
机器学习模型已经被证明在股票价格预测任务中表现出了优越的性能。给定股票的历史数据(如开盘收盘价格,最高最低价格等),时序模型通过优化预测值和真实值之间的损失进行训练。然而,金融数据存在稀缺性这一固有挑战,具体表现为低信噪比和数据同质性。这会给股票价格的准确预测带来重大障碍。
近日,来自中国科学技术大学以及阿里巴巴达摩院的研究团队,提出了一种利用人工智能生成数据样本(AI generated Sample) 来增强下游预测任务的新方法。利用基于Transformer的条件扩散模型,在大规模股票池(源域)数据上加噪和去噪进行训练。当面临特定的股票预测任务时,该模型可以通过编辑现有样本来增强训练过程。此编辑过程的强度可以改变,用来控制新生成数据更接近源域还是更接近目标域。大量的实验表明DiffsFormer可以应对数据稀缺的挑战并提高整体模型性能。论文地址:
https://arxiv.org/pdf/2402.06656.pdf
研究动机
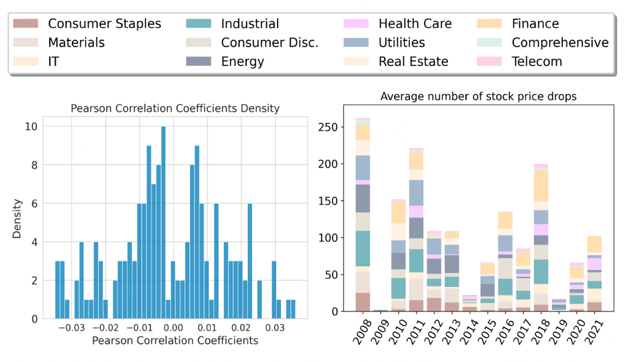
利用机器学习来进行自动股票价格预测需要大量的高质量数据,然而在金融任务中,数据往往是稀缺的。具体表现为: (1)低信噪比。股票因子和超额回报率之间的皮尔逊关系系数很低(绝对值低于0.03),因此特征和标签之间的关系很难预测,数据的信噪比较低。 (2)高同质性。同行业同板块的股票会表现出相似的行为,如同涨同跌。这种同质性会导致在样本量本就不多的股票池中,具有独特信息特征的股票数目进一步减少。 为解决上述问题,数据增强是最直接有效的途径。由于扩散模型在多个领域都取得了巨大的成功,因此我们提出将股票的历史表现建模为序列,并采用基于transformer的条件扩散模型生成新的股票序列。
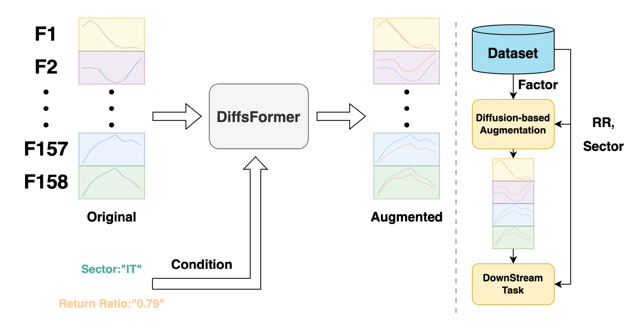
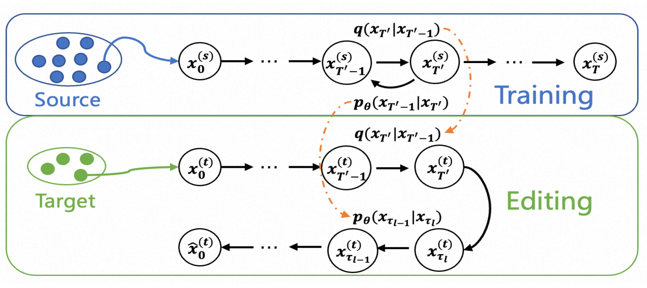
