超越MobileNetv3!Facebook提出FP-NAS:搜索速度快,精度更高
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达


Facebook提出了自适应采样方法和一种由粗到细的混合分布搜索方法,同时在搜索空间引入了ResNeSt的SA模块,表现SOTA!性能优于BigNAS、EfficientNet和FBNetV2等网络,
作者单位:Facebook AI。
1、简介
可微神经网络架构搜索(NAS)要求将所有层选择同时保存在Memory中。这限制了搜索空间和最终架构的大小。相比之下,概率NAS(如PARSEC)通过高性能架构学习分布,并且只使用训练单个模型所需的内存。但是,它需要对许多体系结构进行采样,从而使其在广阔的空间中进行搜索的计算量很大。
为了解决这些问题,Facebook AI团队提出了一种适合于分布熵的采样方法,在开始时抽取更多样本以激励搜索,并随着学习的进行而减少样本。此外,为了在多变量空间中快速搜索,从一开始就通过使用因子分解分布提出了一种从粗到精的策略,该策略可以将体系结构参数的数量减少一个数量级以上。
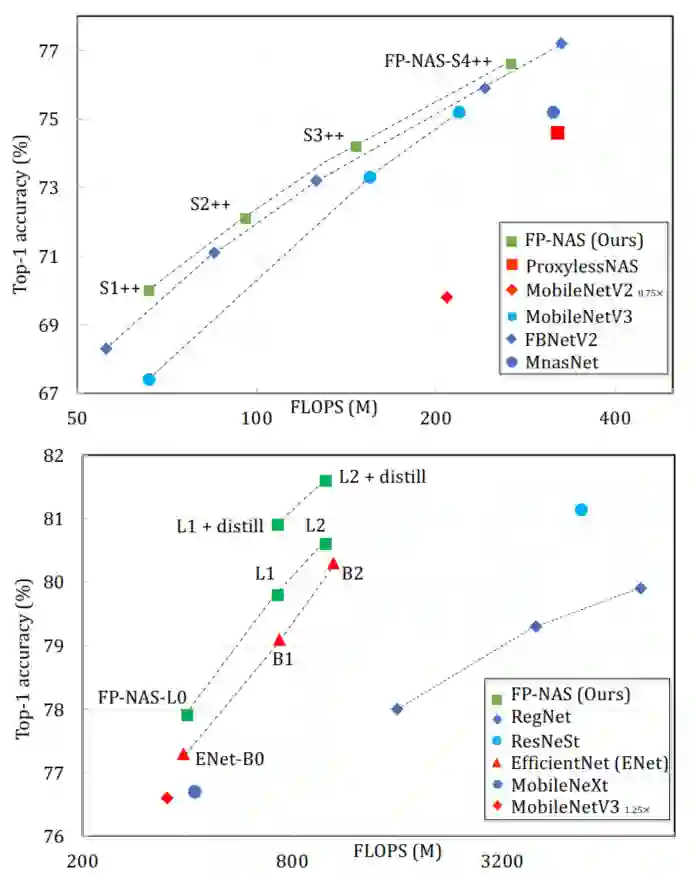
FP-NAS与PARSEC相比,它可以减少64%的架构采样,搜索速度提高2.1倍。与FBNet-V2相比,FP-NAS的速度提高了1.9-3.6倍,并且搜索的模型优于ImageNet上的FBNet-V2模型。FP-NAS允许将FBNet-V2空间扩展至更宽(即更大的通道选择)和更深(即更多的块),同时添加Split-Attention Block并启用对拆分数目的搜索。