深挖Kubernetes存储为何如此难及其解决方案
戳蓝字“CSDN云计算”关注我们哦!

译者:韦峻峰
转自:RancherLabs
以Kubernetes为代表的容器编排工具在应用开发部署领域起正发挥着颠覆性的变革作用。随着微服务架构的发展,从开发人员的角度来看,应用逻辑架构与基础设施架构之间开始解耦,这意味着开发者能够将精力更多集中在软件构建以及价值交付身上。
Kubernetes的作用,在于对其管理的物理服务器进行抽象。在Kubernetes的帮助下,我们可以描述并使用所需要的内存与计算容量的总和,而不再关注底层基础设施架构。
当管理Docker镜像的时候,Kubernetes也让实际应用变的十分便捷灵活。在利用Kubernetes进行容器架构的应用部署时,管理员们将在无需修改底层代码的前提下将其部署在任何位置——包括公有云、混合云乃至私有云。
虽然Kubernetes在扩展性、便携性与管理性等方面的表现都相当给力,但截至目前,它仍然不支持存储状态。与之对应的是,如今的大多数应用都是有状态的——换言之,要求在一定程度上配合外部存储资源。
Kubernetes架构本身非常灵活的,能够根据开发者的需求、规范以及实际负载情况,对容器进行随意创建与撤销。此外,Pod和容器还具有自我修复与复制能力。因此从本质上讲,它们的生命周期普遍非常短暂。
但是,现有持久存储解决方法无法支持动态的应用场景,而持久化存储也无法满足动态创建与撤销的需求。
当我们需要将有状态应用部署到其它基础架构平台,或者另一家内部或混合云供应商的环境中时,可移植性低下无疑将成为我们面临的巨大挑战。更具体地讲,持久化存储解决方案往往会锁定于特定云服务供应商,而无法灵活完成转移。
另外,云原生应用中的存储机制也相当复杂、难于理解。Kubernetes中的不少存储术语极易混淆,其中包含着复杂的含义与微妙的变化。再有,在原生Kubernetes、开源框架以及托管与付费服务之间还存在着诸多选项,这极大增加了开发人员在做出决定之前的考量与试验成本。
以下是CNCF列出的云原生存储可选方案:

我们首先从最简单的场景出发,即在Kubernetes当中部署一套数据库。具体流程包括:选择一套符合需求的数据库,让它在本地磁盘上运行,然后将其作为新的工作负载部署到集群当中。但是,由于数据库中存在的一些固有属性,这种方式往往无法带来符合预期的效果。
容器本身是基于无状态原则进行构建的,凭借这一天然属性,我们才能如此轻松地启动或撤销容器环境。由于不存在需要保存及迁移的数据,集群也就不需要同磁盘读写这类密集型操作绑定在一起了。
但对于数据库,其状态必须随时保存。如果以容器方式部署在集群当中的数据库不需要进行迁移,或者不需要频繁开关,那么其基本属性就相当于一种物理存储设备。在理想情况下,使用数据的容器应该与该数据库处于同一Pod当中。