DiffsFormer框架会在多个市场的股票数据上进行预训练,希望能够刻画已经观测到的股票市场的潜在生成分布,并将这个额外的信息和知识迁移到目标市场的生成过程中。此外,由于数据的信噪比较低,因此扩散模型在去噪过程中难以从纯高斯噪声恢复到数据分布。为了缓解该问题,DiffsFormer并不会直接生成目标市场的序列,而是基于该市场已有的股票序列进行微小改动(编辑)。 ** DiffsFormer方法**
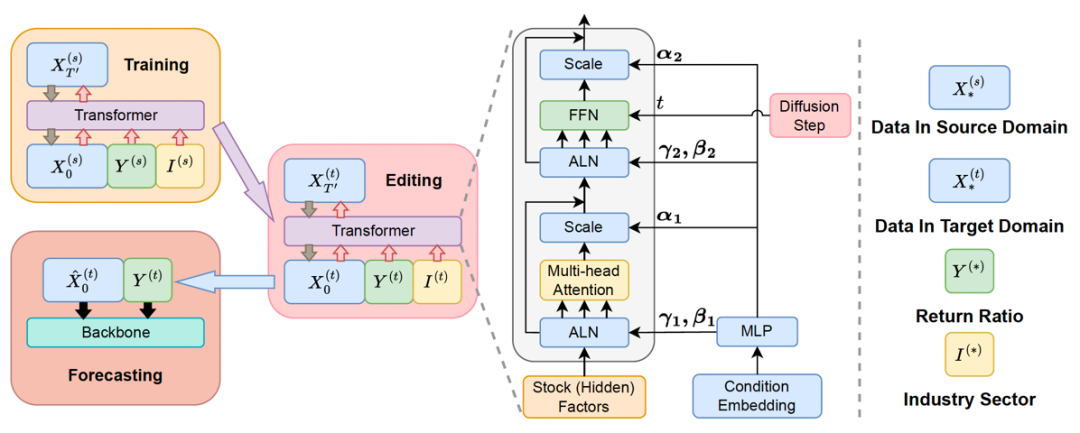
DiffsFormer的步骤主要可以分为三个阶段: 一、训练:在多个市场股票组成的源域数据上训练扩散模型,数据标签和板块信息作为扩散模型的条件。 二、编辑:在目标域数据上采样生成新的样本。注意在编辑过程中扩散模型仍然遵循先加噪后去噪的模式,但扩散模型的加噪步数远小于初始化噪声的步数。该策略可以减少低信噪比带来的恢复(recover)困难的影响。 三、预测:将新生成的样本和原来的样本标签组成新数据,用于训练骨干(backbone)预测模型。该预测模型一般为时序模型,给定股票历史数据预测未来几天内的股票价格和收益率。 **1) DiffsFormer训练过程 **
DiffsFormer的训练遵循DDPM的训练框架,即加噪过程建模为:
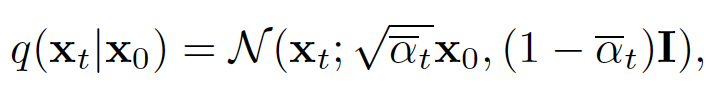
为了加速采样,去噪过程(逆向过程)遵循DDIM框架,可以建模为:
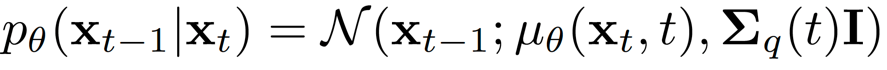
DiffsFormer的优化函数为:
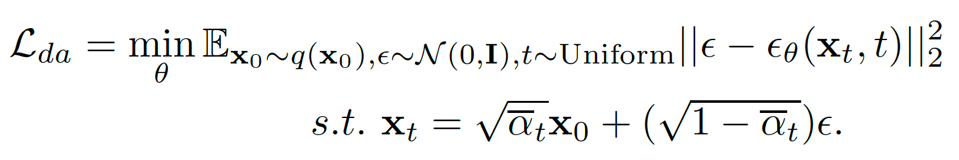
在DiffsFormer训练过程中,会引入条件信号Y和I。我们会以一定概率随机将其替换为默认向量(default embedding),从而实现条件扩散模型与非条件扩散模型的同时训练(Predictor-free Guidance)。 2) DiffsFormer编辑过程
为了调节条件信号的强度,DiffsFormer在采样时,会引入控制强度进行如下改动:
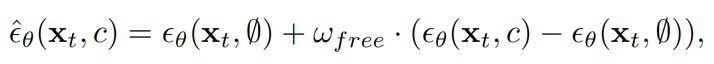
想要生成目标域内的新样本,随机选定目标域内的样本,按上述公式进行T’步加噪和去噪即可。其中T’称为编辑强度,该参数可以用于控制新生成的样本与源域样本和目标域样本的各自相似程度。