搜索大小为0.4G FLOPS的模型时,FP-NAS比EfficientNet快132倍,并且搜索到的FP-NAS-L0模型比EfficientNet-B0精确度高0.6%。在不使用任何架构替代或扩展技巧的情况下直接搜索高达1.0G FLOPS的大型模型。同时FP-NAS-L2模型具有简单的蒸馏功能,比BigNAS-XL的蒸馏性能高出0.7%,而FLOPS却更少。
2、相关研究与分析
2.1、人工设计模型
构建ConvNet的传统方法是设计可重复的构建块,并将它们堆叠起来形成深层模型,典型人工设计模型有ResNet、DenseNet和Inception等;
同时,随着移动设备的普及,手工设计轻量化模型也引起了人们的极大兴趣。轻量化模型使用了计算效率更高的块,如Inverted Residual Block和Shuffling Layer。
2.2、不可微神经结构搜索
早期的NAS方法不是基于强化学习就是基于进化。在以前的工作中,有研究者采用RNN控制器对架构进行采样,并对架构进行精度训练,作为更新控制器的奖励信号。但是它需要训练成千上万的架构,这在计算上是很难实现的;
类似地,在NASNet中,搜索CIFAR10和ImageNet的架构需要2000天。在基于进化的AmoebaNet中,搜索算法迭代地评估从种群中性能最好的架构进化而来的少量子架构,以加快搜索速度,但仍然需要训练数以千计的独立架构;
最近,EfficientNet通过在深度、宽度和输入分辨率上共同放大基于强化学习搜索的小模型来构建大模型;
Big-NAS使用蒸馏训练单个模型,并诱导不同大小的子模型,无需再训练或微调。
2.3、可微神经结构搜索
DARTS将离散搜索空间松弛为连续的,并通过梯度下降优化结构。虽然速度要快得多,但它需要实例化内存中的所有层,这使得在大空间中直接搜索大架构非常困难。因此,DARTS需要在搜索时使用模型的浅版本作为代理,并在评估时多次重复搜索的单元,以构建更大的模型。
