"戈登•贝尔”奖与隐式求解器
点击上方“中国计算机学会”轻松订阅!
来源:《中国计算机学会通讯》2017年第10期《专题》
“戈登·贝尔”奖(ACM Gordon Bell Prize)设立于1987年,由高性能计算应用领域的先驱——戈登·贝尔(Gordon Bell)先生发起,每年颁发一次,以表彰世界范围内高性能计算应用领域的杰出成就,特别强调奖励高性能计算应用于科学、工程和大型数据分析领域的创新。
戈登·贝尔(Gordon Bell)
他的主要贡献并不是高性能计算应用,他是计算机系统结构设计师。他于1960年加入DEC(Digital Equipment Corporation),是DEC公司的技术灵魂,设计和主持开发了世界上第一款小型机——PDP系列小型机,开创了小型机市场。1972~1983年任DEC公司工程部门副总裁,主持开发VAX系列小型机。1986~1987年期间,贝尔参与创立了美国国家科学基金委(NSF) 的计算机与信息学部并担任助理主任。在其任内,他积极推动高性能计算应用的发展,并于1987年设立“戈登·贝尔”奖 (ACM Gordon Bell Prize),每年颁发一次。
值得一提的是,1972年他提出了为计算机划代提供依据的贝尔定律(Bell¡¯s Law):每隔大约10年,就会出现采用新开发平台、新网络、新人机交互接口的新一代计算机,这种计算机价格更便宜、尺寸更小,将会形成新的应用与产业。过去半个世纪,从大型机到小型机,到工作站,到个人计算机,到笔记本,到智能手机,到今天的物联网,贝尔定律一次又一次得到了印证。
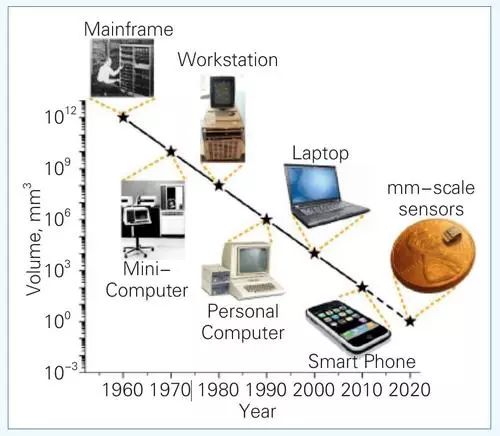
http://web.eecs.umich.edu/faculty/blaauw/research/M3-Michigan-Micro-Mote.html
戈登·贝尔奖的历史与发展
戈登·贝尔奖的设立,见证了并行计算的硬件架构和应用软件经历的一次历史性重大变革。在20世纪80年代,主流的高性能计算应用大多立足于以“克雷”(Cray)系列为代表的向量机,全系统只有少量的处理器,但每个处理器都具备强大的向量并行处理能力。进入80年代中期,基于简单处理器的集群架构开始崭露头角,单系统包含上百甚至上千个处理器。按照Amdahl定律,程序通过并行获得的性能提升受限于程序中的串行部分。假设程序中的串行部分占整体运行时间的10%,那么通过并行获得的性能提升的上限就是10倍。在当时看来,那些动辄包含成百乃至上千个处理器的并行计算机能否在应用中真正发挥威力,是一个值得怀疑的问题。
Amdahl定律、Gustafson定律
1960年代人们开始用互连网络将多个处理器连接起来以实现更快的计算机,但对于这种多处理器系统能达到的加速效果却无法判断。1967年Gene Amdahl在美国信息处理学会(AFIPS)的年度学术会议上提出了一个并行计算加速模型,解决了困扰人们的问题。Amdahl巧妙地把程序分为只能串行执行部分s与可被并行加速部分p(s+p=1),于是在N个处理器的并行计算机上就可以得到如下加速比:
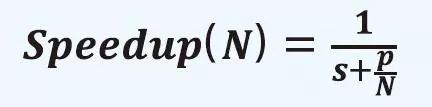
这就是著名的Amdahl定律。该定律描述了一个非常简洁优美的并行程序加速模型,但却推导出一个悲观的结论——不管N有多大,任何程序的加速比都存在上限,也就是1/s。这导致在很长一段时间内人们都认为没有必要研制大规模并行计算机。1988年,John L. Gustafson在Communications of the ACM上发表论文,提出了Gustafson定律。该定律的核心在于打破了Amdahl定律中任务量固定的假设(即s+p=1),提出计算固定时间完成的任务量(s+p*N)来得到可扩展的并行加速比:
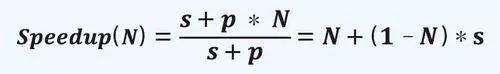
根据Gustafson定律,由于不限制任务量,所以可以通过扩大问题规模,增加p*N工作量来提高并行计算加速比,可以说是解放了人的思想。1988年以后,并行计算机的规模越来越大,解决问题的规模也越来越大。例如美国ECP计划指出,从P级计算到E级计算,晶体管性能只能提高50%,而并行度要提高670倍,也正是Gustafson定律的体现。
1990年,密西根州立大学的博士生孙贤和(现为伊利诺理工大学教授)与倪明选(现为澳门大学教授)在Supercomputing会议上提出了一种Memory-Bounded并行加速模型,成功地统一了Amdahl定律与Gustafson定律。该模型后被称为“Sun-Ni’s Law”,写入并行计算教科书。
1985年,IBM数值分析专家艾伦·卡普(Alan Karp)在一个学术会议上看到nCUBE、Thinking Machines等创业公司推出了拥有上千个处理器的并行计算机。他对此充满怀疑,并通过电子邮件的方式向整个科学计算领域提出了卡普挑战(Karp Challenge),宣称10年内将为任何在三个实际应用上实现200倍并行加速的研究者提供100美元的奖金。在两年的时间里,卡普并未收到任何正式的回应。而从当时发表的公开工作来看,大部分的工作取得的并行加速也都只在十几倍左右,而且大多是不具备太多实际意义的小儿科问题。
1987年,为了更好地推动并行计算发展,正在美国国家科学基金会(NSF)计算机与信息学部任职的戈登·贝尔先生在卡普挑战的基础上设立了戈登·贝尔奖,奖金额度从100美元增加到1000美元,每年颁发给取得最高并行加速比的研究团队(早期有当年的获奖工作的性能至少比上一年提升两倍的要求)。同年末,来自美国Sandia国家实验室的古斯塔夫森(Gustafson)等人在包含1000个处理器的nCUBE超级计算机上,针对流体动力学、结构力学以及地震波传播三大科学计算的经典应用取得了502~637倍不等的并行加速,基本确立了并行计算应用于大规模科学计算问题的可行性。1988年,古斯塔夫森提出著名的Gustafson定律,打破了人们基于Amdahl定律的悲观看法,指出并行计算的追求不仅是“算得更快”(强可扩展性,strong scalability),还要“算得更大”(弱可扩展性,weak scalability)。
自戈登·贝尔奖设立以来,评定规则也在不断地演变,从最开始只关注可扩展性,到后来重视持续性能、性能功耗比、应用的实际求解时间等多个维度。2006年,戈登·贝尔奖正式由美国计算机学会(ACM)接管,2011年奖金额度增加至10000美元,成为国际高性能计算领域的标杆奖项。20多届戈登·贝尔奖的评定和颁发,也见证了20多年超级计算机和依托于超级计算机的高性能计算应用的飞速发展。从早期的GFlops到现在10PFlops量级的应用性能,无论是超级计算机硬件所能提供的计算能力,还是高性能计算的算法设计与软件技术,都取得了长足的进步。
从超级计算机的发展角度看,占据TOP500榜首的系统呈现出戈登·贝尔奖的连续获奖效应。例如,2002年排名首位的日本“地球模拟器”(Earth Simulator)1在当年的戈登·贝尔奖评选中斩获了包括最高性能奖在内的三个奖项,在2003年和2004年又连续获得了两个最高性能奖。2005年名列第一的蓝色基因(BlueGene/L)系统2,也在2005~2007年连续三次获奖。值得一提的是,性能并不是戈登·贝尔奖评奖的唯一标准。评委们会综合考虑应用的实际价值、难度以及各项工作中提出的方法的创新性和通用性。2012年的戈登·贝尔奖评选充分体现了这一点。当时入围的工作有两项,都是天体模拟的应用:一个在“红杉”(Sequoia)3上进行,取得了13.94PFlops的性能和69.2%的效率;另一个在“京”(K Computer)4上进行,取得了5.67PFlops的性能和50.2%的效率。尽管前者的应用性能和效率都更好,但是最终“京”上的工作因为取得了对应用问题更快的模拟速度而获奖。由此可见,对于实际应用,单纯的性能不能说明所有的问题,对技术的促进才是终极目标。