当然,这并不是说将数据库部署在容器中的作法不可取。在某些应用场景下,这样的设计完全能够满足需求。举例来说,在测试环境或者处理非生产级数据时,由于总体数据量很小,将数据库纳入集群完全没有问题。但在实际生产中,开发人员往往需要仰仗于外部存储机制。
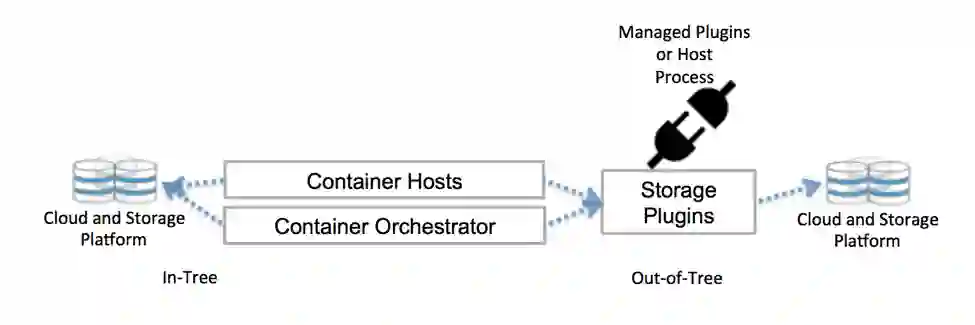
Kubernetes到底是如何与存储资源彼此通信的?其利用的是控制层接口。这些接口负责将Kubernetes与外部存储相对接。接入Kubernetes的外部存储解决方案被称为“卷插件(Volume Plugins)”。正是有了卷插件的存在,存储资源才得以抽象化并实现可移植性。
以前,卷插件一般由核心Kubernetes代码库进行构建、链接、编译以及装载。这样就极大的限制了开发人员的发挥空间,同时也带来了额外的维护开销。因此,项目维护人员们决定在Kubernete的代码库上增加一些新的存储功能。
随着CSI以及Flexvolume的引入,卷插件如今可以在集群中直接部署,而完全无需更改代码库。
原生Kubernetes与存储
原生Kubernetes如何处理存储资源?它提供一系列管理存储选项:除了临时选项之外,还包括持持久卷(Persistent Volumes),持久卷声明(Persistent Volume Claims),存储类(Storage Classes)乃至StatefulSets等持久存储形式。似乎有点乱,下面我们就对其进行一一解释。
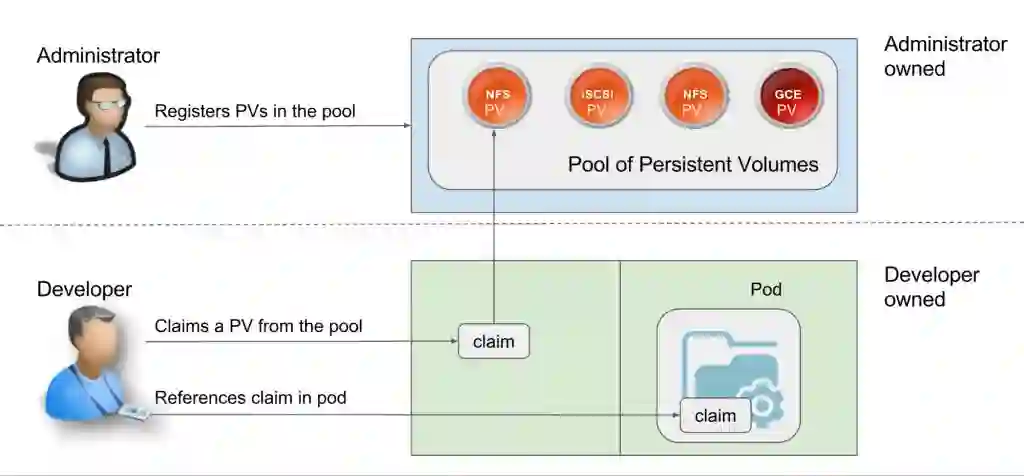
持久卷是由管理员负责配置的存储单元,它们独立于任何单一Pod之外,因此不受Pod生命周期的影响。
另一方面,持久卷声明是对存储资源——也就是持久卷——的需求。有了持久卷声明,我们就可以将存储与特定的节点绑定在一起使用。
存储资源有两种使用方式:静态存储与动态存储。
使用静态存储时,管理员根据预估对持久卷进行预配置,这些持久卷将被手动绑定到具有明确持久卷声明的特定Pod上。
实际上,静态定义的持久卷并不能适应Kubernetes的可移植特性,因为存储资源具有对环境的依赖性——例如AWS EBS或者GCE Persistent Disk。另外,手动绑定还需要根据不同供应商的存储方案修改YAML文件。
在资源分配方面,静态配置实际上也违背了Kubernetes的设计原则。后者的CPU与内存并非事先被分配好绑定在Pod或者容器上,而是以被动态形式进行分配。
动态分配则依靠存储类来实现。集群管理员不需要预先手动创建持久卷,而是创建类似于模板的文件。当开发人员制作持久卷声明时,只需要根据实际需求创建一套模板并附加至Pod即可。
通过简单的说明,相信大家已经了解了原生Kubernetes对外部存储资源的使用方式。当然,这里仅仅做出概括,实际使用场景中还有更多其它因素需要考量。
CSI——容器存储接口
下面来看容器存储接口(简称CSI)。CSI是由CNCF存储工作组创建的统一标准,旨在定义一个标准的容器存储接口,从而使存储驱动程序能够在任意容器架构下正常起效。