通过路径修剪来改进DARTS,以减少在ProxylessNAS中的内存占用,更细粒度的搜索空间、层次搜索空间、更好的优化器,更好的架构采样器,平台感知,以及在通道上搜索和以一种内存高效方式的输入解析;
在GDAS中,提出了一种基于GumbelMax的可微采样器,每次只采样一个结构。减少了内存的使用,但所搜索的体系结构的性能低于基于进化的方法;
PARSEC提出了一种基于采样的方法来学习体系结构上的概率分布,同时也提高了内存效率。但是,为了得到好的搜索结果,需要不断地对大量的架构进行采样,这对于计算力的眼球非常高。
在本文中提出基于架构分布熵自适应地减少架构样本,大幅减少搜索时间,使搜索规模更大的架构成为可能。为了搜索轻量化模型,可区分的NAS方法被调整为对硬件敏感。
3、快速概率NAS
3.1、Background
本文的方法是基于PARSEC的扩展。在DNAS中,对于每一层l有一组候选操作O;每个操作o(·)都可以应用于输入特性 。离散选择被放宽为候选操作的加权和:
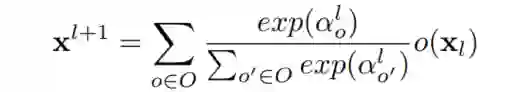
式中, 为第 层的架构参数。
比如说,结构A是由L层上的单个选择唯一定义的, 。引入了层操作选择的先验分布 ,其中结构参数 代表选择不同操作的概率。单个架构可以表示为从 中采样的 离散选择。因此,架构搜索转化为在一定监督下学习的 分布。这里假设不同层的选择是相互独立的,对一个架构A进行抽样的概率如下所示。
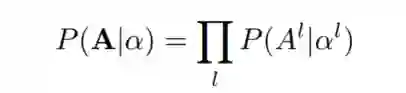
对于图像分类有图像X和标签y,概率NAS可以表述为通过贝叶斯蒙特卡洛法经验优化连续的结构参数 :