从参与程度看,美国和日本是戈登·贝尔奖最有力的角逐者。欧洲的超算中心(例如德国的尤里西超算中心)有少量的工作入围。与上述国家相比,我国的高性能计算应用水平相对滞后,除了2013年由国防科学技术大学参与的地震波模拟应用曾经入围之外,2016年之前尚没有任何入围和获奖的记录。而我国的超级计算机已经先后多次问鼎TOP500榜首,在此基础上,如何尽快提升我国高性能计算的应用水平,充分发挥现有硬件平台的计算能力,成为亟待解决的问题。
戈登·贝尔奖与隐式求解器
在以大气动力学模拟为代表的大型科学与工程计算应用中,偏微分方程的数值求解十分关键,高效的求解器往往扮演着“发动机”的角色。众多求解器算法大致可以分为两类:显式求解器和隐式求解器。其中,显式求解器相对简单,容易实现并行,但稳定性差,时间步长依赖于空间分辨率,在大规模并行环境下实际问题的求解能力呈现下降趋势。相对而言,隐式求解方法稳定性高、鲁棒性好,但由于需要求解大型线性或非线性系统,高度的复杂性制约了其发展和普及。
隐式求解器的创新和应用是戈登·贝尔奖的一个重要风向标。对1999~2015年戈登·贝尔奖的获奖成果进行分析,隐式求解器的发展大致可分为三个阶段。
第一阶段(1999~2004年):基于区域分解、多重网格或谱方法等的隐式求解器,在空气动力学、大气模拟、固体力学等应用中纷纷取得数千核的可扩展性,可求解数百万至数亿未知数的问题;隐式求解器的应用水平在“ASCI红”“地球模拟器”“ASCI白”等多核集群系统或者大型向量机上,被推进到极致。
第二阶段(2005~2010年):戈登·贝尔奖的关注重点不再是偏微分方程的数值求解问题,而是集中在分子动力学、第一性原理、N体计算等问题的高效求解方法和应用创新研究上。
第三阶段(2011~2014年):传统的并行隐式求解器既无法应用在配备了GPU、Intel Xeon Phi等众核处理器的集群系统上,也难以适应具有超过百万CPU核的超大型集群环境里。因此,在2011年和2013年获得戈登·贝尔奖的两项工作中,使用了稳定性条件苛刻但易于并行的显式求解器,分别在基于CPU-GPU架构的TSUBAME 2.05系统上以及具有157万CPU核的“红杉”系统上,进行了极端尺度的材料科学相场模拟和云状空化模拟。
直到2015年,百万核并行环境下隐式求解器的设计问题取得突破:来自美国德克萨斯大学奥斯汀分校(UT-Austin)等单位的研究团队提出一套复杂的嵌套多重网格方法,并在此基础上研制出全球首个具有百万核可扩展能力的全隐式求解器,该求解器部署于“红杉”系统,扩展至整机157万CPU核,在地幔模拟中取得巨大成功。然而,以“天河二号”“神威·太湖之光”为代表的大型众核系统已经具有数百万甚至上千万的计算核心,如何设计隐式求解器,从而充分发挥此类系统的强大计算能力,仍是亟待解决的挑战性难题。
2016年度获奖工作
由我国五家研究机构合作完成的工作“千万核可扩展大气动力学全隐式模拟”获得了2016年度戈登·贝尔奖。该项研究工作始于2007年,最早的研究成果发表于2010年。在这十年间,研究团队分别在美国的“蓝色基因L”,我国的“天河一号A”“天河二号”等系统上完成了数千核至上百万核可扩展模拟。面向大气模拟的浅水波问题和非静力欧拉问题,在显式、隐式求解器上设计开展了多项研究。基于前期的研究积累,2016年,研究团队攻破了异构众核极大规模并行环境下隐式求解器设计的难题,深入开展了显式、隐式求解器的比较性研究,应用于非静力大气动力学模拟,取得了具有影响力的研究成果。