CSI规范目前已经在Kubernetes中得到普及,大量驱动插件被预先部署在Kubernetes集群内供开发人员使用。如此一来,我们就可以利用Kubernetes上的CSI卷来访问与CSI兼容的开放存储卷。
CSI的引入,意味着存储资源能够作为Kubernetes集群上的另一种工作负载实现容器化以及部署。
相关开源项目
目前,围绕云原生技术涌现出大量工具与项目。但作为生产场景中的一大突出问题,我们往往很难在云原生架构中选择最合适的开源项目。换言之,解决方案选项太多,反而令存储需求变得更难解决。
我们再看一次CNCF列出的云原生存储的可选方案:
下面我会分享一下当下流行的存储方案Ceph与Rook,还有Rancher开源的容器化分布式存储Longhorn。
Ceph
Ceph是一种动态托管、横向扩展的分布式存储集群。Ceph面向存储资源提供一种逻辑抽象机制,其设计理念包括无单点故障、自管理以及软件定义等特性。Ceph可以面向同一套存储集群分别提供块存储、对象存储以及文件存储的对应接口。
Ceph架构相当复杂的,其中使用到大量的底层技术,例如RADOS、librados、RADOSGW、RDB、CRUSH算法,外加monitor、OSD以及MDS等功能性组件。这里我们先不谈它的底层架构,关键在于Ceph属于一种分布式存储集群,这使得扩展更便利、能够在不牺牲性能的前提下消除单点故障,且提供涵盖对象存储、块存储以及文件存储的统一存储体系。
很明显,Ceph与云原生环境彼此兼容的,我们也可以利用多种方法部署一套Ceph集群,譬如使用Ansible。我们可以部署一套Ceph集群,并使用CSI与持久卷声明来提供指向Kubernetes集群的接口。
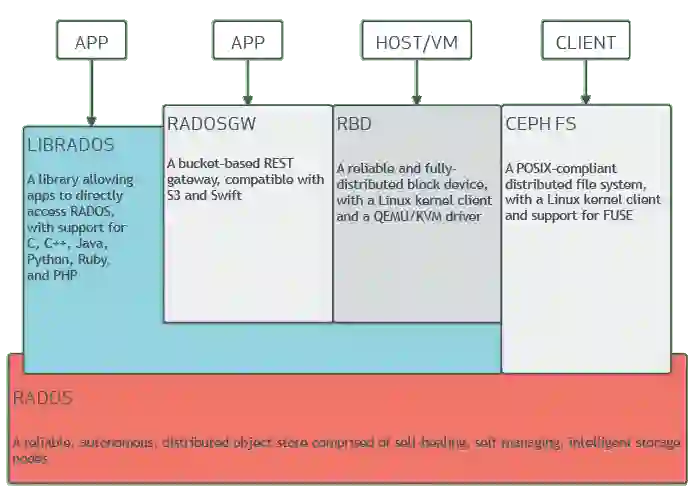
Ceph架构图
Rook
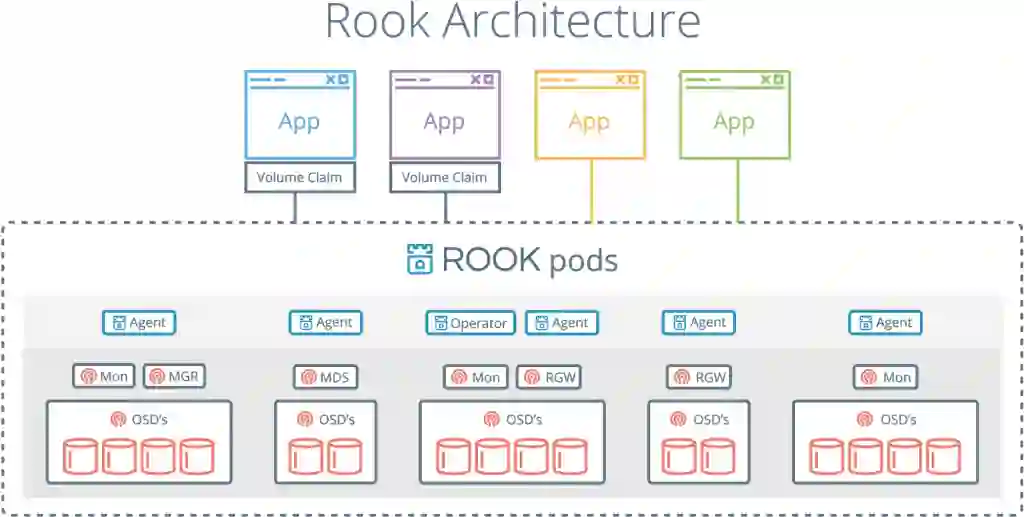
另一个有趣且颇具人气的项目是Rook,这是一项旨在将Kubernetes与Ceph融合起来的技术方案。从本质上讲,它将计算节点和存储节点放进了同一个集群当中。
Rook是一种云原生编排器,并对Kubernetes做出扩展。Rook允许用户将Ceph放置在容器内,同时提供卷管理逻辑以立足Kubernetes之上实现Ceph的可靠运行。Rook还使本应由集群管理员操作的多种任务完成了自动化实现,其中包括部署、引导、配置、扩展以及负载均衡等等。
Rook可以像Kubernetes一样使用yaml文件来部署Ceph集群。这种文件以高级声明的形式存在,负责为集群管理员提供所需要的全部内容。
Rook在集群启动完成后,即开始进行实时监控。Rook将以操作端或者控制端的姿态确保yaml文件中所声明的状态始终正常。Rook运行在一套协调的逻辑循环中,该循环将观察运行状态并根据检测到的异常采取响应。
