近年来,国内的云计算市场增速明显,企业上云明显提速。客户的需求逐步从“资源型需求”转向“智能型 需求”及“业务型需求”,意味着 PaaS、SaaS 等各行业各场景的云解决方案将受到更多关注。尽管该市场 呈现出了广阔的前景,业务的庞大数量和场景种类夸张的多样性也意味着巨大的难度。随着市场的成熟上升, “一招鲜吃遍天”的套路相对于针对用户需求定制化的解决方案已不具优势,意味着在细分领域深耕的中小 型友商也具有瓜分市场的竞争力。因此,如何在保证市场占有率并支撑如此大量的业务的情况下,控制资源 和成本、保证交付效率和保证产品质量是云厂商要解决的核心难题。
另一方面,随着工业生产越来越强调智能化,大量传统行业开始积累领域数据,并寻求人工智能算法以解决 生产和研发过程中遇到的重复而冗杂的问题。这就意味着,人工智能算法在落地的过程中,将会面对大量不 同场景、不同需求的用户。这对算法的通用性提出了很高的要求。然而我们注意到,当前业界大部分人工智 能开发者,正在沿用传统的“小作坊模式”,即针对每个场景,独立地完成模型选择、数据处理、模型优化、 模型迭代等一系列开发环节。由于无法积累通用知识,同时不同领域的调试方法有所不同,这样的开发模式 往往比较低效。特别地,当前人工智能领域存在大量专业水平不高的开发者,他们往往不能掌握规范的开发 模式和高效的调优技巧,从而使得模型的精度、性能、可扩展性等指标都不能达到令人满意的水平。我们将 上述问题,称为人工智能算法落地的碎片化困境。
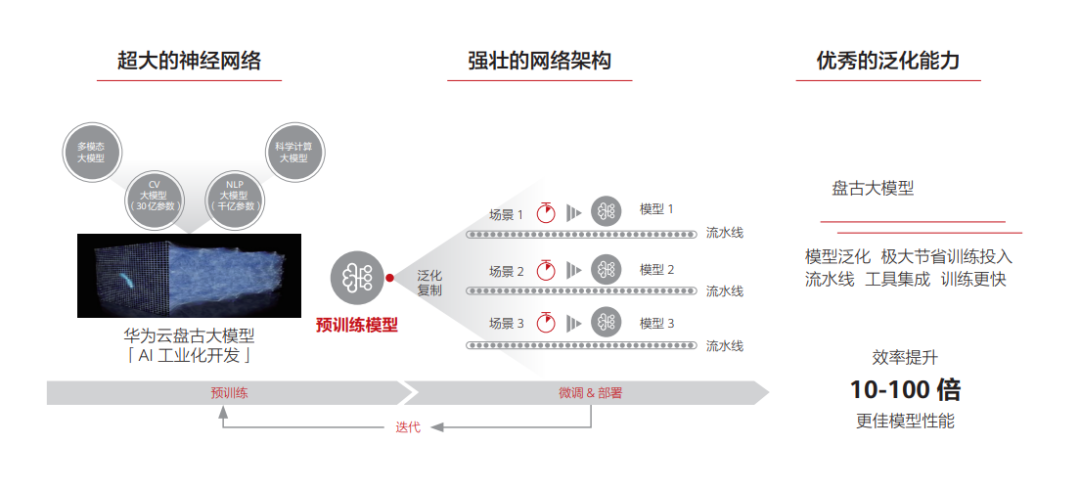
为了解决这个困境,预训练大模型应运而生。它收集大量图像、文本等数据,利用无监督或者自监督学习方 法将数据中蕴含的知识提取出来,存储在具有大量参数的神经网络模型中。遇到特定任务时,只要调用一个 通用的流程,就能够将这些知识释放出来,并且与行业经验结合,解决实际问题。近年来,预训练大模型相 关研究和应用呈井喷态势,大有一统人工智能领域的趋势。不过我们也应该看到,预训练大模型距离规模化 的商业应用,还有很长的路要走,这里不仅包含技术的演进,也包含商业模式的进化。按照我们的设想,大 模型是未来 AI 计算的“操作系统”,向下管理 AI 硬件,向上支撑 AI 算法,使得 AI 开发更加规范化、平民化。 我们希望通过编写《预训练大模型白皮书》,将我们团队在研究和落地中获得的经验总结下来,更好地促进 行业的进步。