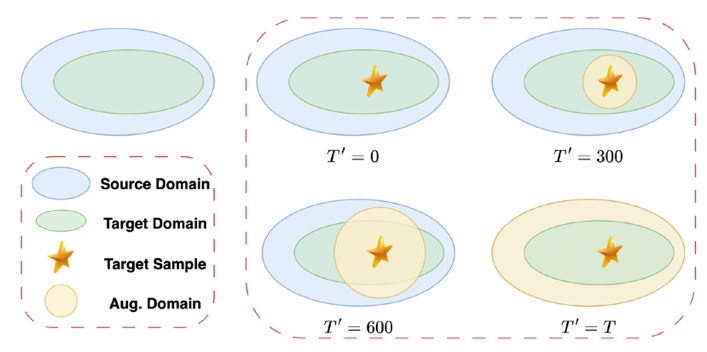
实验结果
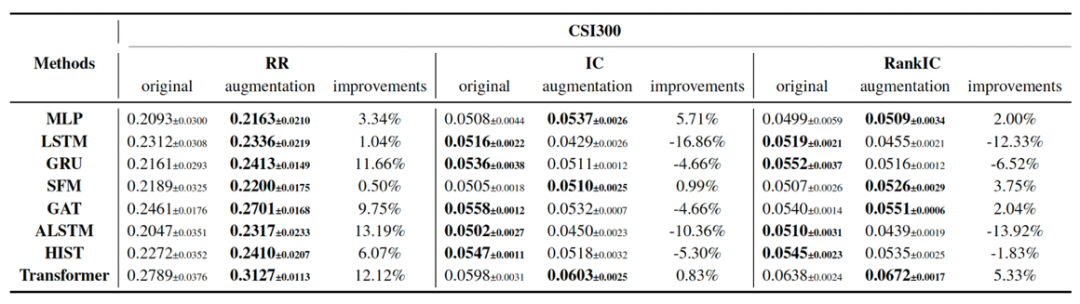
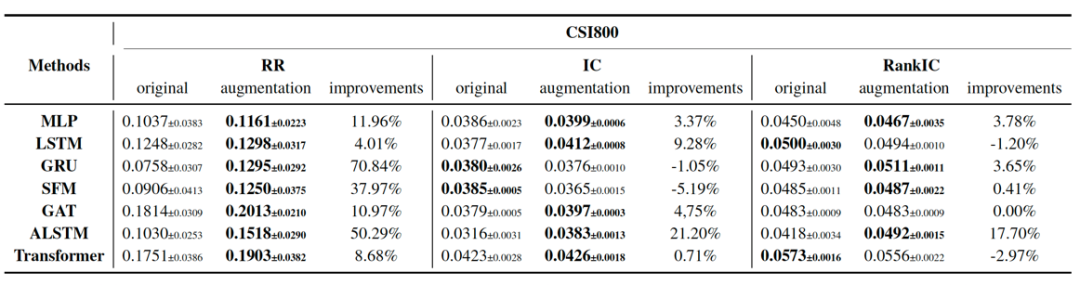
我们在CSI300(沪深300)和CSI800(沪深300+中证500)两个真实数据集下,将DiffsFormer与代表性的股票收益率预测方法进行结合,展示了DiffsFormer即插即用的特点和普适的性质。表现最好的模型Transformer+DiffsFormer能够拿到31+%的超额收益率。值得注意的是收益率有很明显的提升,然而IC和RankIC指标并不如此。我们猜测可能的原因是预测跌的股票易,预测涨的股票难。尾部下跌的股票预测的准确并无太大意义,因此我们在论文中还对股票进行加权,报告了weighted IC的表现。Weighted IC和股票收益率的相关性更强。
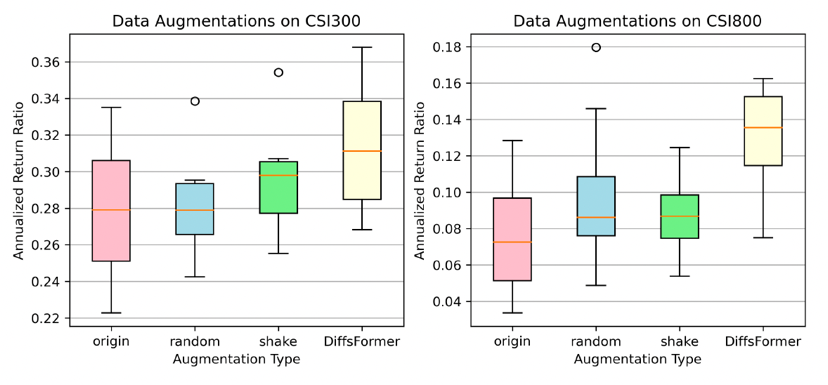
下面是DiffsFormer和其他生成模型的比较结果。可以看出(1)DiffsFormer 的性能优于其他增强方式。(2)数据增强可以增强模型的稳定性,因为数据增强模型的标准差通常比原始模型的标准差小。(3)算法的下界从左到右增加,表明数据增强可以改善最坏情况下的模型性能。
总结与展望
我们发现金融预测任务中数据量不足是一个很大的挑战,因此我们提出DiffsFormer,利用基于Transformer的条件扩散模型,在标签和板块的帮助下生成新的股票序列。 对于未来,我们认为既然“板块”信息作为条件可以提升模型性能,因此可以针对不同板块的股票训练不同的模型,更针对性的做出选择。此外,条件中还可以加入更多的信息,如股票市值等。 DiffsFormer的一个缺陷是扩散模型规模较小。但由于我们的框架中,扩散模型和下游模型是完全解耦的,因此训练一次扩散模型就可以使用较长时间,在有更多硬件资源时,可以仅仅训练一次大规模扩散模型,就以较小的成本和较短的时间达到更好的效果。