从技术上分析,隐式求解的主要开销在于大型离散线性系统求解。不同于传统意义上的代数线性系统,此处待求解的系统具有明确的数学物理特性,即来自全可压缩欧拉方程的离散化,因此,隐式求解器的设计应该充分利用原始问题的数学、物理和几何信息。我们采用迭代法(iterative method)与预条件子(preconditioner)相互结合的策略进行求解,其中预条件子扮演了核心角色。好的预条件子不但能够大幅度加速迭代收敛,而且开销不大,易于并行。可以说,整个隐式求解器的设计成败主要取决于预条件子的优劣。
国际主流的大型众核系统至少包含两个层次的并行度:一是进程级的并行度,通常可以达到数万至数十万量级;二是线程级的并行度,往往可以达到数十至数百量级。以“神威·太湖之光”为例,如果采用“核组”作为进程划分单位,进程级和线程级的并行度分别为163840和65,总并行度达到千万量级。我们考虑采用“问题分离”(separation of concern)的思想:如果针对进程级和线程级的并行度分别设计两套高效的预条件子,并且将二者巧妙结合从而形成一个整体,则有希望设计出适应于大型众核系统的预条件子。
在进程级方面,预条件子的设计可以借鉴传统CPU集群系统上的成功先例,最具代表性的工作就是2015年度的获奖工作。该工作的主要创新是开发了一套嵌套多重网格方法,包括模型级、多项式级、几何级和代数级的多级嵌套结构,可以有效处理高度各向异性的非线性不可压斯托克斯问题,成功应用于地幔流动模拟,在“红杉”上扩展至整机157万CPU核。然而,该工作并不适用于大型众核平台。原因是该工作所采用的多重网格方法具有较多的层数,一般达到15~20层,从而使粗网格问题规模很小,甚至需要采用直接法;该方法由于任务粒度的问题,很难做到较好的负载均衡,更难在此基础上引入线程级的并行。因而,我们考虑以区域分解方法(domain decomposition method)6为核心构造进程级求解器。区域分解方法的类型很多,其中重叠型加法Schwarz预条件子算法由于其内在的天然并行性非常适合分布式并行系统。而且限制型Schwarz算法进一步将通信开销缩减了一半,同时能获得优于传统重叠型加法Schwarz算法的收敛性,在实际应用中备受青睐。此外,还可以进一步在预条件子中补充粗网格矫正,从而改善此方法在大规模并行环境下的可扩展性和收敛性。

图1 千万核可扩展隐式求解器的核心设计思想示意图
结合前期的研究经验,我们最终构造了一类瀑布型的多重区域分解算法作为进程级的预条件子,如图1(a)所示。该预条件子的层数依具体问题可以控制在3~6层,有效地降低了多重网格的复杂度,每一层均可以进行一致的区域分解剖分,在负载均衡和数据局部性上具有优势。多重网格的层间依赖采用“乘法型”方式处理,充分保证收敛效果,在层内的区域分解则按照“加法型”方式进行,从而最大限度地实现大规模并行。此外,瀑布型多重网格可以进一步将每个计算层次的“磨光”操作次数减半,而限制型区域分解方式则可以将进程间的通信开销减半。在每一层的区域分解,均需要对重叠型的子区域问题进行求解,如果子区域问题的求解器支持众核多线程并行,并有优秀的计算性能,则可以融入其中,从而完成整个隐式求解器的设计。
