Transformers在自然语言处理、计算机视觉和机器人技术等领域产生了深远影响,相比于其他神经网络,它们在这些领域的表现更加优秀。这篇调研报告将探索Transformer模型在强化学习(RL)中的应用,它们被视为应对不稳定的训练、信用分配、解释性不足和部分可观察性等挑战的有力解决方案。我们首先简要概述强化学习领域,接着讨论经典强化学习算法面临的挑战。然后,我们深入探讨Transformer及其变体的属性,并讨论这些特性如何适应解决RL中固有的挑战。我们研究了Transformer在RL的各个方面的应用,包括表示学习、转换和奖励函数建模,以及策略优化。我们还讨论了最近旨在提高Transformer在RL中解释性和效率的研究,包括可视化技术和有效的训练策略。通常,Transformer的架构必须根据给定应用的特定需求进行定制。我们为如何将Transformer适应于机器人技术、医学、语言建模、云计算和组合优化等多种应用,提供了一个广泛的概述。最后,我们讨论了在RL中使用Transformer的局限性,并评估了它们在此领域催化未来突破的潜力。
强化学习(RL)是一种学习范式,它通过从试错过程中获得的反馈来实现序列决策。它通常被形式化为马尔可夫决策过程(MDP),该过程为建模代理和环境之间的互动提供了数学框架。大多数RL算法优化代理的策略,选择能够最大化预期累积奖励的动作。在深度RL中,神经网络被用作函数近似器,用于将环境的当前状态映射到下一个动作,并估计未来的回报。当处理大型或连续状态空间时,这种方法非常有益,因为这会使表格方法的计算成本变得过高[169],并且在挑战性的应用中已经取得了成功[6, 90, 133]。然而,像卷积神经网络(CNNs)和循环神经网络(RNNs)这样的标准神经网络架构在处理RL中的长期问题上存在困难。这些问题包括部分可观察性[37],处理高维状态和动作空间的能力不足[10],以及处理长期依赖性的困难[22]。
在强化学习(RL)中,部分可观察性是一个挑战[104];在缺乏完整信息的情况下,代理可能无法做出最优决策。解决这个问题的典型方法是使用卷积神经网络(CNNs)和循环神经网络(RNNs)对代理的输入进行整合[160]。然而,RNNs倾向于忘记信息[142],而CNNs在处理过去时间步长方面的能力有限[75]。人们提出了各种策略来克服这个限制,包括门控机制、梯度裁剪、非饱和激活函数和操纵梯度传播路径[151]。有时候,人们会组合使用不同的数据模态,比如文本、音频和图像,为代理提供额外的信息[19, 89, 167]。然而,集成不同模态的编码器增加了模型的结构复杂性。