Rook自身不具备持久状态,也不需要单独管理。这,才是真正与Kubernetes设计原则相符的存储资源管理方案。
Rook凭借着将Ceph与Kubernetes协同起来的强大能力而颇受欢迎,在GitHub上获得近4000颗星,1600多万次的下载,并吸引到100多名贡献者,现已进入CNCF孵化阶段。
Longhorn
Longhorn项目是Rancher Labs推出的开源的基于云和容器部署的分布式块存储新方式。Longhorn遵循微服务的原则,利用容器将小型独立组件构建为分布式块存储,并使用容器编排来协调这些组件,形成弹性分布式系统。
如今,基于云和容器的部署规模日益扩大,分布式块存储系统也正变得越来越复杂,单个存储控制器上的volume数量在不断增加。2000年代初,存储控制器上的volume数量只有几十个,但现代云环境却需要数万到数百万的分布式块存储卷。存储控制器变成了高度复杂的分布式系统。
Longhorn充分利用了近年来关于如何编排大量的容器和虚拟机的核心技术。例如,Longhorn并没有构建一个可以扩展到100,000个volume的高度复杂的控制器,而是出于让存储控制器简单轻便的考虑,创建了100,000个单独的控制器。然后,我们可以利用像Kubernetes这样的最先进的编排系统来调度这些独立的控制器,共享一组磁盘中的资源,协同工作,形成一个弹性的分布式块存储系统。
Longhorn基于微服务的设计还有很多其他优势。因为每个volume都有自己的控制器,在升级每个volume的控制器和replica容器时,是不会导致IO操作明显的中断的。Longhorn可以创建一个长期运行的工作来编排所有live volume的升级,同时确保不会中断系统正在进行的操作。为确保升级不会导致意外的问题,Longhorn可以选择升级一小部分volume,并在升级过程中出现问题时回滚到旧版本。这些做法在现代微服务应用中已得到广泛应用,但在存储系统中并不常见。希望Longhorn可以助力于微服务在存储领域的更多应用。
结 语
对于实际应用层面出现的任何问题,最重要的自然是判断需求、设计系统或者选择适当的工具。同样的道理也适用于云原生环境。虽然具体问题非常复杂,但也必然会出现大量工具方案尝试解决。随着云原生世界的持续发展,我们可以肯定,新的解决方案将不断涌现。未来,一切都会更加美好!

福利
扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

推荐阅读:
如何用30分钟快速优化家中Wi-Fi?阿里工程师有绝招
趣挨踢 | “菜鸟”程序员和“大神”程序员的差别竟然这么大...
云漫圈 | 女生适合做程序员吗?
Kubernetes 调度器实现初探
李沐团队新作Gluon,复现CV经典模型到BERT,简单好用 | 强烈推荐
日本乐天要求员工学编程,AI 进中小学课堂,全民编程时代来了!
做了四年以太坊核心开发者, 以太坊升级了, 我也该离开了……