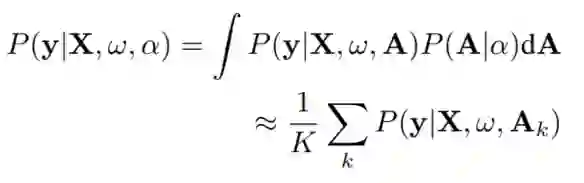
式中, 为模型权重。数据似然的连续积分是通过抽样架构和平均来逼近的。在抽样架构中可以通过估计梯度联合优化架构参数 和模型权值 。
为了缓解过拟合,作者分别对训练集和验证集计算梯度 和 。概率NAS是以迭代的方式进行。在每次迭代中,从 中提取K个架构样本 。
3.2、自适应结构采样
在PARSEC中整个搜索过程中采样固定数量的架构来估计梯度。但是对于不同大小的搜索空间可能不是最优的。在结构分布 搜索开始时,需要更多的样本来近似梯度。随着搜索的进行,质量分布集中在一个小的候选集合上;在这种情况下可以通过抽取更少的样本来减少搜索计算量。
本文提出了一种简单而有效的自适应于结构分布学习的抽样方法。在搜索过程中调整了结构样本的大小 与 的熵成比例。在搜索的前期,熵值很高促使更多的探索。之后,熵的减少作为一个候选操作子集被认为是更有价值的,并且抽样可能更偏向于他们。具体来说:
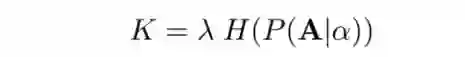
式中, 为分布熵, 为预定义的尺度因子。实验表明自适应采样可以在不降低搜索模型的前提下大大减少搜索时间。
3.3、多变量空间中由粗到细的搜索
每层操作 的搜索空间可以包含多个搜索变量,如卷积核大小、非线性和特征通道。在这种多变量空间中,当使用vanilla联合分布表示时,架构参数的数量是单个变量基数的乘积,随着变量的增加而快速增长。
例如,搜索空间有5个变量,包括kernel大小、非线性、Squeeze-Excite、MobileNetV3中的扩展率以及Channel。当它们各自的基数分别为3,2,2,6,和10时,使用 个参数。这里可以对大的JD进行因式分解,并使用多个小的分布得到一个更紧凑的表示。对于上面的5维搜索空间使用了5个小分布,总的架构参数可以显著减少到 ,降低了将近31倍。