在CNNs和RNNs中,也很难确定哪些过去的行动对当前的奖励有贡献[112]。这就是所谓的信用分配问题。这些挑战以及其他问题,如训练不稳定性,限制了大多数RL应用的范围,使得它们仅限于不切实际的虚拟环境。Transformer首次在2017年提出[174],并迅速对深度学习领域产生了影响[99],改进了自然语言处理(NLP)和计算机视觉(CV)任务的最新技术水平[33, 79, 144, 173, 217]。这种神经网络架构背后的关键思想是使用自我关注机制来捕捉数据中的长距离关系。这种在序列中模拟大规模上下文的能力,最初使得Transformer非常适合机器翻译任务。此后,Transformer已经被改进,用来处理更复杂的任务,如图像分割[144]、视觉问题回答[217]和语音识别[34]。
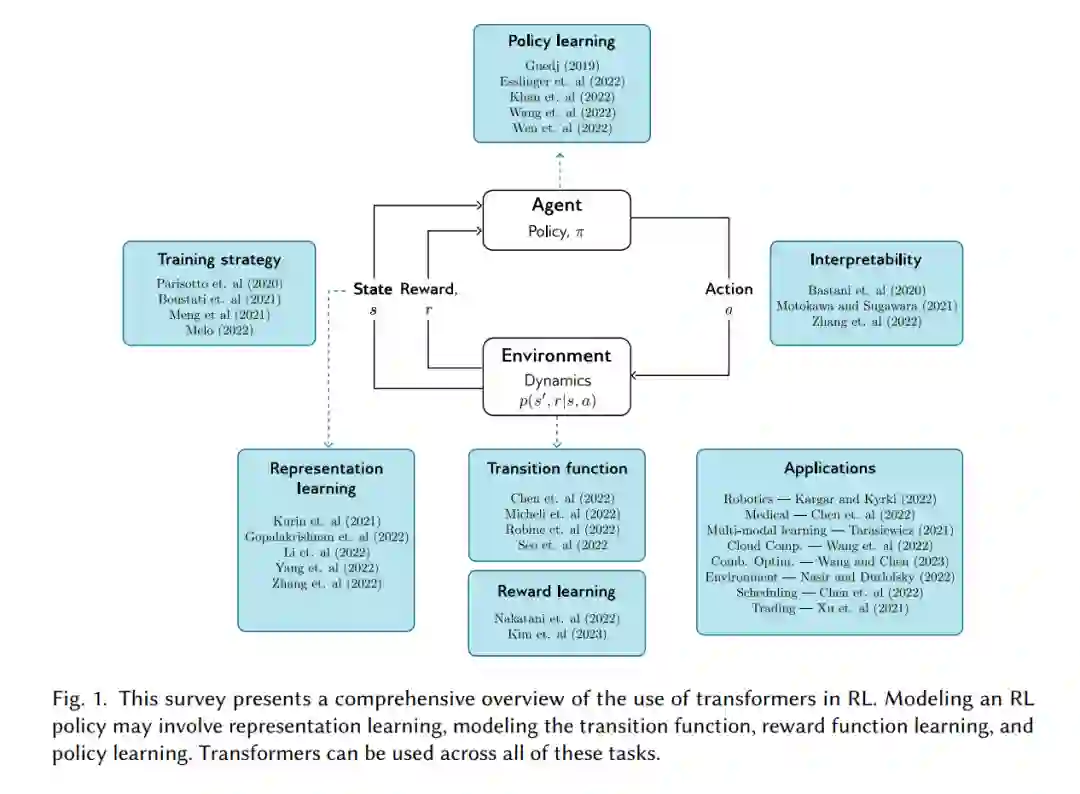
本文调研了在强化学习(RL)中使用Transformer的情况。我们首先为具有机器学习一般背景的读者提供了对RL(第2.1节)和Transformer(第2.3节)的简洁概述。我们强调了经典RL方法面临的挑战以及Transformer如何帮助解决这些挑战(第2.2节和2.4节)。Transformer可以以不同的方式应用于RL(图1)。我们讨论了如何使用它们来学习表示(第3节),模型转换功能(第4节),学习奖励函数(第5节)以及学习策略(第6节)。在第7节和第8节中,我们讨论了不同的训练和解释策略,而在第9节中,我们概述了使用Transformer的RL应用,包括机器人技术、医学、语言建模、边缘-云计算、组合优化、环境科学、调度、交易和超参数优化。最后,我们讨论了限制和未来研究的开放问题(第10节)。通过这项工作,我们旨在激发更多的研究,并促进RL方法在实际应用中的发展。
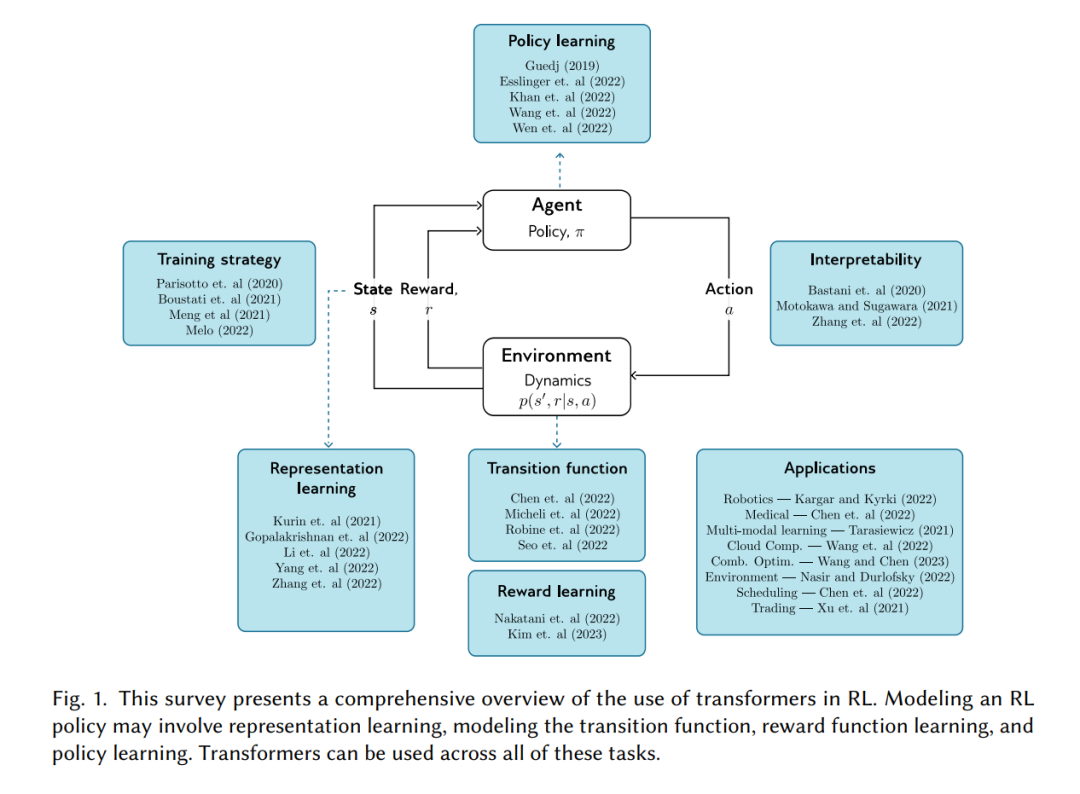
这篇综述探讨了在强化学习(RL)中Transformer的多种用途,包括表征学习、奖励建模、转换函数建模和策略学习。尽管原始的Transformer架构存在限制,但它可以被修改以适应许多RL应用。我们展示了Transformer的进步,这些进步扩大了RL应用到机器人技术、药物发现、股票交易和云计算等实际问题的范围。最后,我们讨论了RL中Transformer的当前限制和这个领域的正在进行的研究。考虑到它在处理部分可观察性、信用分配、可解释性和不稳定训练等问题上的多样性——这些问题在传统RL中常常遇到——我们预计Transformer架构将在RL领域继续受到欢迎。