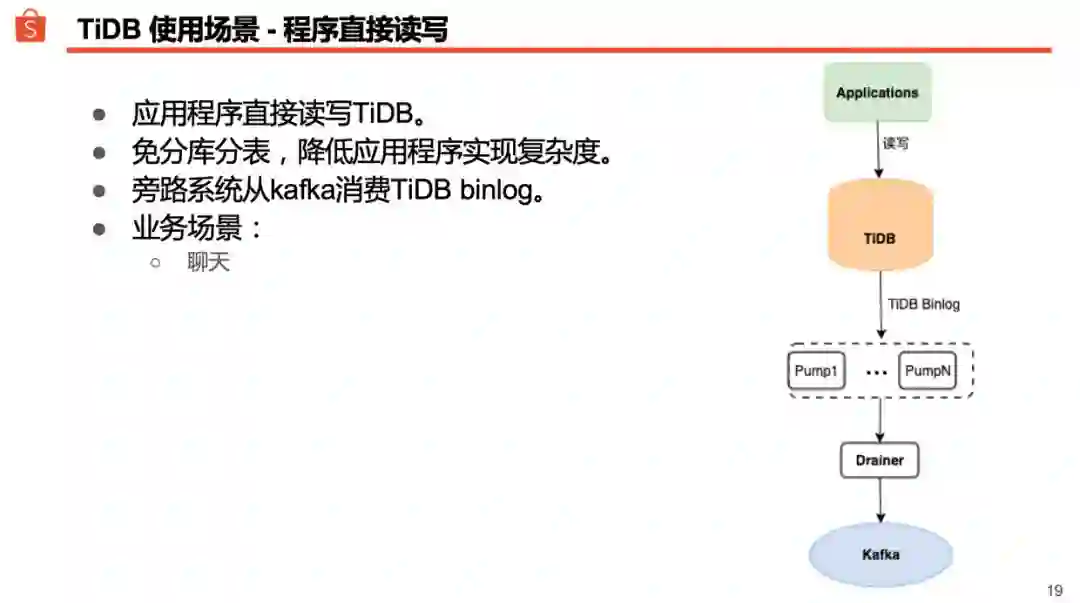
第三种就是程序直接读写 TiDB。像前面提到的 Chat 系统,舍弃了 MySQL,改为直接读写 TiDB。优势体现在两个方面:不必做分库分表,应用程序的实现相对简单、直接;TiDB 理论上容量无限大,且方便线性扩展,运维起来更容易。
前面提到过,在 Shopee 内部使用 GDS(General DB Sync)实时解析 MySQL Binlog,并写入 Kafka 提供给有需要的客户端消费。TiDB 上也可以接一个 Binlog 组件,把数据变化持续同步到 Kafka 上。需要读取 Binlog 的应用程序只要适配了 TiDB Binlog 数据格式,就可以像消费 MySQL Binlog 一样消费 TiDB Binlog 了。
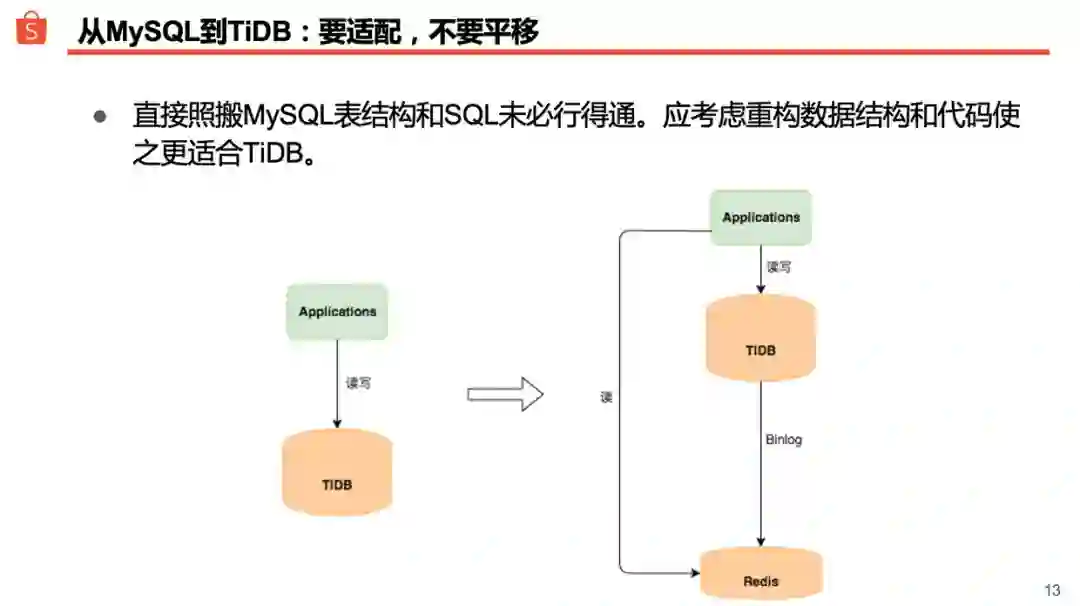
把数据库从 MySQL 搬到 TiDB 的过程中,DBA 经常提醒开发同学:要适配,不要平移。关于这点,我们可以举一个案例来说明一下。
线上某系统最初采用 MySQL 分表方案,全量数据均分到 1000 张表;迁移到 TiDB 后我们去掉了分表,1000 张表合为了一张。应用程序上线后,发现某个 SQL 的性能抖动比较严重,并发高的时候甚至会导致整个 TiDB 集群卡住。分析后发现该 SQL 有两个特点:
该 SQL 查询频度极高,占了查询高峰时全部只读查询的 90%。
该 SQL 是一个较为复杂的扫表查询,不易通过添加索引方式优化。迁移到 TiDB 之前,MySQL 数据库分为 1000 张表,该 SQL 执行过程中只会扫描其中一张表,并且查询被分散到了多达二十几个从库上;即便如此,随着数据体积增长,当热数据明显超出内存尺寸后,MySQL 从库也变得不堪重负了。迁移到 TiDB 并把 1000 张表合为一张之后,该 SQL 被迫扫描全量数据,在 TiKV 和 SQL 节点之间会有大量中间结果集传送流量,性能自然不会好。