形式上,在具有M个搜索变量的层操作 的搜索空间中,每一层都可以表示为一个M元组 。下面的层操作采用因子分解分布(FD):
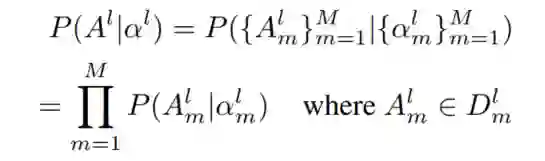
式中, 表示变量 的选择集合。与JD相比,FD大大降低了总体架构参数,在实际操作中往往会带来数量级以上的降低,可以大大加快搜索速度。但是FD忽略了搜索变量之间的相关性,只能支持粗粒度搜索。
例如,对扩展率和通道的搜索可能是相关的,因为在MobileNetV3中,MBConv Block中的内部通道是扩展率和通道的产物;当通道不深时,可能更倾向于使用较大的扩展率,但当通道已经很深时,可能不太倾向于使用较大的扩展率,因为它会引入过多的FLOPS,而且并不能提高分类精度。
因此为了支持快速搜索,提出了一种由粗到细的混合分布搜索方法,该方法采用混合分布的顺序,先用FD搜索若干个epoch,然后将FD转换为JD搜索接下来的epoch。实验结果表明由粗到细的搜索可以在不影响搜索模型性能的前提下加速搜索。
3.4、架构成本感知搜索
如果对架构成本没有任何约束,搜索倾向于大的架构,这更可能适合训练数据,但可能不适合对效率敏感的应用。为了在考虑目标成本的情况下搜索架构,作者采用了Hinge Loss,当架构使用的算力成本超过目标成本时,这将对架构造成惩罚,本文的Cost-Aware Loss包括数据可能性和模型计算成本:
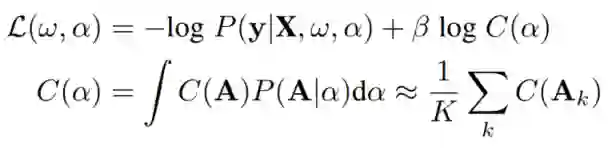
其中采样结构的Hinge Loss为, 表示体系结构成本系数, 为预期的体系结构成本,可以通过平均抽样体系结构的成本来估计。梯度 的透射率计算如下所示:
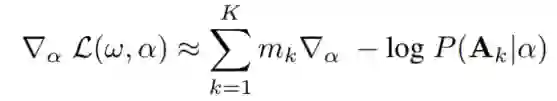
其中,
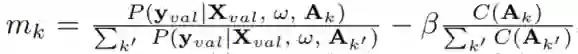
表示成本感知架构的重要权重。直观地说,架构参数的更新偏向于那些既能在验证数据上实现高数据似然性又能使用低延迟的架构。在搜索的最后,选择学习分布中最可能的一个作为最终的架构。
4、搜索空间
本文作者总共考虑下面4个不同的空间来搜索模型。

4.1、FBNetV2-F space
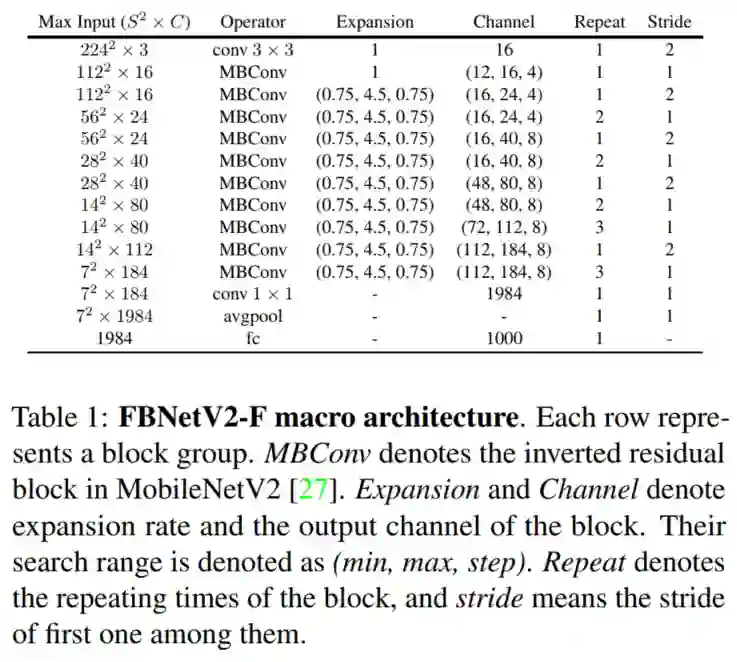
本文的大部分消融实验都在这个空间下进行的,其宏观架构定义在Tabel 1,微观架构定义在Tabel 2的第1行。它有多个搜索变量,包括卷积核大小、非线性类型、SE Block的使用、Block扩展率、Block特征通道,包含 种不同架构。
4.2、FBNetV2-F-Fine space
FBNetV2-F-Fine与FBNetV2-F的区别在于,每个MBConv块允许具有不同的微体系结构。FBNetV2-F-Fine包含 架构,比FBNetV2-F大 倍,可以看作是FBNetV2-F Space的细粒度版本。
4.3、FBNetV2-F++ space
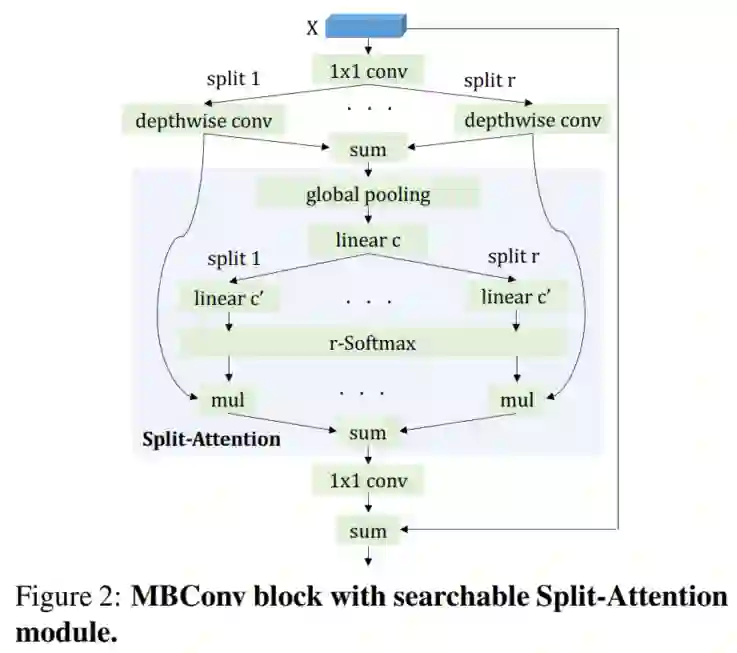
为了证明所提方法的搜索效率,作者扩展了微体系结构,在MBConv块中将SE Module替换为Split-Attention(SA),并将其表示为FP-NAS微体系结构(Tabel 2第2行);
SA模块将SE模块从一个分割扩展为多个分割。然而,在原始手工设计的ResNeSt模型中,选择了固定数量的分割(2、4),并且SA模块在所有ResNeXt块中使用。
