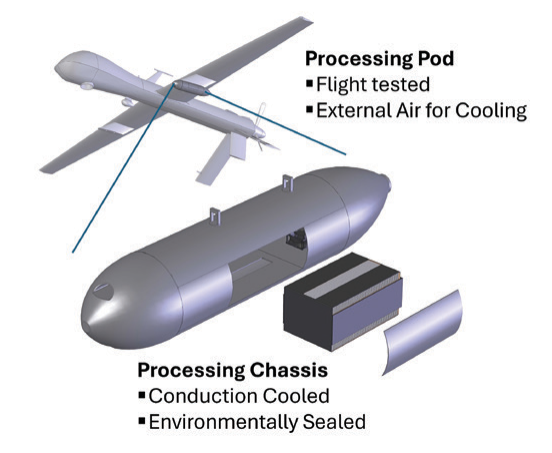
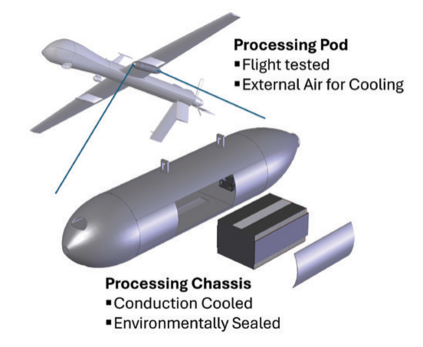
自主武器系统(AWS)的发展——有时也带有“致命性”标签,缩写为LAWS——多年来一直处于激烈讨论之中。众多政治、学术或法律机构及行为体都在辩论这些技术带来的后果和风险,特别是其伦理、社会和政治影响,许多声音呼吁严格监管甚至全球禁止。尽管这些武器备受公众关注且被认为影响重大,但“AWS”这一术语具体指代哪些技术以及它们具备何种能力,却往往出人意料地不明确。AWS可以指无人机、航空母舰、无人空中/地面/海上载具、机器人及机器人士兵,或计算机病毒等网络武器。
这种不确定性之所以存在,尽管(或许正是因为)已有大量定义试图从功能上(例如“一旦激活,自主武器‘无需操作员进一步干预即可选择和攻击目标’”:美国国防部,2023年:第21页)或概念上(源自对自主系统、人工智能或机器学习的理论化)来明确该术语。定义仍为不同类型的技术留下了广阔空间,并且结合关于人工智能的更广泛讨论,也为未来发展的潜力和预测提供了可能。除了术语的模糊性,这些系统在何种意义上以及在多大程度上可被称为“自主”的本质也依然含糊不清。尽管自动化能力的发展无疑在推进(Scharre, 2018; Schwarz, 2018; Packer and Reeves, 2020),人类能动性和干预方式的程度不断降低,但完全超越人类控制、因此被许多人担忧的完全自主武器,在很大程度上仍是一种概念上的可能性,而非实际的军事现实。
这些模糊性导致了巨大的意义空白,而这些空白又往往被想象所填充——这是新技术,特别是人工智能的常见做法(Suchman, 2023)。潜在的现实可以扮演重要角色,因为它们是将专业知识传递到社会其他领域(包括新闻、政策制定、研究、教育和民主决策过程)的工具。因此,关于AWS功能及其后果的看法,受到军事、国家和技术未来想象的启发和塑造。这些想象包括地缘政治情景、伦理问题、国家政策或科幻小说。在安全与军事政策中,这些不同现实之间的相互联系甚至被用作一种方法论——例如,“红队演练”——这意味着应用对潜在未来的创造性虚构描述来为实际决策提供信息(The Red Team, 2021)。另一种应用是兵棋推演,这是一种预见未来军事场景的方法,其起源至少可追溯至19世纪,但已适应当代技术和媒体环境,包括虚拟现实和使用大语言模型的基于人工智能的模拟(Goecks and Waytowich, 2024)。
自主武器的前提,被视为占据着一个自身特有的混合空间,这促使我们探索随之而来的无数现实。本书的基本原理认为,只有承认实际技术发展与其相关的愿景和虚拟场景之间持续而复杂的动态互动,才能理解所讨论的这些现实。正是在这种不确定性——想象、可能性和虚构在此交织——的背景下,自主武器变得极具影响力。它们激发出情感、话语、鼓动、(反)行动、投资、竞争、政策或技术与军事蓝图。
关于自主武器主题的出版物通常侧重于其法律、政治或伦理影响(例如,Bhuta等人,2016;Krishnan,2016),这是评估这些技术的第一层级。也有一些著作讨论了其独特的表征(Graae and Maurer, 2021),以及我们见证和体验它们的方式(Bousquet, 2018; Richardson, 2024)。这些著作的基础也基于前面概述的不同现实。本书引入另一种分析自主武器现实的方法,提出一种第二层级的方法:例如,一个伦理问题不仅仅被框定为伦理问题本身,即沿着提出以下规范性问题的思路:“自动化杀人机器会引发哪些道德问题?” 在本书建议的方法中,伦理问题反而被理解为一个促成因素,它有助于在大众文化、政治、新闻或研究中构建、传播和维持对致命性AWS的特定理解。简言之,伦理话语共同创造了其对象的现实。因此,本书所采取的视角将AWS的不同现实置于前台,进而旨在为现有的辩论揭示其(常常是隐含的)基本假设。
本书这篇引言性章节首先勾勒了军事装备日益自动化的技术和政治发展进程。这些发展在理论上被阐述为既具构成性又具述行性,以涵盖全球范围内在理论和实践中对AWS的动态变化和不同理解。随后,本章就这些现实提出了六点思考,有助于界定和巩固AWS的动态含义,这些含义往往在公众、军事和监管领域受到极大关注。章节最后概述了全书的结构并简要总结了各章的贡献。
全书各部分及章节内容
全书结构分为三个独立部分,分别探讨自主武器的当前现实。每个部分都从特定的视角范式分析自主武器:1. 叙事与理论,2. 技术与物质性,以及 3. 政治与伦理。每个部分的开篇由一位艺术家及其对自主武器的构想引入。这种划分基于对跨越这些领域所阐发的不同意义的分析,这些意义构成了AWS的现实,并强有力地影响着如何感知和对待这项技术。