判明原因后,开发团队为应用程序引入了 Redis,把 Binlog 解析结果写入 Redis,并针对上述 SQL 查询定制了适当的数据结构。这些优化措施上线后,90% 只读查询从 TiDB 转移到了 Redis 上,查询变得更快、更稳定;TiDB 集群也得以削减数量可观的存储和计算节点。
TiDB 高度兼容 MySQL 语法的特点有助于降低数据库迁移的难度;但是,不要忘记它在实现上完全不同于 MySQL,很多时候我们需要根据 TiDB 的特质和具体业务场景定制出适配的方案。
本文回顾了 Shopee 在关系数据库选型方面的思路,也附带简单介绍了一些我们在 MySQL、TiDB 和 Redis 使用方面的心得,希望能为大家提供一点借鉴。
简单来说,如果数据量比较小,业务处于早期探索阶段,使用 MySQL 仍然是一个很好的选择。Shopee 的经验是不用过早的为分库分表妥协设计,因为当业务开始增长,数据量开始变大的时候,可以从 MySQL 平滑迁移到 TiDB,获得扩展性的同时也不用牺牲业务开发的灵活性。另一方面,Redis 可以作为关系型数据库的很好的补充,用来加速查询,缓解数据库压力,使得数据库能够更关注吞吐以及强一致场景。
刘春辉,Shopee DBA,TiDB User Group Ambassador

QCon 北京 2020 全新起航,来跟业界大牛关注 23+ 技术领域中正在兴起的技术和关键进展。目前大会 8 折报名中,点击【阅读原文】或识别二维码了解更多。有任何问题欢迎联系票务小姐姐 Ring:17310043226(微信同号)