假设没有必要在任何地方使用SA模块,这将导致计算开销。因此,通过扩展搜索变量no使SA模块完全可搜索。对于split有额外的选择{2,4},这意味着每个块组可以独立选择是否使用SA模块以及使用split分割的数量。注意,在no-of-split选项之间没有共享MBConv块的模型权值,这意味着当额外的选项{2,4}被引入时,supernet的总模型权值将增加一倍,这增加搜索的难度。
这里将这种带有SA模块搜索空间命名为FPNetV2-F++空间,比FBNetV2-F Space大 。
4.4、FP-NAS spaces
FBNetV2-F++ Space中最大的模型在输入大小为128时只使用了122M FLOPS。为了证明搜索方法的有效性,将从以下几个方面对FBNetV2-F宏架构进行了扩展。增加了搜索的Channel,使它更宽;还增加了组块的重复次数,使其更深。最后,通过增加输入图像的大小来提高图像的分类分辨率,从而提高识别性能。
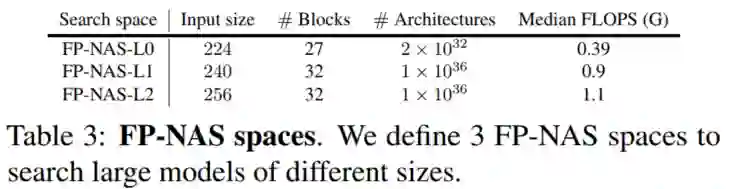
通过结合扩展的宏架构和FP-NAS微架构得到了3个大的FP-NAS空间,其中包含了不同大小的模型供搜索。还使用FP-NAS-L表示从这些空间搜索的模型。
5、实验
5.1、自适应采样的有效性
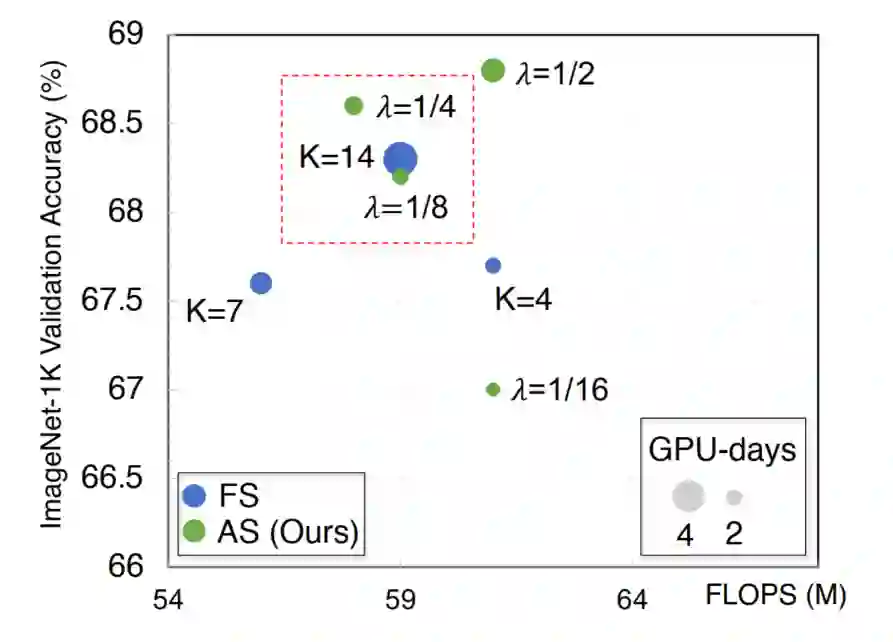
从上图可以看出,K的值与最终的结果之间有很强的相关性
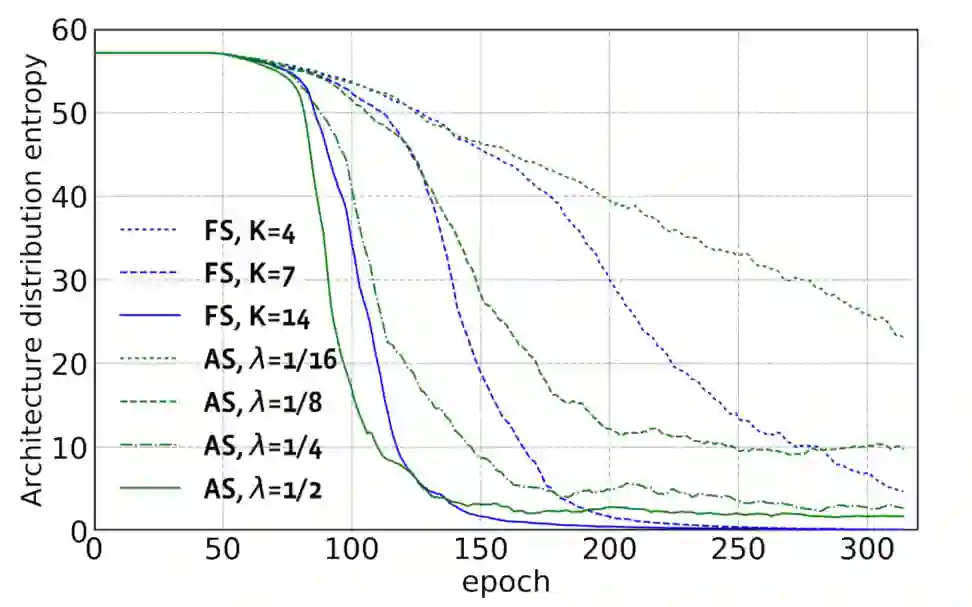
从上图可以看出,更大的K样品更多的架构,而分布熵降低更明显,这就意味着学习体系结构的分布是更有效。
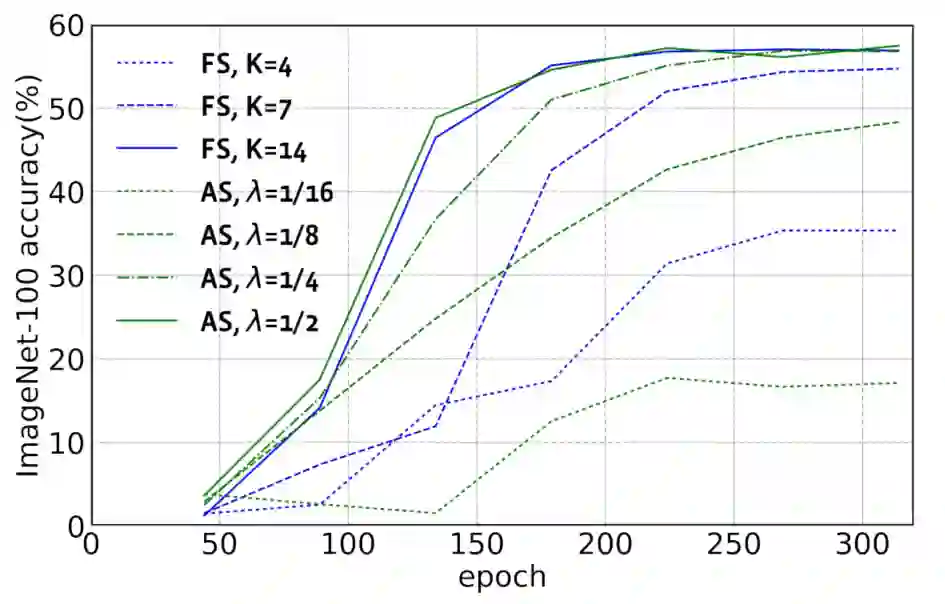
