论文链接
https://arxiv.org/abs/2403.18684
代码链接
https://github.com/Suffoquer-fang/scaling_dr
内容简介
扩展神经模型在广泛的任务中取得了重大进展,特别是在语言生成方面。以前的研究发现,神经模型的性能经常遵循可预测的扩展定律(Scaling Law),与训练集大小和模型大小等因素相关。这种发现在大规模实验成本越来越高的情况下很有价值。然而,由于检索指标的离散性质以及训练数据和模型大小在检索任务中的复杂关系,这种扩展定律在稠密向量检索中尚未得到充分探索。
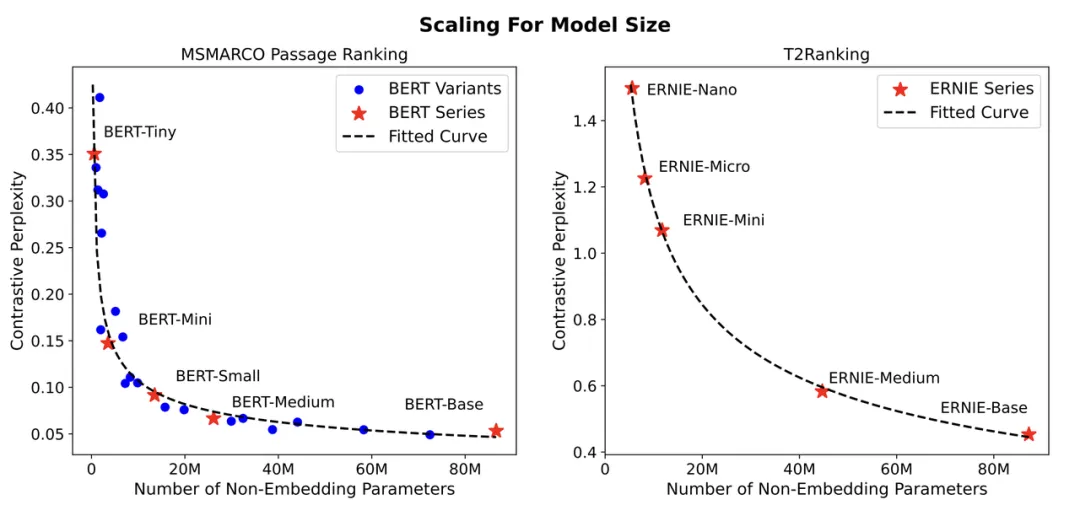
在本研究中,我们研究了稠密向量检索模型的性能是否像其他神经模型一样遵循特定的扩展定律。我们提出使用与训练损失函数类似的对比困惑度作为评估指标,并对具有不同参数大小的检索模型,在不同数量的标注数据设定下,进行了大量的实验。结果表明,在我们的设置下,稠密向量检索模型的性能遵循与模型大小和标注数量相关的幂律函数关系。此外,我们使用常用的数据增强方法生成训练数据,用来评估标注质量的影响。最终,我们展示了扩展定律在训练资源分配上的一个潜在应用。我们相信这些发现将有助于理解稠密向量检索模型的扩展效应,并为未来的研究工作提供有意义的指导。
扩展法则的研究可以追溯到一个世纪前。在20世纪20年代,一些语言学家发现,根据语料库中每个词的频率排序,词的频率与其排名的倒数成正比,这被广泛称为Zipf定律[2, 33]。随后在60年代,Gustav Herdan发现语料库中不同词的数量近似遵循语料库大小的函数,这可以用幂函数近似描述,通常称为Heaps定律[27]。这些基础性发现对语言学和信息检索研究产生了深远影响。例如,Zipf定律启发了若干统计检索模型的发展,而Heaps定律成为倒排索引估算的关键原则,这是许多检索系统的基础。 近期,随着语言建模从统计分析演变到语义表示的学习,扩展法则研究的重点也从分析文本统计转向大语言模型(LLMs)的训练动态。大量研究致力于考察不同因素如何影响模型性能,例如模型规模、数据量和计算能力[22]。这些研究结果揭示了模型性能与扩展因素之间精确的幂律关系,使研究人员和开发者可以在不实际构建模型的情况下,经验性地预测模型性能[1]。由于现代LLMs的训练需要大量时间和财务资源,这些扩展法则在实践中具有重要意义。 与语言建模类似,稠密检索模型在从统计分析向语义表示学习的转变中成为一个重要的里程碑[5, 26]。与传统的统计检索方法(如BM25[43])相比,稠密检索模型使用预训练语言模型初始化,并在注释数据上进行端到端的微调。它们能够捕捉查询和文档之间的语义相似性,并在性能上明显优于传统方法[31, 39, 46]。然而,研究人员发现,稠密检索模型的有效性对多个训练因素较为敏感[53, 56]。因此,在实际约束(如预算和延迟要求)下构建有效的稠密检索模型并不简单,需要更多关于稠密检索优化过程的见解。 在本文中,我们研究了稠密检索模型的扩展法则。尽管一些研究表明,在零样本稠密检索任务中,更大的模型表现出更好的泛化能力[35, 44],但据我们所知,尚无公开文献明确发现稠密检索模型的扩展法则。具体来说,我们面临两个挑战:(1)检索任务中的传统性能指标(如NDCG)是离散函数,难以稳定和平滑地反映模型性能的变化;(2)稠密检索的训练过程涉及多个相互关联的因素,如模型规模、注释规模和注释质量,使得难以单独分离每个因素的影响。为此,我们首先提出使用对比熵(contrastive entropy)作为稠密检索模型的质量评估指标。这个想法受到流行的对比排序损失和LLMs中token生成困惑度分析的启发。它测量从随机抽样的候选集中检索到相关文档的可能性,其结构与稠密检索模型的训练损失相似。这一指标的平滑特性大大促进了我们的后续分析。其次,为了分离模型规模和数据规模在稠密检索中的影响,我们在两个最大的网页搜索数据集(即MSMARCO和T2Ranking)上,使用不同预训练语言模型实现了非嵌入参数规模从0.5到8700万的模型。实验结果表明,在适当的实验条件下,稠密检索模型的性能相对于训练因素遵循精确的幂律扩展。图1展示了模型规模的幂律扩展。为了研究注释质量的影响,我们采用了几种LLMs和弱监督方法生成稠密检索模型的训练数据。结果表明,观察到的稠密检索扩展法则在不同类型的注释数据训练的模型中均有效。此外,我们展示了模型和数据规模的联合效应可以很好地用单一函数拟合和预测在一定范围内。这些函数可以用于在有限预算下找到最佳资源分配策略,可能为稠密检索模型的实际实现和绿色信息检索提供重要见解[47]。 本文结构如下。我们首先在第2节简要回顾相关工作。然后在第3节介绍我们的系统评估框架。在这个框架下,我们在第4节研究稠密检索的扩展法则,并在第5节展示其潜在应用。