在单颗GPU等众核处理器上设计稀疏线性系统的求解器,国际上已有大量的研究,但是都无法有效解决收敛性与并行性之间的矛盾。比如,可以在GPU上设计出性能优秀的Jacobi求解器,但是其收敛性与传统CPU上的求解器相比则相形见绌,因而其综合性能并不占优势。为了能够有效处理收敛性与并行性的平衡问题,我们考虑基于不完全LU分解(ILU)方法设计子区域求解器。国际上针对ILU的并行算法研究工作大部分基于分级调度策略。该方法虽然充分保留了原始串行算法收敛特性,但存在三个难以克服的劣势:一是并行度低,一般仅有10左右或者更低,难以适应众核环境;二是层间同步多,每一层并行任务完成后均需要进行同步,而大量线程同步在众核平台上开销较大,严重影响性能;三是数据局部性差,每个核的计算任务分配往往与具体问题相关,因此需要反复进行访存操作,制约了其在众核平台上的性能。2015年,人们提出了一套新的解决方案——异步并行ILU(PILU)方法,该方法虽然能够实现高度并行,但破坏了原有的数据依赖关系,需要多次数据扫描才能实现与串行算法同水平的收敛性,从而限制了其在众核平台的应用前景。
为了解决上述问题,我们针对申威众核处理器,提出了一套全新的基于几何信息的流水线ILU算法(GP-ILU),如图1(b)所示。该算法充分利用了原始问题的几何特性,最大限度挖掘了问题的内在局部性和并行性。通过对子区域进行合理切分,并将从核核组阵列与计算数据进行合理映射,可大幅改善数据局部性,通过进一步挖掘潜在的数据并行逻辑,结合双缓冲等策略,并利用申威处理器的寄存器通信机制,可有效地实现类似三维“多米诺骨牌”的流水线并行,显著提高访存效率。经过实测,GP-ILU算法在神威平台单个众核核组上比原始串行算法快数十倍。
我们选择三维非静力大气动力学斜压不稳定性实验作为测试算例,进行了强、弱可扩展性测试,测试结果如图2所示。在强可扩展性测试中,分别使用2公里和3公里的分辨率规模,扩展至整机,并行效率分别达到67%和45%。无论是扩展处理器核数,还是并行效率,相对于上一年度获奖成果均有大幅度提升。在弱可扩展性测试中,隐式求解器相对于显式求解器的实际模拟能力(用SYPD即“模式年每天”衡量)有大幅度提升,并且随处理器核数增多,分辨率增大,隐式求解器的优势愈发明显,在最高的488米分辨率下,对应的未知数个数达到7700多亿,隐式求解器的模拟能力相对于显式求解器提升89.5倍。值得一提的是,如果仅用持续浮点性能来衡量,显式求解器能够取得26PFlops的性能,隐式求解器则为7.95PFlops。看上去,隐式求解器峰值性能更低,但其实际模拟速度则大幅度领先。

图2 大规模并行测试结果
展 望
高性能计算是世界科技大国竞相角逐的战略制高点,而戈登·贝尔奖则可视作世界高性能计算领域的一颗明珠。此次获奖,虽然是我国的第一次,但我们相信,绝不是最后一次。在国家相关部门的持续、大力支持下,在我国并行计算前辈们的关怀和鼓励下,国内有更多优秀的高性能计算应用正在不断涌现,我国高性能计算应用水平正在不断提高,一定会取得更多具有世界影响力的研究成果。
脚注和参考文献请查看【阅读原文】。
作者 :

杨 超
CCF高级会员。中国科学院软件研究所研究员、博士生导师。研究方向:科学与工程计算、高性能计算等。
yangchao@iscas.ac.cn

薛 巍
CCF高级会员,CCF信息存储技术专委会委员。清华大学计算机科学与技术系副研究员。研究方向:大规模科学计算。
xuewei@tsinghua.edu.cn

付昊桓
清华大学地球系统科学系副教授,国家超级计算无锡中心副主任。研究方向:面向地学的高性能计算。
haohuan@tsinghua.edu.cn

尤洪涛
CCF专业会员。国家并行计算机工程技术研究中心副研究员。研究方向:高性能计算系统软件。
edmundyou@163.com

王兰宁
北京师范大学全球变化与地球系统科学研究院教授。研究方向:数值预报与大气环流模拟。
wangln@bnu.edu.cn