从上图可以看出,在每个epoch搜索结束时,k越大,架构参数和模型权值的联合优化就越有效。样本越多,越有助于更好地估计梯度,也能更快地学习分布,从而更频繁地对有前景的架构进行采样,更专注于更新与它们相关的模型权值。
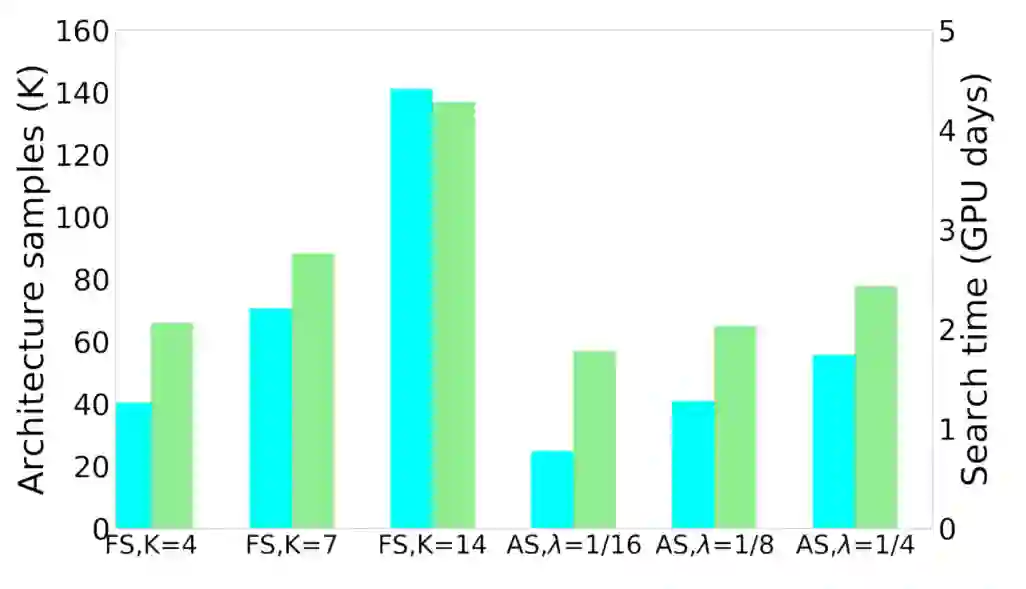
从上图可以看出,FS在K时的搜索计算代价几乎是线性增加的。
5.2、Split-Attention搜索模块
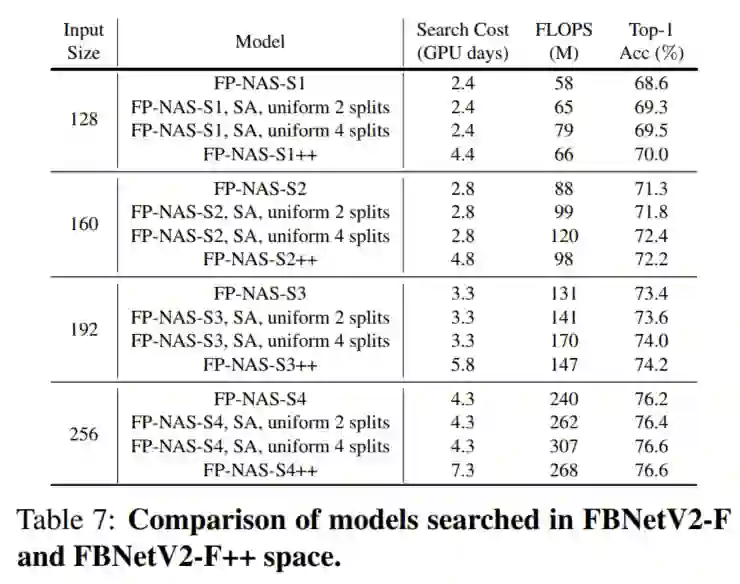
5.3、与其他方法的比较
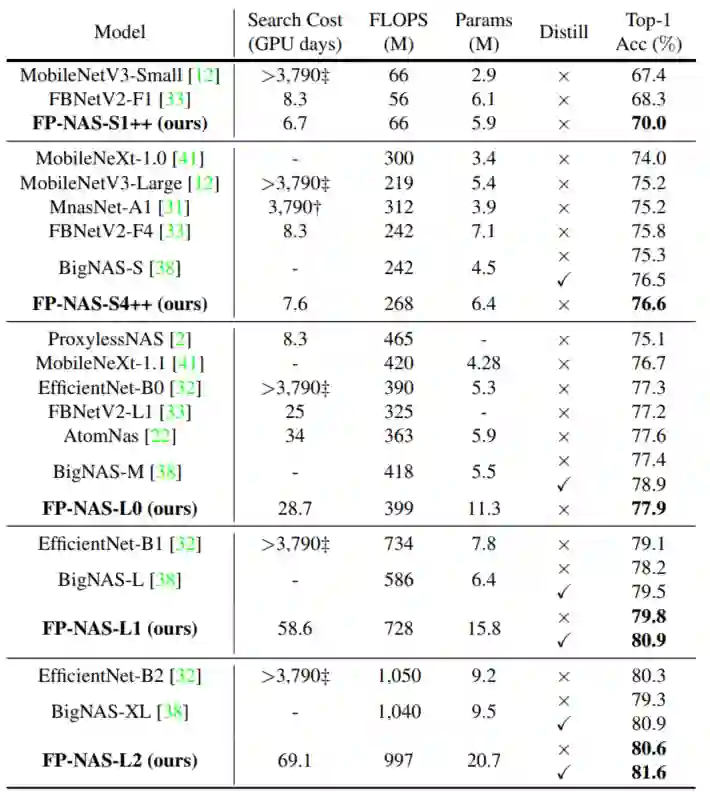
上表将FP-NAS模型与其他模型进行了比较。FP-NAS模型比其他模型显示了更好的ATC权衡。在上表中还比较了使用和不使用就地蒸馏的BigNAS模型。对于小型模型,FP-NAS-S4++不蒸馏已经和BigNAS-S模型的inplace distillation有相当的性能了。对于大型模型,基于vanilla distillation的FP-NASL2可以超越inplace distillation的BigNAS-XL大约0.7个百分点,但是基于vanilla distillation的FP-NASL2具有更低的FLOPS。
下载:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-NAS交流群成立
扫码添加CVer助手,可申请加入CVer-NAS 微信交流群,目前已满400+人,旨在交流AutoML、NAS等。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如NAS+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!

